partialDependence
Compute partial dependence
Syntax
Description
pd = partialDependence(RegressionMdl,Vars)pd between the predictor variables
listed in Vars and model predictions. In this syntax, the model
predictions are the responses predicted by using the regression model
RegressionMdl, which contains predictor data. If
RegressionMdl is a model object that does not contain predictor
data (for example, a compact model), you must also provide the input argument
Data.
pd = partialDependence(ClassificationMdl,Vars,Labels)pd between the predictor variables
listed in Vars and the scores for the classes specified in
Labels by using the classification model
ClassificationMdl, which contains predictor data. If
ClassificationMdl is a model object that does not contain predictor
data (for example, a compact model), you must also provide the input argument
Data.
pd = partialDependence(___,Name,Value)"UseParallel","true", the
partialDependence function uses parallel computing to perform the
partial dependence calculations.
Examples
Train a naive Bayes classification model with the fisheriris data set, and compute partial dependence values that show the relationship between the predictor variable and the predicted scores (posterior probabilities) for multiple classes.
Load the fisheriris data set, which contains species (species) and measurements (meas) on sepal length, sepal width, petal length, and petal width for 150 iris specimens. The data set contains 50 specimens from each of three species: setosa, versicolor, and virginica.
load fisheririsTrain a naive Bayes classification model with species as the response and meas as predictors.
Mdl = fitcnb(meas,species,"PredictorNames", ... ["Sepal Length","Sepal Width","Petal Length","Petal Width"]);
Compute partial dependence values on the third predictor variable (petal length) of the scores predicted by Mdl for all three classes of species. Specify the class labels by using the ClassNames property of Mdl.
[pd,x] = partialDependence(Mdl,3,Mdl.ClassNames);
pd contains the partial dependence values for the query points x. You can plot the computed partial dependence values by using plotting functions such as plot and bar. Plot pd against x by using the bar function.
bar(x,pd) legend(Mdl.ClassNames) xlabel("Petal Length") ylabel("Scores") title("Partial Dependence Plot")
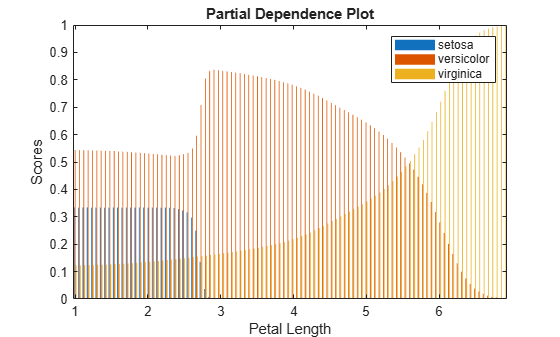
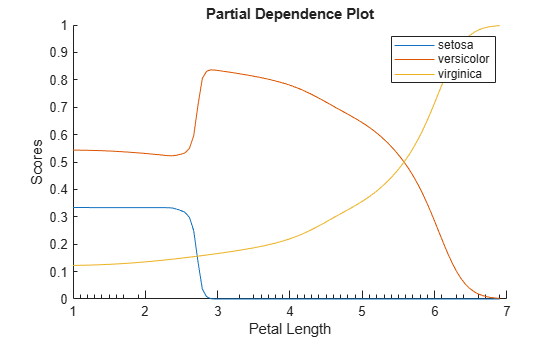
According to this model, the probability of virginica increases with petal length. The probability of setosa is about 0.33, from where petal length is 0 to around 2.5, and then the probability drops to almost 0.
Alternatively, you can use the plotPartialDependence function to compute and plot partial dependence values.
plotPartialDependence(Mdl,3,Mdl.ClassNames)
Train an ensemble of classification models and compute partial dependence values on two variables for multiple classes. Then plot the partial dependence values for each class.
Load the census1994 data set, which contains US yearly salary data, categorized as <=50K or >50K, and several demographic variables.
load census1994Extract a subset of variables to analyze from the table adultdata.
X = adultdata(1:500,["age","workClass","education_num","marital_status","race", ... "sex","capital_gain","capital_loss","hours_per_week","salary"]);
Train a random forest of classification trees by using fitcensemble and specifying Method as "Bag". For reproducibility, use a template of trees created by using templateTree with the Reproducible option.
rng("default") t = templateTree("Reproducible",true); Mdl = fitcensemble(X,"salary","Method","Bag","Learners",t);
Inspect the class names in Mdl.
Mdl.ClassNames
ans = 2×1 categorical
<=50K
>50K
Compute partial dependence values of the scores on the predictors age and education_num for both classes (<=50K and >50K). Specify the number of observations to sample as 100.
[pd,x,y] = partialDependence(Mdl,["age","education_num"],Mdl.ClassNames,"NumObservationsToSample",100);
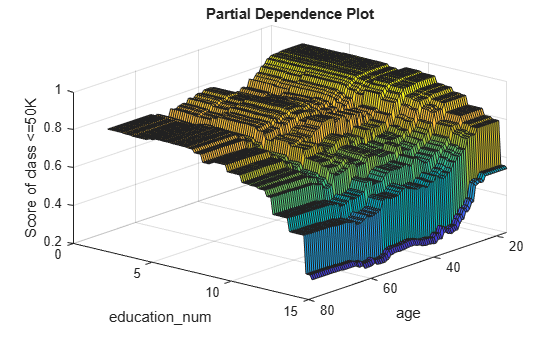
Create a surface plot of the partial dependence values for the first class (<=50K) by using the surf function.
figure surf(x,y,squeeze(pd(1,:,:))) xlabel("age") ylabel("education\_num") zlabel("Score of class <=50K") title("Partial Dependence Plot") view([130 30]) % Modify the viewing angle
Create a surface plot of the partial dependence values for the second class (>50K).
figure surf(x,y,squeeze(pd(2,:,:))) xlabel("age") ylabel("education\_num") zlabel("Score of class >50K") title("Partial Dependence Plot") view([130 30]) % Modify the viewing angle
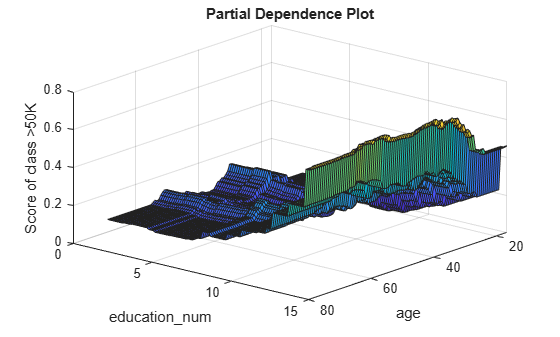
The two plots show different partial dependence patterns depending on the class.
Load the carbig sample data set.
load carbigThe vectors Displacement, Cylinders, and Model_Year contain data for car engine displacement, number of engine cylinders, and year the car was manufactured, respectively.
Fit a multinomial regression model using Displacement and Cylinders as predictor variables and Model_Year as the response.
predvars = [Displacement,Cylinders]; Mdl = fitmnr(predvars,Model_Year,PredictorNames=["Displacement","Cylinders"]);
Create a vector of noisy predictor data from the predictor variables by using the rand function.
Data = predvars(1:10:end,:);
rng("default")
rows = length(Data);
Data = Data + 10*rand([rows,2]);Calculate the partial dependence of the response category probability corresponding to cars manufactured in 1980 on Displacement. Use the noisy predictor data to calculate the partial dependence.
[pd,x,~] = partialDependence(Mdl,"Displacement",80,Data)pd = 1×100
0.0030 0.0031 0.0031 0.0032 0.0032 0.0033 0.0033 0.0033 0.0034 0.0034 0.0035 0.0035 0.0036 0.0036 0.0036 0.0037 0.0037 0.0037 0.0038 0.0038 0.0038 0.0039 0.0039 0.0039 0.0039 0.0039 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0040 0.0039 0.0039 0.0039 0.0039 0.0038 0.0038 0.0038 0.0037 0.0037 0.0036
x = 100×1
73.7850
77.1781
80.5713
83.9644
87.3575
90.7507
94.1438
97.5370
100.9301
104.3232
107.7164
111.1095
114.5027
117.8958
121.2890
⋮
The output shows the calculated values for the partial dependence of the category probability on Displacement. Because Displacement is a continuous variable, the partialDependence function calculates the partial dependence at 100 equally spaced query points x.
Plot the partial dependence using plotPartialDependence.
plotPartialDependence(Mdl,"Displacement",80,Data)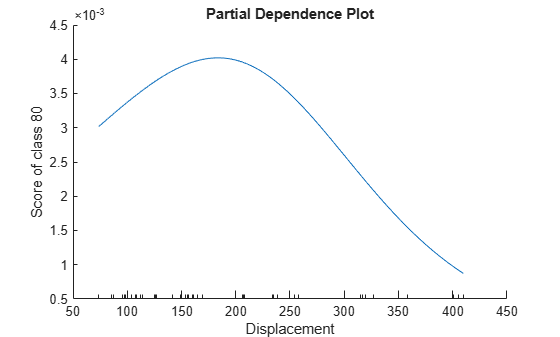
The plot shows that when Displacement increases from approximately 70 to approximately 180, the probability of a car being manufactured in 1980 increases. As Displacement continues to increase, the probability of a car being manufactured in 1980 decreases.
Train a support vector machine (SVM) regression model using the carsmall data set, and compute the partial dependence on two predictor variables. Then, create a figure that shows the partial dependence on the two variables along with the histogram on each variable.
Load the carsmall data set.
load carsmallCreate a table that contains Weight, Cylinders, Displacement, and Horsepower.
Tbl = table(Weight,Cylinders,Displacement,Horsepower);
Train an SVM regression model using the predictor variables in Tbl and the response variable MPG. Use a Gaussian kernel function with an automatic kernel scale.
Mdl = fitrsvm(Tbl,MPG,"ResponseName","MPG", ... "CategoricalPredictors","Cylinders","Standardize",true, ... "KernelFunction","gaussian","KernelScale","auto");
Compute the partial dependence of the predicted response (MPG) on the predictor variables Weight and Horsepower. Specify query points to compute the partial dependence by using the QueryPoints name-value argument.
numPoints = 10; ptX = linspace(min(Weight),max(Weight),numPoints)'; ptY = linspace(min(Horsepower),max(Horsepower),numPoints)'; [pd,x,y] = partialDependence(Mdl,["Weight","Horsepower"],"QueryPoints",[ptX ptY]);
Create a figure that contains a 5-by-5 tiled chart layout. Plot the partial dependence on the two variables by using the imagesc function. Then draw the histogram for each variable by using the histogram function. Specify the edges of the histograms so that the centers of the histogram bars align with the query points. Change the axes properties to align the axes of the plots.
t = tiledlayout(5,5,"TileSpacing","compact"); ax1 = nexttile(2,[4,4]); imagesc(x,y,pd) title("Partial Dependence Plot") colorbar("eastoutside") ax1.YDir = "normal"; ax2 = nexttile(22,[1,4]); dX = diff(ptX(1:2)); edgeX = [ptX-dX/2;ptX(end)+dX]; histogram(Weight,edgeX); xlabel("Weight") xlim(ax1.XLim); ax3 = nexttile(1,[4,1]); dY = diff(ptY(1:2)); edgeY = [ptY-dY/2;ptY(end)+dY]; histogram(Horsepower,edgeY) xlabel("Horsepower") xlim(ax1.YLim); ax3.XDir = "reverse"; camroll(-90)
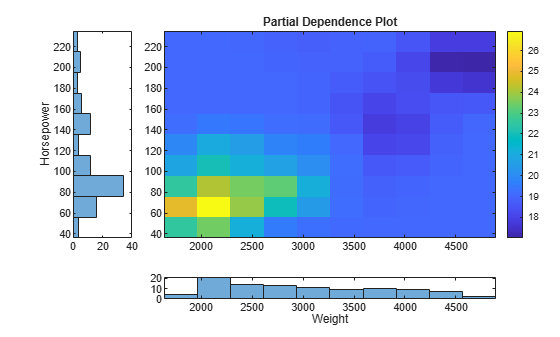
Each element of pd specifies the color for one pixel of the image plot. The histograms aligned with the axes of the image show the distribution of the predictors.
Compute the partial dependence of label scores on predictor variables for a SemiSupervisedSelfTrainingModel object. You cannot pass a SemiSupervisedSelfTrainingModel object directly to the partialDependence function. Instead, define a custom function that returns label scores for the object, and then pass the function to partialDependence.
Randomly generate 15 observations of labeled data, with five observations in each of three classes.
rng("default") % For reproducibility labeledX = [randn(5,2)*0.25 + ones(5,2); randn(5,2)*0.25 - ones(5,2); randn(5,2)*0.5]; Y = [ones(5,1); ones(5,1)*2; ones(5,1)*3];
Randomly generate 300 additional observations of unlabeled data, with 100 observations per class.
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];Fit labels to the unlabeled data by using a semi-supervised self-training method. The function fitsemiself returns a SemiSupervisedSelfTrainingModel object.
Mdl = fitsemiself(labeledX,Y,unlabeledX);
Define the custom function myLabelScores, which returns label scores computed by the predict function of SemiSupervisedSelfTrainingModel; the custom function definition appears at the end of this example.
Compute the partial dependence of the scores for unlabeledX on each variable for all classes. partialDependence accepts a custom model in the form of a function handle. The function represented by the function handle must accept predictor data and return a column vector or matrix with one row for each observation. Specify the custom model as @(X)myLabelScores(Mdl,X) so that the custom function uses the trained model Mdl and accepts predictor data.
[pd1,x1] = partialDependence(@(X)myLabelScores(Mdl,X),1,unlabeledX); [pd2,x2] = partialDependence(@(X)myLabelScores(Mdl,X),2,unlabeledX);
You can plot the computed partial dependence values by using plotting functions such as plot and bar. Alternatively, you can use the plotPartialDependence function to compute and plot partial dependence values.
Create partial dependence plots for the first variable and all classes.
plotPartialDependence(@(X)myLabelScores(Mdl,X),1,unlabeledX) xlabel("1st Variable of unlabeledX") ylabel("Scores") legend("Class 1","Class 2","Class 3")
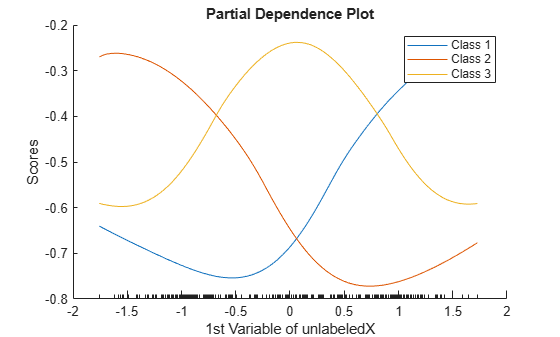
Custom Function myLabelScores
function scores = myLabelScores(Mdl,X) [~,scores] = predict(Mdl,X); end
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
For both a regression model (RegressionMdl) and a classification
model (ClassificationMdl), partialDependence uses a
predict function to predict responses or scores.
partialDependence chooses the proper predict
function according to the model and runs predict with its default settings.
For details about each predict function, see the predict
functions in the following two tables. If the specified model is a tree-based model (not
including a boosted ensemble of trees), then partialDependence uses the
weighted traversal algorithm instead of the predict function. For details,
see Weighted Traversal Algorithm.
Regression Model Object
Classification Model Object
Alternative Functionality
plotPartialDependencecomputes and plots partial dependence values. The function can also create individual conditional expectation (ICE) plots.
References
[2] Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning. New York, NY: Springer New York, 2009.