fitcdiscr
Fit discriminant analysis classifier
Syntax
Description
Mdl = fitcdiscr(Tbl,ResponseVarName)Tbl and output (response or labels) contained in
ResponseVarName.
Mdl = fitcdiscr(___,Name=Value)
[
also returns Mdl,AggregateOptimizationResults] = fitcdiscr(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments.
You must also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this
syntax to optimize on compact model size instead of cross-validation loss, and
to perform a set of multiple optimization problems that have the same options
but different constraint bounds.
Note
For a list of supported syntaxes when the input variables are tall arrays, see Tall Arrays.
Examples
Load Fisher's iris data set.
load fisheririsTrain a discriminant analysis model using the entire data set.
Mdl = fitcdiscr(meas,species)
Mdl =
ClassificationDiscriminant
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DiscrimType: 'linear'
Mu: [3×4 double]
Coeffs: [3×3 struct]
Properties, Methods
Mdl is a ClassificationDiscriminant model. To access its properties, use dot notation. For example, display the group means for each predictor.
Mdl.Mu
ans = 3×4
5.0060 3.4280 1.4620 0.2460
5.9360 2.7700 4.2600 1.3260
6.5880 2.9740 5.5520 2.0260
To predict labels for new observations, pass Mdl and predictor data to predict.
This example shows how to optimize hyperparameters automatically using fitcdiscr. The example uses Fisher's iris data.
Load the data.
load fisheririsFind hyperparameters that minimize five-fold cross-validation loss by using automatic hyperparameter optimization.
For reproducibility, set the random seed and use the 'expected-improvement-plus' acquisition function.
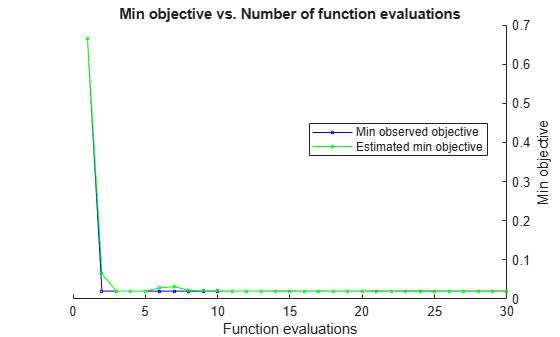
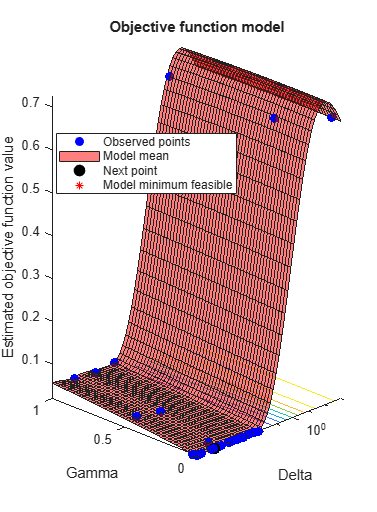
rng(1) Mdl = fitcdiscr(meas,species,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',... struct('AcquisitionFunctionName','expected-improvement-plus'))
|=====================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Delta | Gamma |
| | result | | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 1 | Best | 0.66667 | 0.39142 | 0.66667 | 0.66667 | 13.261 | 0.25218 |
| 2 | Best | 0.02 | 0.22086 | 0.02 | 0.064227 | 2.7404e-05 | 0.073264 |
| 3 | Accept | 0.04 | 0.12791 | 0.02 | 0.020084 | 3.2455e-06 | 0.46974 |
| 4 | Accept | 0.66667 | 0.066479 | 0.02 | 0.020118 | 14.879 | 0.98622 |
| 5 | Accept | 0.046667 | 0.043152 | 0.02 | 0.019907 | 0.00031449 | 0.97362 |
| 6 | Accept | 0.04 | 0.040999 | 0.02 | 0.028438 | 4.5092e-05 | 0.43616 |
| 7 | Accept | 0.046667 | 0.026823 | 0.02 | 0.031424 | 2.0973e-05 | 0.9942 |
| 8 | Accept | 0.02 | 0.037954 | 0.02 | 0.022424 | 1.0554e-06 | 0.0024286 |
| 9 | Accept | 0.02 | 0.031919 | 0.02 | 0.021105 | 1.1232e-06 | 0.00014039 |
| 10 | Accept | 0.02 | 0.028462 | 0.02 | 0.020948 | 0.00011837 | 0.0032994 |
| 11 | Accept | 0.02 | 0.045765 | 0.02 | 0.020172 | 1.0292e-06 | 0.027725 |
| 12 | Accept | 0.02 | 0.038594 | 0.02 | 0.020105 | 9.7792e-05 | 0.0022817 |
| 13 | Accept | 0.02 | 0.026919 | 0.02 | 0.020038 | 0.00036014 | 0.0015136 |
| 14 | Accept | 0.02 | 0.029418 | 0.02 | 0.019597 | 0.00021059 | 0.0044789 |
| 15 | Accept | 0.02 | 0.034802 | 0.02 | 0.019461 | 1.1911e-05 | 0.0010135 |
| 16 | Accept | 0.02 | 0.02442 | 0.02 | 0.01993 | 0.0017896 | 0.00071115 |
| 17 | Accept | 0.02 | 0.025781 | 0.02 | 0.019551 | 0.00073745 | 0.0066899 |
| 18 | Accept | 0.02 | 0.040556 | 0.02 | 0.019776 | 0.00079304 | 0.00011509 |
| 19 | Accept | 0.02 | 0.027135 | 0.02 | 0.019678 | 0.007292 | 0.0007911 |
| 20 | Accept | 0.046667 | 0.028511 | 0.02 | 0.019785 | 0.0074408 | 0.99945 |
|=====================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Delta | Gamma |
| | result | | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 21 | Accept | 0.02 | 0.025091 | 0.02 | 0.019043 | 0.0036004 | 0.0024547 |
| 22 | Accept | 0.02 | 0.02548 | 0.02 | 0.019755 | 2.5238e-05 | 0.0015542 |
| 23 | Accept | 0.02 | 0.025436 | 0.02 | 0.0191 | 1.5478e-05 | 0.0026899 |
| 24 | Accept | 0.02 | 0.026248 | 0.02 | 0.019081 | 0.0040557 | 0.00046815 |
| 25 | Accept | 0.02 | 0.040511 | 0.02 | 0.019333 | 2.959e-05 | 0.0011358 |
| 26 | Accept | 0.02 | 0.03883 | 0.02 | 0.019369 | 2.3111e-06 | 0.0029205 |
| 27 | Accept | 0.02 | 0.083116 | 0.02 | 0.019455 | 3.8898e-05 | 0.0011665 |
| 28 | Accept | 0.02 | 0.027187 | 0.02 | 0.019449 | 0.0035925 | 0.0020278 |
| 29 | Accept | 0.66667 | 0.027722 | 0.02 | 0.019479 | 998.93 | 0.064276 |
| 30 | Accept | 0.02 | 0.024449 | 0.02 | 0.01947 | 8.1557e-06 | 0.0008004 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 17.608 seconds
Total objective function evaluation time: 1.682
Best observed feasible point:
Delta Gamma
__________ ________
2.7404e-05 0.073264
Observed objective function value = 0.02
Estimated objective function value = 0.022693
Function evaluation time = 0.22086
Best estimated feasible point (according to models):
Delta Gamma
__________ _________
2.5238e-05 0.0015542
Estimated objective function value = 0.01947
Estimated function evaluation time = 0.03347
Mdl =
ClassificationDiscriminant
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
DiscrimType: 'linear'
Mu: [3×4 double]
Coeffs: [3×3 struct]
Properties, Methods
The fit achieves about 2% loss for the default 5-fold cross validation.
This example shows how to optimize hyperparameters of a discriminant analysis model automatically using a tall array. The sample data set airlinesmall.csv is a large data set that contains a tabular file of airline flight data. This example creates a tall table containing the data and uses it to run the optimization procedure.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (default if you have Parallel Computing Toolbox™) or the local MATLAB session. If you want to run the example using the local MATLAB session when you have Parallel Computing Toolbox, you can change the global execution environment by using the mapreducer function.
Create a datastore that references the folder location with the data. Select a subset of the variables to work with, and treat NA values as missing data so that datastore replaces them with NaN values. Create a tall table that contains the data in the datastore.
ds = datastore("airlinesmall.csv"); ds.SelectedVariableNames = ["Month","DayofMonth","DayOfWeek", ... "DepTime","ArrDelay","Distance","DepDelay"]; ds.TreatAsMissing = "NA"; tt = tall(ds) % Tall table
Starting parallel pool (parpool) using the 'Processes' profile ...
06-Nov-2025 13:50:13: Job Queued. Waiting for parallel pool job with ID 1 to start ...
06-Nov-2025 13:51:13: Job Queued. Waiting for parallel pool job with ID 1 to start ...
06-Nov-2025 13:52:13: Job Queued. Waiting for parallel pool job with ID 1 to start ...
06-Nov-2025 13:53:14: Job Queued. Waiting for parallel pool job with ID 1 to start ...
Connected to parallel pool with 6 workers.
tt =
M×7 tall table
Month DayofMonth DayOfWeek DepTime ArrDelay Distance DepDelay
_____ __________ _________ _______ ________ ________ ________
10 21 3 642 8 308 12
10 26 1 1021 8 296 1
10 23 5 2055 21 480 20
10 23 5 1332 13 296 12
10 22 4 629 4 373 -1
10 28 3 1446 59 308 63
10 8 4 928 3 447 -2
10 10 6 859 11 954 -1
: : : : : : :
: : : : : : :
Determine the flights that are late by 10 minutes or more by defining a logical variable that is true for a late flight. This variable contains the class labels. A preview of this variable includes the first few rows.
Y = tt.DepDelay > 10 % Class labelsY = M×1 tall logical array 1 0 1 1 0 1 0 0 : :
Create a tall array for the predictor data.
X = tt{:,1:end-1} % Predictor dataX =
M×6 tall double matrix
10 21 3 642 8 308
10 26 1 1021 8 296
10 23 5 2055 21 480
10 23 5 1332 13 296
10 22 4 629 4 373
10 28 3 1446 59 308
10 8 4 928 3 447
10 10 6 859 11 954
: : : : : :
: : : : : :
Remove rows in X and Y that contain missing data.
R = rmmissing([X Y]); % Data with missing entries removed
X = R(:,1:end-1);
Y = R(:,end); Standardize the predictor variables.
Z = zscore(X);
Optimize hyperparameters automatically using the OptimizeHyperparameters name-value argument. Note that when you use tall arrays, DiscrimType is the only hyperparameter you can optimize, regardless of whether you specify "auto" or "all". Find the optimal DiscrimType value that minimizes holdout cross-validation loss. For reproducibility, use the "expected-improvement-plus" acquisition function and set the seeds of the random number generators using rng and tallrng. The results can vary depending on the number of workers and the execution environment for the tall arrays. For details, see Control Where Your Code Runs.
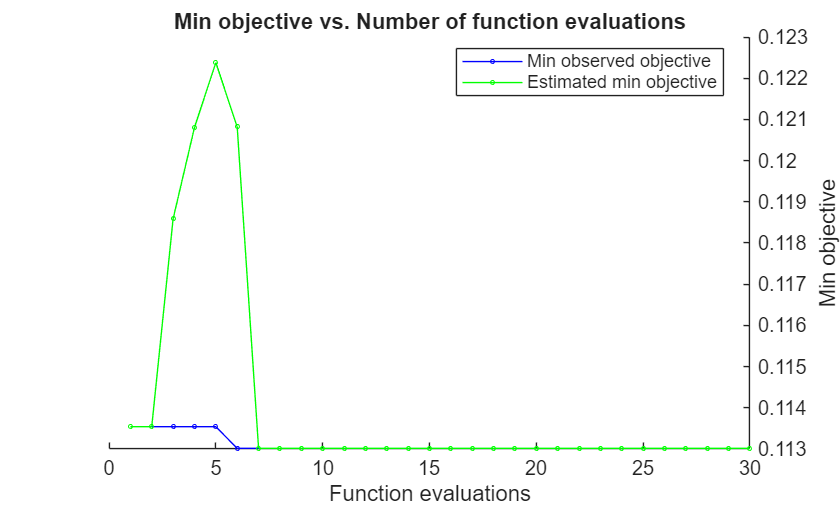
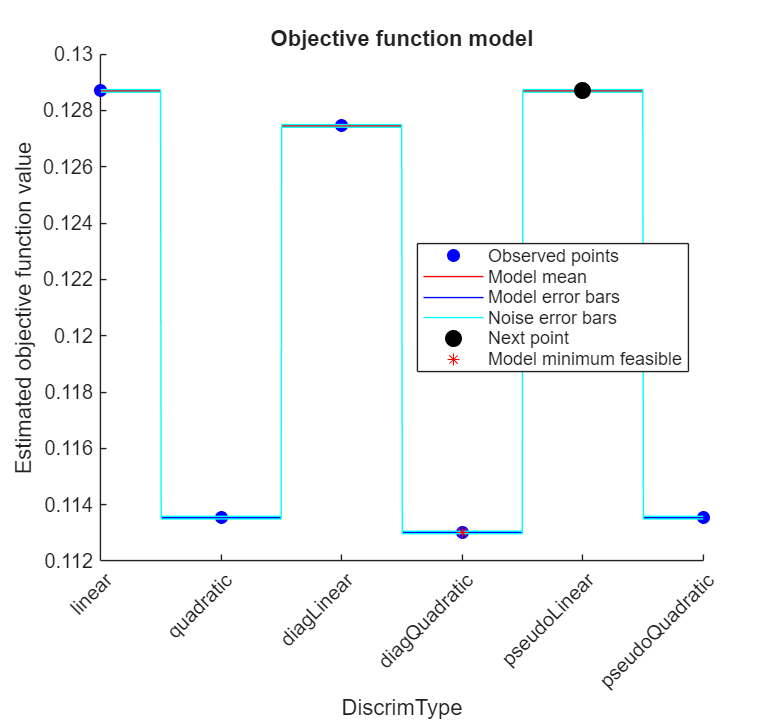
rng("default") tallrng("default") [Mdl,FitInfo,HyperparameterOptimizationResults] = fitcdiscr(Z,Y, ... OptimizeHyperparameters="auto", ... HyperparameterOptimizationOptions=struct(Holdout=0.3, ... AcquisitionFunctionName="expected-improvement-plus"))
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 2: Completed in 6 sec
- Pass 2 of 2: Completed in 7.3 sec
Evaluation completed in 22 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 2.5 sec
Evaluation completed in 2.7 sec
|======================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | DiscrimType |
| | result | | runtime | (observed) | (estim.) | |
|======================================================================================|
| 1 | Best | 0.11354 | 29.665 | 0.11354 | 0.11354 | quadratic |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.3 sec
Evaluation completed in 2.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.84 sec
Evaluation completed in 0.94 sec
| 2 | Accept | 0.11354 | 5.0412 | 0.11354 | 0.11354 | pseudoQuadra |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1 sec
Evaluation completed in 2.2 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.4 sec
Evaluation completed in 1.5 sec
| 3 | Accept | 0.12869 | 5.2654 | 0.11354 | 0.11859 | pseudoLinear |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.3 sec
Evaluation completed in 1.9 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.74 sec
Evaluation completed in 0.85 sec
| 4 | Accept | 0.12745 | 3.8881 | 0.11354 | 0.1208 | diagLinear |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.88 sec
Evaluation completed in 1.5 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.74 sec
Evaluation completed in 0.84 sec
| 5 | Accept | 0.12869 | 3.5151 | 0.11354 | 0.12238 | linear |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.85 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.78 sec
Evaluation completed in 0.87 sec
| 6 | Best | 0.11301 | 3.1481 | 0.11301 | 0.12082 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.85 sec
Evaluation completed in 1.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.1 sec
Evaluation completed in 1.2 sec
| 7 | Accept | 0.11301 | 3.5265 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.86 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.74 sec
Evaluation completed in 0.83 sec
| 8 | Accept | 0.11301 | 3.0978 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.9 sec
Evaluation completed in 1.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.73 sec
Evaluation completed in 0.81 sec
| 9 | Accept | 0.11301 | 3.144 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.1 sec
Evaluation completed in 2.1 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.73 sec
Evaluation completed in 0.84 sec
| 10 | Accept | 0.11301 | 3.823 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.3 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.72 sec
Evaluation completed in 0.8 sec
| 11 | Accept | 0.11301 | 3.4762 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.92 sec
Evaluation completed in 1.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.84 sec
Evaluation completed in 0.94 sec
| 12 | Accept | 0.11301 | 3.2704 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.83 sec
Evaluation completed in 1.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.71 sec
Evaluation completed in 0.81 sec
| 13 | Accept | 0.11301 | 3.1015 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.83 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.2 sec
Evaluation completed in 1.3 sec
| 14 | Accept | 0.11301 | 3.4993 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.96 sec
Evaluation completed in 1.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.72 sec
Evaluation completed in 0.82 sec
| 15 | Accept | 0.11301 | 3.1564 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.82 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.71 sec
Evaluation completed in 0.8 sec
| 16 | Accept | 0.11354 | 2.9859 | 0.11301 | 0.11301 | pseudoQuadra |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.83 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.71 sec
Evaluation completed in 0.8 sec
| 17 | Accept | 0.11354 | 2.9703 | 0.11301 | 0.11301 | quadratic |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.3 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.73 sec
Evaluation completed in 0.82 sec
| 18 | Accept | 0.11301 | 3.4992 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.3 sec
Evaluation completed in 1.8 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.71 sec
Evaluation completed in 0.8 sec
| 19 | Accept | 0.11301 | 3.5022 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.83 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.73 sec
Evaluation completed in 0.82 sec
| 20 | Accept | 0.11301 | 3.019 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.83 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.74 sec
Evaluation completed in 0.82 sec
|======================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | DiscrimType |
| | result | | runtime | (observed) | (estim.) | |
|======================================================================================|
| 21 | Accept | 0.11301 | 3.016 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.92 sec
Evaluation completed in 1.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.7 sec
Evaluation completed in 0.79 sec
| 22 | Accept | 0.11301 | 3.1365 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.93 sec
Evaluation completed in 1.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.76 sec
Evaluation completed in 0.85 sec
| 23 | Accept | 0.11354 | 3.1681 | 0.11301 | 0.11301 | quadratic |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.84 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.72 sec
Evaluation completed in 0.81 sec
| 24 | Accept | 0.11301 | 2.9795 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.8 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.8 sec
Evaluation completed in 1.2 sec
| 25 | Accept | 0.11301 | 3.4289 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.1 sec
Evaluation completed in 1.6 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.68 sec
Evaluation completed in 0.78 sec
| 26 | Accept | 0.11301 | 3.2509 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.83 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.71 sec
Evaluation completed in 0.8 sec
| 27 | Accept | 0.11354 | 3.0354 | 0.11301 | 0.11301 | pseudoQuadra |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.81 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.74 sec
Evaluation completed in 0.82 sec
| 28 | Accept | 0.11301 | 2.9747 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 1.9 sec
Evaluation completed in 2.4 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.71 sec
Evaluation completed in 0.8 sec
| 29 | Accept | 0.11301 | 4.0534 | 0.11301 | 0.11301 | diagQuadrati |
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.8 sec
Evaluation completed in 1.3 sec
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.7 sec
Evaluation completed in 0.79 sec
| 30 | Accept | 0.11301 | 2.9555 | 0.11301 | 0.11301 | diagQuadrati |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 155.2869 seconds
Total objective function evaluation time: 128.5936
Best observed feasible point:
DiscrimType
_____________
diagQuadratic
Observed objective function value = 0.11301
Estimated objective function value = 0.11301
Function evaluation time = 3.1481
Best estimated feasible point (according to models):
DiscrimType
_____________
diagQuadratic
Estimated objective function value = 0.11301
Estimated function evaluation time = 3.3967
Evaluating tall expression using the Parallel Pool 'Processes':
- Pass 1 of 1: Completed in 0.69 sec
Evaluation completed in 1.2 sec
Mdl =
CompactClassificationDiscriminant
PredictorNames: {'x1' 'x2' 'x3' 'x4' 'x5' 'x6'}
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [0 1]
ScoreTransform: 'none'
DiscrimType: 'diagQuadratic'
Mu: [2×6 double]
Coeffs: [2×2 struct]
Properties, Methods
FitInfo = struct with no fields.
HyperparameterOptimizationResults =
SupervisedLearningBayesianOptimization
ObjectiveFcn: @createObjFcn/tallObjFcn
VariableDescriptions: [1×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 0.1130
XAtMinObjective: [1×1 table]
MinEstimatedObjective: 0.1130
XAtMinEstimatedObjective: [1×1 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 155.2869
NextPoint: [1×1 table]
XTrace: [30×1 table]
ObjectiveTrace: [30×1 double]
LossFun: 'mincost'
LossTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
After training a model, you can generate C/C++ code that predicts labels for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
If you specify the
Cost,Prior, andWeightsname-value arguments, the output model object stores the specified values in theCost,Prior, andWproperties, respectively. TheCostproperty stores the user-specified cost matrix as is. ThePriorandWproperties store the prior probabilities and observation weights, respectively, after normalization. For details, see Misclassification Cost Matrix, Prior Probabilities, and Observation Weights.The software uses the
Costproperty for prediction, but not training. Therefore,Costis not read-only; you can change the property value by using dot notation after creating the trained model.
Alternative Functionality
Functions
The classify function also performs
discriminant analysis. classify is usually more awkward to
use.
classifyrequires you to fit the classifier every time you make a new prediction.classifydoes not perform cross-validation or hyperparameter optimization.classifyrequires you to fit the classifier when changing prior probabilities.