ClassificationSVM
Support vector machine (SVM) for one-class and binary classification
Description
ClassificationSVM is a support vector machine (SVM) classifier for one-class and two-class learning. Trained ClassificationSVM classifiers store training data, parameter values, prior probabilities, support vectors, and algorithmic implementation information. Use these classifiers to perform tasks such as fitting a score-to-posterior-probability transformation function (see fitPosterior) and predicting labels for new data (see predict).
Creation
Create a ClassificationSVM object by using fitcsvm.
Properties
Object Functions
compact | Reduce size of machine learning model |
compareHoldout | Compare accuracies of two classification models using new data |
crossval | Cross-validate machine learning model |
discardSupportVectors | Discard support vectors for linear support vector machine (SVM) classifier |
edge | Find classification edge for support vector machine (SVM) classifier |
fitPosterior | Fit posterior probabilities for support vector machine (SVM) classifier |
gather | Gather properties of Statistics and Machine Learning Toolbox object from GPU |
incrementalLearner | Convert binary classification support vector machine (SVM) model to incremental learner |
lime | Local interpretable model-agnostic explanations (LIME) |
loss | Find classification error for support vector machine (SVM) classifier |
margin | Find classification margins for support vector machine (SVM) classifier |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict | Classify observations using support vector machine (SVM) classifier |
resubEdge | Resubstitution classification edge |
resubLoss | Resubstitution classification loss |
resubMargin | Resubstitution classification margin |
resubPredict | Classify training data using trained classifier |
resume | Resume training support vector machine (SVM) classifier |
shapley | Shapley values |
testckfold | Compare accuracies of two classification models by repeated cross-validation |
Examples
Load Fisher's iris data set. Remove the sepal lengths and widths and all observed setosa irises.
load fisheriris inds = ~strcmp(species,'setosa'); X = meas(inds,3:4); y = species(inds);
Train an SVM classifier using the processed data set.
SVMModel = fitcsvm(X,y)
SVMModel =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 100
Alpha: [24×1 double]
Bias: -14.4149
KernelParameters: [1×1 struct]
BoxConstraints: [100×1 double]
ConvergenceInfo: [1×1 struct]
IsSupportVector: [100×1 logical]
Solver: 'SMO'
Properties, Methods
SVMModel is a trained ClassificationSVM classifier. Display the properties of SVMModel. For example, to determine the class order, use dot notation.
classOrder = SVMModel.ClassNames
classOrder = 2×1 cell
{'versicolor'}
{'virginica' }
The first class ('versicolor') is the negative class, and the second ('virginica') is the positive class. You can change the class order during training by using the 'ClassNames' name-value pair argument.
Plot a scatter diagram of the data and circle the support vectors.
sv = SVMModel.SupportVectors; figure gscatter(X(:,1),X(:,2),y) hold on plot(sv(:,1),sv(:,2),'ko','MarkerSize',10) legend('versicolor','virginica','Support Vector') hold off
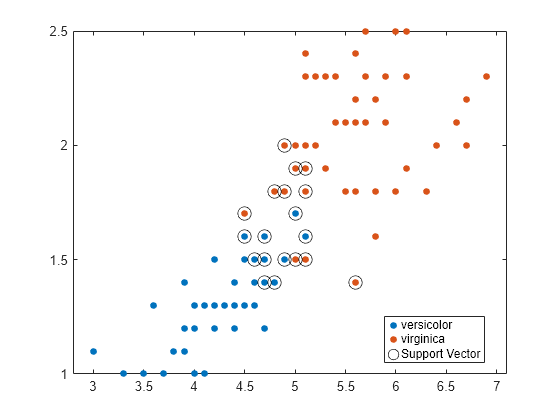
The support vectors are observations that occur on or beyond their estimated class boundaries.
You can adjust the boundaries (and, therefore, the number of support vectors) by setting a box constraint during training using the 'BoxConstraint' name-value pair argument.
Load the ionosphere data set.
load ionosphereTrain and cross-validate an SVM classifier. Standardize the predictor data and specify the order of the classes.
rng(1); % For reproducibility CVSVMModel = fitcsvm(X,Y,'Standardize',true,... 'ClassNames',{'b','g'},'CrossVal','on')
CVSVMModel =
ClassificationPartitionedModel
CrossValidatedModel: 'SVM'
PredictorNames: {'x1' 'x2' 'x3' 'x4' 'x5' 'x6' 'x7' 'x8' 'x9' 'x10' 'x11' 'x12' 'x13' 'x14' 'x15' 'x16' 'x17' 'x18' 'x19' 'x20' 'x21' 'x22' 'x23' 'x24' 'x25' 'x26' 'x27' 'x28' 'x29' 'x30' 'x31' 'x32' 'x33' 'x34'}
ResponseName: 'Y'
NumObservations: 351
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Properties, Methods
CVSVMModel is a ClassificationPartitionedModel cross-validated SVM classifier. By default, the software implements 10-fold cross-validation.
Alternatively, you can cross-validate a trained ClassificationSVM classifier by passing it to crossval.
Inspect one of the trained folds using dot notation.
CVSVMModel.Trained{1}ans =
CompactClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Alpha: [78×1 double]
Bias: -0.2209
KernelParameters: [1×1 struct]
Mu: [0.8888 0 0.6320 0.0406 0.5931 0.1205 0.5361 0.1286 0.5083 0.1879 0.4779 0.1567 0.3924 0.0875 0.3360 0.0789 0.3839 9.6066e-05 0.3562 -0.0308 0.3398 -0.0073 0.3590 -0.0628 0.4064 -0.0664 0.5535 -0.0749 0.3835 … ] (1×34 double)
Sigma: [0.3149 0 0.5033 0.4441 0.5255 0.4663 0.4987 0.5205 0.5040 0.4780 0.5649 0.4896 0.6293 0.4924 0.6606 0.4535 0.6133 0.4878 0.6250 0.5140 0.6075 0.5150 0.6068 0.5222 0.5729 0.5103 0.5061 0.5478 0.5712 0.5032 … ] (1×34 double)
SupportVectors: [78×34 double]
SupportVectorLabels: [78×1 double]
Properties, Methods
Each fold is a CompactClassificationSVM classifier trained on 90% of the data.
Estimate the generalization error.
genError = kfoldLoss(CVSVMModel)
genError = 0.1168
On average, the generalization error is approximately 12%.
More About
Algorithms
For the mathematical formulation of the SVM binary classification algorithm, see Support Vector Machines for Binary Classification and Understanding Support Vector Machines.
NaN,<undefined>, empty character vector (''), empty string (""), and<missing>values indicate missing values.fitcsvmremoves entire rows of data corresponding to a missing response. When computing total weights (see the next bullets),fitcsvmignores any weight corresponding to an observation with at least one missing predictor. This action can lead to unbalanced prior probabilities in balanced-class problems. Consequently, observation box constraints might not equalBoxConstraint.If you specify the
Cost,Prior, andWeightsname-value arguments, the output model object stores the specified values in theCost,Prior, andWproperties, respectively. TheCostproperty stores the user-specified cost matrix (C) without modification. ThePriorandWproperties store the prior probabilities and observation weights, respectively, after normalization. For model training, the software updates the prior probabilities and observation weights to incorporate the penalties described in the cost matrix. For details, see Misclassification Cost Matrix, Prior Probabilities, and Observation Weights.Note that the
CostandPriorname-value arguments are used for two-class learning. For one-class learning, theCostandPriorproperties store0and1, respectively.For two-class learning,
fitcsvmassigns a box constraint to each observation in the training data. The formula for the box constraint of observation j iswhere C0 is the initial box constraint (see the
BoxConstraintname-value argument), and wj* is the observation weight adjusted byCostandPriorfor observation j. For details about the observation weights, see Adjust Prior Probabilities and Observation Weights for Misclassification Cost Matrix.If you specify
Standardizeastrueand set theCost,Prior, orWeightsname-value argument, thenfitcsvmstandardizes the predictors using their corresponding weighted means and weighted standard deviations. That is,fitcsvmstandardizes predictor j (xj) usingwhere xjk is observation k (row) of predictor j (column), and
Assume that
pis the proportion of outliers that you expect in the training data, and that you set'OutlierFraction',p.For one-class learning, the software trains the bias term such that 100
p% of the observations in the training data have negative scores.The software implements robust learning for two-class learning. In other words, the software attempts to remove 100
p% of the observations when the optimization algorithm converges. The removed observations correspond to gradients that are large in magnitude.
If your predictor data contains categorical variables, then the software generally uses full dummy encoding for these variables. The software creates one dummy variable for each level of each categorical variable.
The
PredictorNamesproperty stores one element for each of the original predictor variable names. For example, assume that there are three predictors, one of which is a categorical variable with three levels. ThenPredictorNamesis a 1-by-3 cell array of character vectors containing the original names of the predictor variables.The
ExpandedPredictorNamesproperty stores one element for each of the predictor variables, including the dummy variables. For example, assume that there are three predictors, one of which is a categorical variable with three levels. ThenExpandedPredictorNamesis a 1-by-5 cell array of character vectors containing the names of the predictor variables and the new dummy variables.Similarly, the
Betaproperty stores one beta coefficient for each predictor, including the dummy variables.The
SupportVectorsproperty stores the predictor values for the support vectors, including the dummy variables. For example, assume that there are m support vectors and three predictors, one of which is a categorical variable with three levels. ThenSupportVectorsis an n-by-5 matrix.The
Xproperty stores the training data as originally input and does not include the dummy variables. When the input is a table,Xcontains only the columns used as predictors.
For predictors specified in a table, if any of the variables contain ordered (ordinal) categories, the software uses ordinal encoding for these variables.
For a variable with k ordered levels, the software creates k – 1 dummy variables. The jth dummy variable is –1 for levels up to j, and +1 for levels j + 1 through k.
The names of the dummy variables stored in the
ExpandedPredictorNamesproperty indicate the first level with the value +1. The software stores k – 1 additional predictor names for the dummy variables, including the names of levels 2, 3, ..., k.
All solvers implement L1 soft-margin minimization.
For one-class learning, the software estimates the Lagrange multipliers, α1,...,αn, such that
References
[2] Scholkopf, B., J. C. Platt, J. C. Shawe-Taylor, A. J. Smola, and R. C. Williamson. “Estimating the Support of a High-Dimensional Distribution.” Neural Comput., Vol. 13, Number 7, 2001, pp. 1443–1471.