relieff
Rank importance of predictors using ReliefF or RReliefF algorithm
Description
[
ranks predictors using either the ReliefF or RReliefF algorithm with
idx,weights] = relieff(X,y,k)k nearest neighbors. The input matrix
X contains predictor variables, and the vector
y contains a response vector. The function returns
idx, which contains the indices of the most important
predictors, and weights, which contains the weights of the
predictors.
If y is numeric, relieff performs
RReliefF analysis for regression by default. Otherwise, relieff
performs ReliefF analysis for classification using k nearest
neighbors per class. For more information on ReliefF and RReliefF, see Algorithms.
Examples
Load the sample data.
load fisheririsFind the important predictors using 10 nearest neighbors.
[idx,weights] = relieff(meas,species,10)
idx = 1×4
4 3 1 2
weights = 1×4
0.1399 0.1226 0.3590 0.3754
idx shows the predictor numbers listed according to their ranking. The fourth predictor is the most important, and the second predictor is the least important. weights gives the weight values in the same order as the predictors. The first predictor has a weight of 0.1399, and the fourth predictor has a weight of 0.3754.
Load the sample data.
load ionosphereRank the predictors based on importance using 10 nearest neighbors.
[idx,weights] = relieff(X,Y,10);
Create a bar plot of predictor importance weights.
bar(weights(idx)) xlabel('Predictor rank') ylabel('Predictor importance weight')
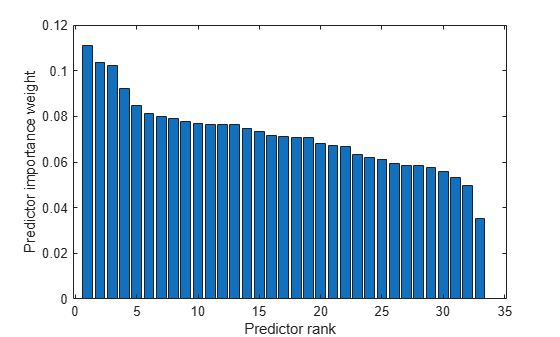
Select the top 5 most important predictors. Find the columns of these predictors in X.
idx(1:5)
ans = 1×5
24 3 8 5 14
The 24th column of X is the most important predictor of Y.
Rank categorical predictors using relieff.
Load the sample data.
load carbigConvert the categorical predictor variables Mfg, Model, and Origin to numerical values, and combine them into an input matrix. Specify the response variable MPG.
X = [grp2idx(Mfg) grp2idx(Model) grp2idx(Origin)]; y = MPG;
Find the ranks and weights of the predictor variables using 10 nearest neighbors and treating the data in X as categorical.
[idx,weights] = relieff(X,y,10,'categoricalx','on')
idx = 1×3
2 3 1
weights = 1×3
-0.0019 0.0501 0.0114
The Model predictor is the most important in predicting MPG. The Mfg variable has a negative weight, indicating it is not a good predictor of MPG.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
Predictor ranks and weights usually depend on
k. If you setkto 1, then the estimates can be unreliable for noisy data. If you setkto a value comparable with the number of observations (rows) inX,relieffcan fail to find important predictors. You can start withk=10and investigate the stability and reliability ofrelieffranks and weights for various values ofk.relieffremoves observations withNaNvalues.
Algorithms
References
[1] Kononenko, I., E. Simec, and M. Robnik-Sikonja. (1997). “Overcoming the myopia of inductive learning algorithms with RELIEFF.” Retrieved from CiteSeerX: https://link.springer.com/article/10.1023/A:1008280620621
[2] Robnik-Sikonja, M., and I. Kononenko. (1997). “An adaptation of Relief for attribute estimation in regression.” Retrieved from CiteSeerX: https://www.semanticscholar.org/paper/An-adaptation-of-Relief-for-attribute-estimation-in-Robnik-Sikonja-Kononenko/9548674b6a3c601c13baa9a383d470067d40b896
[3] Robnik-Sikonja, M., and I. Kononenko. (2003). “Theoretical and empirical analysis of ReliefF and RReliefF.” Machine Learning, 53, 23–69.
Version History
Introduced in R2010b
See Also
fscnca | fsrnca | knnsearch | pdist2 | sequentialfs | plotPartialDependence | fsulaplacian | fscmrmr | fsrmrmr