predict
Class: RegressionLinear
Predict response of linear regression model
Description
YHat = predict(Mdl,X,Name,Value)
Input Arguments
Name-Value Arguments
Output Arguments
Examples
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Train a linear regression model. Reserve 30% of the observations as a holdout sample.
CVMdl = fitrlinear(X,Y,'Holdout',0.3);
Mdl = CVMdl.Trained{1}Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0066
Lambda: 1.4286e-04
Learner: 'svm'
Properties, Methods
CVMdl is a RegressionPartitionedLinear model. It contains the property Trained, which is a 1-by-1 cell array holding a RegressionLinear model that the software trained using the training set.
Extract the training and test data from the partition definition.
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
Predict the training- and test-sample responses.
yHatTrain = predict(Mdl,X(trainIdx,:)); yHatTest = predict(Mdl,X(testIdx,:));
Because there is one regularization strength in Mdl, yHatTrain and yHatTest are numeric vectors.
Predict responses from the best-performing, linear regression model that uses a lasso-penalty and least squares.
Simulate 10000 observations as in Predict Test-Sample Responses.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Create a set of 15 logarithmically-spaced regularization strengths from through .
Lambda = logspace(-5,-1,15);
Cross-validate the models. To increase execution speed, transpose the predictor data and specify that the observations are in columns. Optimize the objective function using SpaRSA.
X = X'; CVMdl = fitrlinear(X,Y,'ObservationsIn','columns','KFold',5,'Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numCLModels = numel(CVMdl.Trained)
numCLModels = 5
CVMdl is a RegressionPartitionedLinear model. Because fitrlinear implements 5-fold cross-validation, CVMdl contains 5 RegressionLinear models that the software trains on each fold.
Display the first trained linear regression model.
Mdl1 = CVMdl.Trained{1}Mdl1 =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×15 double]
Bias: [-0.0049 -0.0049 -0.0049 -0.0049 -0.0049 -0.0048 -0.0044 -0.0037 -0.0030 -0.0031 -0.0033 -0.0036 -0.0041 -0.0051 -0.0071]
Lambda: [1.0000e-05 1.9307e-05 3.7276e-05 7.1969e-05 1.3895e-04 2.6827e-04 5.1795e-04 1.0000e-03 0.0019 0.0037 0.0072 0.0139 0.0268 0.0518 0.1000]
Learner: 'leastsquares'
Properties, Methods
Mdl1 is a RegressionLinear model object. fitrlinear constructed Mdl1 by training on the first four folds. Because Lambda is a sequence of regularization strengths, you can think of Mdl1 as 11 models, one for each regularization strength in Lambda.
Estimate the cross-validated MSE.
mse = kfoldLoss(CVMdl);
Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a regression model. For each regularization strength, train a linear regression model using the entire data set and the same options as when you cross-validated the models. Determine the number of nonzero coefficients per model.
Mdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numNZCoeff = sum(Mdl.Beta~=0);
In the same figure, plot the cross-validated MSE and frequency of nonzero coefficients for each regularization strength. Plot all variables on the log scale.
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(mse),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} MSE') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') hold off
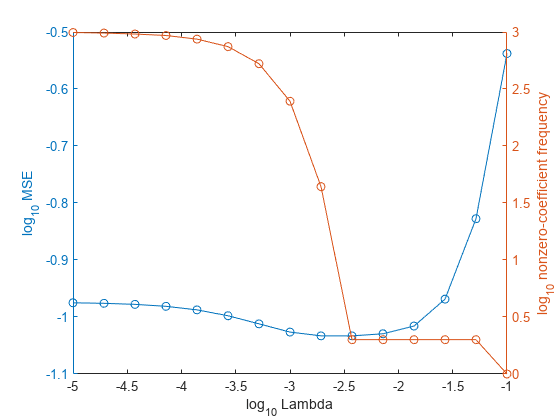
Choose the index of the regularization strength that balances predictor variable sparsity and low MSE (for example, Lambda(10)).
idxFinal = 10;
Extract the model with corresponding to the minimal MSE.
MdlFinal = selectModels(Mdl,idxFinal)
MdlFinal =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0050
Lambda: 0.0037
Learner: 'leastsquares'
Properties, Methods
idxNZCoeff = find(MdlFinal.Beta~=0)
idxNZCoeff = 2×1
100
200
EstCoeff = Mdl.Beta(idxNZCoeff)
EstCoeff = 2×1
1.0051
1.9965
MdlFinal is a RegressionLinear model with one regularization strength. The nonzero coefficients EstCoeff are close to the coefficients that simulated the data.
Simulate 10 new observations, and predict corresponding responses using the best-performing model.
XNew = sprandn(d,10,nz); YHat = predict(MdlFinal,XNew,'ObservationsIn','columns');
Alternative Functionality
Simulink Block
To integrate the prediction of a linear regression model into Simulink®, you can use the RegressionLinear
Predict block in the Statistics and Machine Learning Toolbox™ library or a MATLAB® Function block with the predict function. For
examples, see Predict Responses Using RegressionLinear Predict Block and Predict Class Labels Using MATLAB Function Block.
When deciding which approach to use, consider the following:
If you use the Statistics and Machine Learning Toolbox library block, you can use the Fixed-Point Tool (Fixed-Point Designer) to convert a floating-point model to fixed point.
Support for variable-size arrays must be enabled for a MATLAB Function block with the
predictfunction.If you use a MATLAB Function block, you can use MATLAB functions for preprocessing or post-processing before or after predictions in the same MATLAB Function block.