A machine learning model is a program that is used to make predictions for a given data set. A machine learning model is built by a supervised machine learning algorithm and uses computational methods to “learn” information directly from data without relying on a predetermined equation. More specifically, the algorithm takes a known set of input data and known responses to the data (output) and trains the machine learning model to generate reasonable predictions for the response to new data.
Types of Machine Learning Models
There are two main types of machine learning models: machine learning classification (where the response belongs to a set of classes) and machine learning regression (where the response is continuous).
Choosing the right machine learning model can seem overwhelming—there are dozens of classification and regression models, and each takes a different approach to learning. This process requires evaluating tradeoffs, such as model speed, accuracy, interpretability, and complexity, and can involve trial and error.
The following is an overview of machine learning classification and regression machine learning models to help you get started.

Machine learning models for classification and regression with MATLAB.
Popular Machine Learning Models for Classification or Regression
Machine Learning Model |
How Machine Learning Model Works |
Machine Learning Model Representation |
|---|---|---|
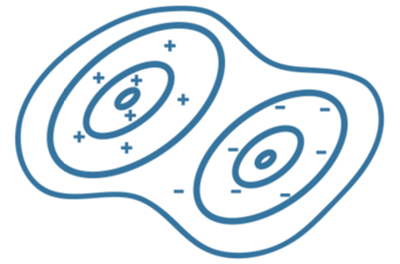
An SVM classifies data by finding the linear decision boundary (hyperplane) that separates data points of one class from data points of the other class. The best hyperplane for an SVM has the largest margin between the two classes when the data is linearly separable. If the data is not linearly separable, a loss function penalizes points on the wrong side of the hyperplane. SVMs sometimes use a kernel transformation to project nonlinearly separable data into higher dimensions where a linear decision boundary can be found. SVM regression algorithms work like SVM classification algorithms, but the regression algorithms are modified to predict continuous responses. They find a model that deviates from the measured data with minimal parameter values to reduce sensitivity to errors. |
Classification
|
|
Regression
|
||
Decision Tree |
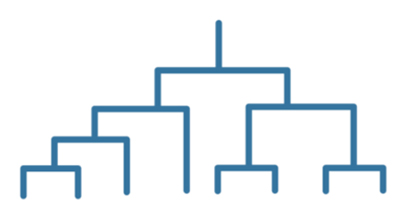
A decision tree lets you predict responses to data by following the decisions in the tree from the root (beginning) down to a leaf node. A tree consists of branching conditions where the value of a predictor is compared to a trained weight. The number of branches and the values of weights are determined in the training process. Additional modification, or pruning, may be used to simplify the model. |
|
Ensemble Trees |
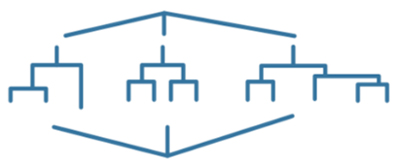
In ensemble methods, several weaker decision trees are combined into a stronger ensemble. A bagged decision tree consists of trees that are trained independently on bootstrap samples of the input data. Boosting involves iteratively adding and adjusting the weight of weak learners. There is an emphasis on misclassified observations or fitting new learners to minimize the mean-squared error between the observed response and the aggregated prediction of all previously grown learners. |
|
Generalized Additive Model (GAM) |
GAM models explain class scores or response variables using a sum of univariate and bivariate shape functions of predictors. These models use a shape function, such as a boosted tree, for each predictor and, optionally, each pair of predictors. The shape function can capture a nonlinear relation between predictors and predictions. |
|
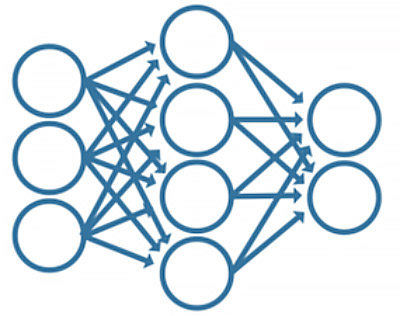
Inspired by the human brain, a neural network consists of interconnected nodes or neurons in a layered structured that relate the inputs to the desired outputs. The machine learning model is trained by iteratively modifying the strengths of the connections so that given inputs map to the correct response. The neurons between the input and output layers of a neural network are referred to as hidden layers. Shallow neural networks typically have few hidden layers. Deep neural networks have more hidden layers than shallow neural networks. They can have hundreds of hidden layers. Neural networks can be configured to solve classification or regression problems by placing a classification or regression output layer at the end of the network. For deep learning tasks, such as image recognition, you can use pretrained deep learning models. Common types of deep neural network are CNNs and RNNs. |
|



Popular Machine Learning Models for Classification
Machine Learning Model |
How Machine Learning Model Works |
Machine Learning Model Representation |
|---|---|---|
Naive Bayes |
A naive Bayes classifier assumes that the presence of a feature in a class is independent of other features. It classifies new data based on the highest probability of it belonging to a particular class. This probability is determined by the probabilities of each feature. |
|
k-Nearest Neighbor (KNN) |
KNN is a type of machine learning model that categorizes objects based on the classes of their nearest neighbors in the data set. KNN predictions assume that objects near each other are similar. Distance metrics, such as Euclidean, city block, cosine, and Chebyshev, are used to find the nearest neighbor. |
|
Discriminant Analysis |
Discriminant analysis classifies data by finding linear combinations of features. The analysis assumes that different classes generate data based on Gaussian distributions. Training the machine learning model involves finding the parameters of a Gaussian distribution for each class. Boundaries, either linear or quadratic, are calculated based on these parameters. These boundaries are used to classify new data. |
|

Popular Machine Learning Models for Regression
Machine Learning Model |
How Machine Learning Model Works |
Machine Learning Model Representation |
|---|---|---|
Linear regression is a statistical modeling technique used to describe a continuous response variable as a linear function of one or more predictor variables. Because linear regression models are simple to interpret and easy to train, they are often the first models to try when working with a new data set. |
|
|
Nonlinear regression is a statistical modeling technique that helps describe nonlinear relationships in experimental data. These models are generally assumed to be parametric, described as nonlinear equations. Nonlinear refers to a fit function that is a nonlinear function of the parameters. For example, if the fitting parameters are b0, b1, and b2: the equation y = b0+b1x+b2x2 is a linear function of the fitting parameters, whereas y = (b0xb1)/(x+b2) is a nonlinear function of the fitting parameters. |
|
|
Generalized Linear Model |
A generalized linear model (GLM) is a special case of nonlinear models that uses linear methods. The inputs are transformed by a nonlinear link function such as a logarithm or logit function. The linear combination of transformed inputs is solved using a linear best fit. The logistic regression machine learning model is an example of a GLM. |
|
Gaussian Process Regression (GPR) |
GPR models are nonparametric machine learning models used for predicting the value of a continuous response variable. The response variable is modeled as a random Gaussian process, using covariances with each input variable. The machine learning model also models the uncertainty of the response. These models are widely used in spatial analysis for interpolation in the presence of uncertainty. GPR is also referred to as Kriging. |
|

Machine Learning Models with MATLAB
Using MATLAB® with Statistics and Machine Learning Toolbox™, you can train many types of machine learning models for classification and regression. The following tables list MATLAB functions that create popular machine learning models and documentation topics, which describe how the machine learning models work. With MATLAB, you can create more machine learning models than the ones listed here.
Machine Learning Models for Classification
Machine Learning Model |
MATLAB Function that Creates Machine Learning Model |
How Machine Learning Model Works in MATLAB |
|---|---|---|
SVM |
fitcsvm |
|
Naive Bayes |
fitcnb |
|
KNN |
fitcknn |
|
Decision Tree |
fitctree |
|
Decision Tree Ensemble |
fitcensemble |
|
Discriminant Analysis |
fitcdiscr |
|
GAM |
fitcgam |
|
Shallow Neural Network |
fitcnet |
|
Deep Neural Network |
trainNetwork |
Machine Learning Models for Regression
Machine Learning Model |
MATLAB Function that Creates Machine Learning Model |
How Machine Learning Model Works in MATLAB |
|---|---|---|
Linear Regression |
fitlm |
|
Nonlinear Regression |
fitnlm |
|
GPR |
fitrgp |
|
SVM |
fitrsvm |
|
Generalized Linear Model |
fitglm |
|
Tree |
fitrtree |
|
Regression Tree Ensemble |
fitrensemble |
|
GAM |
fitrgam |
|
Shallow Neural Network |
fitrnet |
|
Deep Neural Network |
trainNetwork |
MATLAB provides low-code apps (Classification Learner and Regression Learner) for designing, tuning, assessing, and optimizing machine learning models.
Classification Learner App

Regression Learner App

Specialized apps for interactively exploring data, selecting features, and training, comparing, and assessing machine learning models.
With MATLAB, you can automate the process of building optimized machine learning models. Using autoML techniques, you can streamline data exploration and preprocessing, feature extraction and selection, machine learning model selection and tuning, and the preparation of a machine learning model for deployment.
Integrate Machine Learning Models into System
Using MATLAB and Simulink® with Statistics and Machine Learning Toolbox, you can integrate machine learning models into the design and simulation of complex AI-driven systems, such as a reduced-order model of a vehicle engine.

Integrate a machine learning model into a Simulink system by using a dedicated block.
For each machine learning model, a dedicated Simulink block exists. The following table lists Simulink blocks and relevant examples for integrating classification and regression machine learning models into system designs.
Simulink Blocks for Classification Models
| Machine Learning Model | Simulink Block for Machine Learning Model |
How To Integrate Machine Learning Model in Simulink System |
|---|---|---|
SVM |
||
KNN |
||
Decision Tree |
||
Decision Tree Ensemble |
||
Shallow Neural Network |
||
Deep Neural Network |
Simulink Blocks for Regression Models
| Machine Learning Model | Simulink Block for Machine Learning Model |
How To Integrate Machine Learning Model in Simulink System |
|---|---|---|
Linear Regression |
||
GPR |
||
SVM |
||
Regression Tree |
||
Regression Tree Ensemble |
||
Shallow Neural Network |
||
Deep Neural Network |
Learn More About Machine Learning Models



A machine learning model is a program that makes predictions for a given data set by using computational methods to learn information directly from data without relying on a predetermined equation.
The two main types are classification models, where the response belongs to a set of classes, and regression models, where the response is continuous.
An SVM classifies data by finding the linear decision boundary that separates data points of different classes, with the best hyperplane having the largest margin between classes. An SVM can also be used for regression tasks.
A decision tree predicts responses by following branching conditions from the root to a leaf node, where predictor values are compared with trained weights determined during the training process.
Ensemble trees combine several weaker decision trees into a stronger model, either through bagging (training trees independently on bootstrap samples) or boosting (iteratively adding and adjusting weak learners).
A neural network consists of interconnected nodes in a layered structure that relates inputs to outputs. It is trained by iteratively modifying connection strengths. Deep neural networks have many hidden layers and can solve classification or regression problems.
KNN categorizes objects based on the classes of their nearest neighbors in the data set, using distance metrics like Euclidean or cosine to find the nearest neighbor.
MATLAB provides functions for training classification and regression models, low-code apps like Classification Learner and Regression Learner for designing and optimizing models, and autoML techniques to streamline the entire workflow.
Yes, each machine learning model has a dedicated Simulink block that allows integration into system designs, enabling simulation of complex AI-driven systems.