fitrensemble
Fit ensemble of learners for regression
Syntax
Description
Mdl = fitrensemble(Tbl,ResponseVarName)Mdl. By
default, Mdl contains the results of boosting 100
regression trees using LSBoost and the predictor and response data in the table
Tbl. ResponseVarName is the name of
the response variable in Tbl.
Mdl = fitrensemble(Tbl,formula)formula to fit the model to the predictor and
response data in the table Tbl. formula is
an explanatory model of the response and a subset of predictor variables in
Tbl used to fit Mdl. For example,
'Y~X1+X2+X3' fits the response variable
Tbl.Y as a function of the predictor variables
Tbl.X1, Tbl.X2, and
Tbl.X3.
Mdl = fitrensemble(___,Name,Value)Name,Value
pair arguments and any of the input arguments in the previous syntaxes. For
example, you can specify the number of learning cycles, the ensemble aggregation
method, or to implement 10-fold cross-validation.
[
also returns Mdl,AggregateOptimizationResults] = fitrensemble(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments.
You must also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this
syntax to optimize on compact model size instead of cross-validation loss, and
to perform a set of multiple optimization problems that have the same options
but different constraint bounds.
Examples
Create a regression ensemble that predicts the fuel economy of a car given the number of cylinders, volume displaced by the cylinders, horsepower, and weight. Then, train another ensemble using fewer predictors. Compare the in-sample predictive accuracies of the ensembles.
Load the carsmall data set. Store the variables to be used in training in a table.
load carsmall
Tbl = table(Cylinders,Displacement,Horsepower,Weight,MPG);Train a regression ensemble.
Mdl1 = fitrensemble(Tbl,'MPG');Mdl1 is a RegressionEnsemble model. Some notable characteristics of Mdl1 are:
The ensemble aggregation algorithm is
'LSBoost'.Because the ensemble aggregation method is a boosting algorithm, regression trees that allow a maximum of 10 splits compose the ensemble.
One hundred trees compose the ensemble.
Because MPG is a variable in the MATLAB® Workspace, you can obtain the same result by entering
Mdl1 = fitrensemble(Tbl,MPG);
Use the trained regression ensemble to predict the fuel economy for a four-cylinder car with a 200-cubic inch displacement, 150 horsepower, and weighing 3000 lbs.
pMPG = predict(Mdl1,[4 200 150 3000])
pMPG = 25.6467
Train a new ensemble using all predictors in Tbl except Displacement.
formula = 'MPG ~ Cylinders + Horsepower + Weight';
Mdl2 = fitrensemble(Tbl,formula);Compare the resubstitution MSEs between Mdl1 and Mdl2.
mse1 = resubLoss(Mdl1)
mse1 = 0.3096
mse2 = resubLoss(Mdl2)
mse2 = 0.5861
The in-sample MSE for the ensemble that trains on all predictors is lower.
Train an ensemble of boosted regression trees by using fitrensemble. Reduce training time by specifying the 'NumBins' name-value pair argument to bin numeric predictors. After training, you can reproduce binned predictor data by using the BinEdges property of the trained model and the discretize function.
Generate a sample data set.
rng('default') % For reproducibility N = 1e6; X1 = randi([-1,5],[N,1]); X2 = randi([5,10],[N,1]); X3 = randi([0,5],[N,1]); X4 = randi([1,10],[N,1]); X = [X1 X2 X3 X4]; y = X1 + X2 + X3 + X4 + normrnd(0,1,[N,1]);
Train an ensemble of boosted regression trees using least-squares boosting (LSBoost, the default value). Time the function for comparison purposes.
tic Mdl1 = fitrensemble(X,y); toc
Elapsed time is 78.662954 seconds.
Speed up training by using the 'NumBins' name-value pair argument. If you specify the 'NumBins' value as a positive integer scalar, then the software bins every numeric predictor into a specified number of equiprobable bins, and then grows trees on the bin indices instead of the original data. The software does not bin categorical predictors.
tic
Mdl2 = fitrensemble(X,y,'NumBins',50);
tocElapsed time is 43.353208 seconds.
The process is about two times faster when you use binned data instead of the original data. Note that the elapsed time can vary depending on your operating system.
Compare the regression errors by resubstitution.
rsLoss = resubLoss(Mdl1)
rsLoss = 1.0134
rsLoss2 = resubLoss(Mdl2)
rsLoss2 = 1.0133
In this example, binning predictor values reduces training time without a significant loss of accuracy. In general, when you have a large data set like the one in this example, using the binning option speeds up training but causes a potential decrease in accuracy. If you want to reduce training time further, specify a smaller number of bins.
Reproduce binned predictor data by using the BinEdges property of the trained model and the discretize function.
X = Mdl2.X; % Predictor data Xbinned = zeros(size(X)); edges = Mdl2.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the discretize function. xbinned = discretize(x,[-inf; edges{j}; inf]); Xbinned(:,j) = xbinned; end
Xbinned contains the bin indices, ranging from 1 to the number of bins, for numeric predictors. Xbinned values are 0 for categorical predictors. If X contains NaNs, then the corresponding Xbinned values are NaNs.
Estimate the generalization error of an ensemble of boosted regression trees.
Load the carsmall data set. Choose the number of cylinders, volume displaced by the cylinders, horsepower, and weight as predictors of fuel economy.
load carsmall
X = [Cylinders Displacement Horsepower Weight];Cross-validate an ensemble of regression trees using 10-fold cross-validation. Using a decision tree template, specify that each tree should be a split once only.
rng(1); % For reproducibility t = templateTree('MaxNumSplits',1); Mdl = fitrensemble(X,MPG,'Learners',t,'CrossVal','on');
Mdl is a RegressionPartitionedEnsemble model.
Plot the cumulative, 10-fold cross-validated, mean-squared error (MSE). Display the estimated generalization error of the ensemble.
kflc = kfoldLoss(Mdl,'Mode','cumulative'); figure; plot(kflc); ylabel('10-fold cross-validated MSE'); xlabel('Learning cycle');
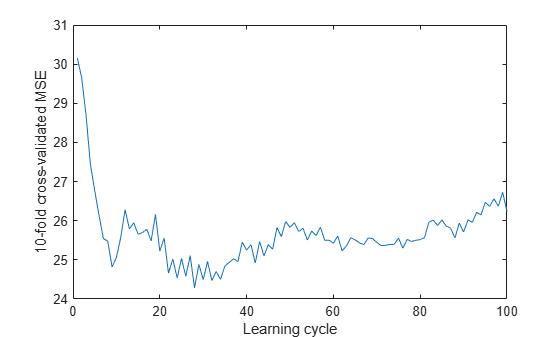
estGenError = kflc(end)
estGenError = 26.2356
kfoldLoss returns the generalization error by default. However, plotting the cumulative loss allows you to monitor how the loss changes as weak learners accumulate in the ensemble.
The ensemble achieves an MSE of around 23.5 after accumulating about 30 weak learners.
If you are satisfied with the generalization error of the ensemble, then, to create a predictive model, train the ensemble again using all of the settings except cross-validation. However, it is good practice to tune hyperparameters such as the maximum number of decision splits per tree and the number of learning cycles..
Automatically optimize hyperparameters of a regression ensemble model using fitrensemble.
Load the carsmall data set.
load carsmallSpecify Horsepower and Weight as the predictor variables (X) and MPG as the response variable (Y).
X = [Horsepower Weight]; Y = MPG;
Find hyperparameters that minimize the 5-fold cross-validation loss by using automatic hyperparameter optimization. For reproducibility of the optimization, set the random seed and use the "expected-improvement-plus" acquisition function. For reproducibility of the random forest algorithm, specify the Reproducible name-value argument as true for tree learners.
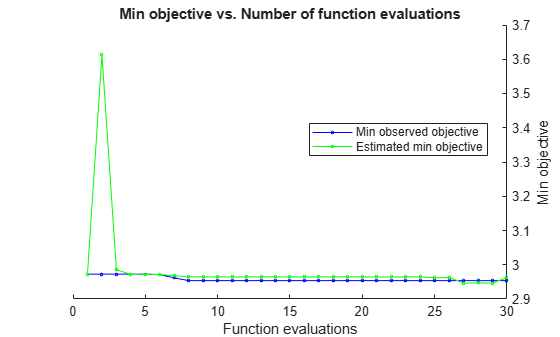
rng(0,"twister") t = templateTree(Reproducible=true); hpoOptions = hyperparameterOptimizationOptions(AcquisitionFunctionName="expected-improvement-plus"); Mdl = fitrensemble(X,Y,OptimizeHyperparameters="auto", ... Learners=t,HyperparameterOptimizationOptions=hpoOptions)
|===================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | ycles | | |
|===================================================================================================================================|
| 1 | Best | 2.9726 | 3.2434 | 2.9726 | 2.9726 | Bag | 413 | - | 1 |
| 2 | Accept | 6.2619 | 0.16866 | 2.9726 | 3.6133 | LSBoost | 57 | 0.0016067 | 6 |
| 3 | Accept | 2.9975 | 0.2387 | 2.9726 | 2.9852 | Bag | 32 | - | 2 |
| 4 | Accept | 4.1897 | 0.33946 | 2.9726 | 2.972 | Bag | 55 | - | 40 |
| 5 | Accept | 6.3321 | 0.10409 | 2.9726 | 2.9715 | LSBoost | 55 | 0.001005 | 2 |
| 6 | Best | 2.9714 | 0.29755 | 2.9714 | 2.9715 | Bag | 39 | - | 1 |
| 7 | Best | 2.9615 | 0.37982 | 2.9615 | 2.9681 | Bag | 55 | - | 1 |
| 8 | Accept | 3.0499 | 0.096392 | 2.9615 | 2.9873 | Bag | 10 | - | 1 |
| 9 | Accept | 2.9855 | 3.0978 | 2.9615 | 2.9633 | Bag | 500 | - | 1 |
| 10 | Best | 2.928 | 1.7874 | 2.928 | 2.9317 | Bag | 282 | - | 2 |
| 11 | Accept | 2.9362 | 1.9048 | 2.928 | 2.9336 | Bag | 304 | - | 2 |
| 12 | Accept | 2.9316 | 1.5702 | 2.928 | 2.9327 | Bag | 247 | - | 2 |
| 13 | Best | 2.9215 | 1.5217 | 2.9215 | 2.9299 | Bag | 242 | - | 2 |
| 14 | Accept | 4.1881 | 0.56119 | 2.9215 | 2.9298 | LSBoost | 494 | 0.020296 | 50 |
| 15 | Accept | 4.1881 | 0.23795 | 2.9215 | 2.9297 | LSBoost | 248 | 0.20517 | 45 |
| 16 | Accept | 3.6293 | 0.066487 | 2.9215 | 2.9297 | LSBoost | 24 | 0.95396 | 1 |
| 17 | Accept | 3.9111 | 0.050923 | 2.9215 | 2.9296 | LSBoost | 13 | 0.10786 | 1 |
| 18 | Accept | 3.1129 | 0.044783 | 2.9215 | 2.9296 | LSBoost | 12 | 0.9945 | 20 |
| 19 | Accept | 4.1881 | 0.40136 | 2.9215 | 2.9288 | LSBoost | 416 | 0.97471 | 49 |
| 20 | Accept | 3.1673 | 0.044488 | 2.9215 | 2.9285 | LSBoost | 10 | 0.98772 | 6 |
|===================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | ycles | | |
|===================================================================================================================================|
| 21 | Accept | 2.9942 | 0.044051 | 2.9215 | 2.9284 | LSBoost | 10 | 0.58041 | 18 |
| 22 | Best | 2.9069 | 0.053172 | 2.9069 | 2.9078 | LSBoost | 10 | 0.36105 | 9 |
| 23 | Accept | 3.0745 | 0.054998 | 2.9069 | 2.9084 | LSBoost | 10 | 0.21441 | 10 |
| 24 | Accept | 3.0731 | 0.050361 | 2.9069 | 2.9091 | LSBoost | 10 | 0.3811 | 5 |
| 25 | Accept | 2.975 | 0.039153 | 2.9069 | 2.9118 | LSBoost | 10 | 0.51214 | 11 |
| 26 | Accept | 2.9209 | 0.049174 | 2.9069 | 2.9134 | LSBoost | 10 | 0.34339 | 16 |
| 27 | Accept | 2.9201 | 0.059036 | 2.9069 | 2.9083 | LSBoost | 10 | 0.36943 | 12 |
| 28 | Accept | 2.9124 | 1.0507 | 2.9069 | 2.9084 | Bag | 158 | - | 2 |
| 29 | Accept | 2.9079 | 0.071955 | 2.9069 | 2.9072 | LSBoost | 10 | 0.34675 | 12 |
| 30 | Accept | 2.9437 | 0.9491 | 2.9069 | 2.9076 | Bag | 145 | - | 2 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 27.5181 seconds
Total objective function evaluation time: 18.5788
Best observed feasible point:
Method NumLearningCycles LearnRate MinLeafSize
_______ _________________ _________ ___________
LSBoost 10 0.36105 9
Observed objective function value = 2.9069
Estimated objective function value = 2.9238
Function evaluation time = 0.053172
Best estimated feasible point (according to models):
Method NumLearningCycles LearnRate MinLeafSize
_______ _________________ _________ ___________
LSBoost 10 0.34675 12
Estimated objective function value = 2.9076
Estimated function evaluation time = 0.05044
Mdl =
RegressionEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
NumTrained: 10
Method: 'LSBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [10×1 double]
FitInfoDescription: {2×1 cell}
Regularization: []
Properties, Methods
The trained model Mdl corresponds to the best estimated feasible point and uses the same hyperparameter values for Method, NumLearningCycles, LearnRate, and MinLeafSize.
Find the hyperparameter values used to train Mdl by using the bestPoint function. By default, bestPoint uses the same best point criterion used by fitrensemble during the hyperparameter optimization ("min-visited-upper-confidence-interval"). In general, fit functions determine the best hyperparameter values based on the "min-visited-upper-confidence-interval" criterion (instead of the "min-observed" criterion) to avoid overfitting to noise in the data set.
bestEstimatedPoint = bestPoint(Mdl.HyperparameterOptimizationResults)
bestEstimatedPoint=1×4 table
Method NumLearningCycles LearnRate MinLeafSize
_______ _________________ _________ ___________
LSBoost 10 0.34675 12
Verify that the results match the properties of Mdl and its weak learners. Note that the template for the regression tree weak learners contains a MinLeaf value instead of a MinLeafSize value, but the two options are equivalent.
modelProperties = table(string(Mdl.ModelParameters.Method), ... Mdl.ModelParameters.NLearn, ... VariableNames=["Method","NumLearningCycles"])
modelProperties=1×2 table
Method NumLearningCycles
_________ _________________
"LSBoost" 10
weakLearnerProperties = Mdl.ModelParameters.LearnerTemplates{1}weakLearnerProperties =
Fit template for regression Tree.
SplitCriterion: []
MinParent: []
MinLeaf: 12
MaxSplits: 10
NVarToSample: []
MergeLeaves: 'off'
Prune: 'off'
PruneCriterion: []
QEToler: []
NSurrogate: []
MaxCat: []
AlgCat: []
PredictorSelection: []
UseChisqTest: []
Stream: []
Reproducible: 1
Version: 3
Method: 'Tree'
Type: 'regression'
One way to create an ensemble of boosted regression trees that has satisfactory predictive performance is to tune the decision tree complexity level using cross-validation. While searching for an optimal complexity level, tune the learning rate to minimize the number of learning cycles as well.
This example manually finds optimal parameters by using the cross-validation option (the 'KFold' name-value pair argument) and the kfoldLoss function. Alternatively, you can use the 'OptimizeHyperparameters' name-value pair argument to optimize hyperparameters automatically. See Optimize Regression Ensemble.
Load the carsmall data set. Choose the number of cylinders, volume displaced by the cylinders, horsepower, and weight as predictors of fuel economy.
load carsmall
Tbl = table(Cylinders,Displacement,Horsepower,Weight,MPG);The default values of the tree depth controllers for boosting regression trees are:
10forMaxNumSplits.5forMinLeafSize10forMinParentSize
To search for the optimal tree-complexity level:
Cross-validate a set of ensembles. Exponentially increase the tree-complexity level for subsequent ensembles from decision stump (one split) to at most n - 1 splits. n is the sample size. Also, vary the learning rate for each ensemble between 0.1 to 1.
Estimate the cross-validated mean-squared error (MSE) for each ensemble.
For tree-complexity level , , compare the cumulative, cross-validated MSE of the ensembles by plotting them against number of learning cycles. Plot separate curves for each learning rate on the same figure.
Choose the curve that achieves the minimal MSE, and note the corresponding learning cycle and learning rate.
Cross-validate a deep regression tree and a stump. Because the data contain missing values, use surrogate splits. These regression trees serve as benchmarks.
rng(1) % For reproducibility MdlDeep = fitrtree(Tbl,'MPG','CrossVal','on','MergeLeaves','off', ... 'MinParentSize',1,'Surrogate','on'); MdlStump = fitrtree(Tbl,'MPG','MaxNumSplits',1,'CrossVal','on', ... 'Surrogate','on');
Cross-validate an ensemble of 150 boosted regression trees using 5-fold cross-validation. Using a tree template:
Vary the maximum number of splits using the values in the sequence . m is such that is no greater than n - 1.
Turn on surrogate splits.
For each variant, adjust the learning rate using each value in the set {0.1, 0.25, 0.5, 1}.
n = size(Tbl,1); m = floor(log2(n - 1)); learnRate = [0.1 0.25 0.5 1]; numLR = numel(learnRate); maxNumSplits = 2.^(0:m); numMNS = numel(maxNumSplits); numTrees = 150; Mdl = cell(numMNS,numLR); for k = 1:numLR for j = 1:numMNS t = templateTree('MaxNumSplits',maxNumSplits(j),'Surrogate','on'); Mdl{j,k} = fitrensemble(Tbl,'MPG','NumLearningCycles',numTrees, ... 'Learners',t,'KFold',5,'LearnRate',learnRate(k)); end end
Estimate the cumulative, cross-validated MSE of each ensemble.
kflAll = @(x)kfoldLoss(x,'Mode','cumulative'); errorCell = cellfun(kflAll,Mdl,'Uniform',false); error = reshape(cell2mat(errorCell),[numTrees numel(maxNumSplits) numel(learnRate)]); errorDeep = kfoldLoss(MdlDeep); errorStump = kfoldLoss(MdlStump);
Plot how the cross-validated MSE behaves as the number of trees in the ensemble increases. Plot the curves with respect to learning rate on the same plot, and plot separate plots for varying tree-complexity levels. Choose a subset of tree complexity levels to plot.
mnsPlot = [1 round(numel(maxNumSplits)/2) numel(maxNumSplits)]; figure; for k = 1:3 subplot(2,2,k) plot(squeeze(error(:,mnsPlot(k),:)),'LineWidth',2) axis tight hold on h = gca; plot(h.XLim,[errorDeep errorDeep],'-.b','LineWidth',2) plot(h.XLim,[errorStump errorStump],'-.r','LineWidth',2) plot(h.XLim,min(min(error(:,mnsPlot(k),:))).*[1 1],'--k') h.YLim = [10 50]; xlabel('Number of trees') ylabel('Cross-validated MSE') title(sprintf('MaxNumSplits = %0.3g', maxNumSplits(mnsPlot(k)))) hold off end hL = legend([cellstr(num2str(learnRate','Learning Rate = %0.2f')); ... 'Deep Tree';'Stump';'Min. MSE']); hL.Position(1) = 0.6;
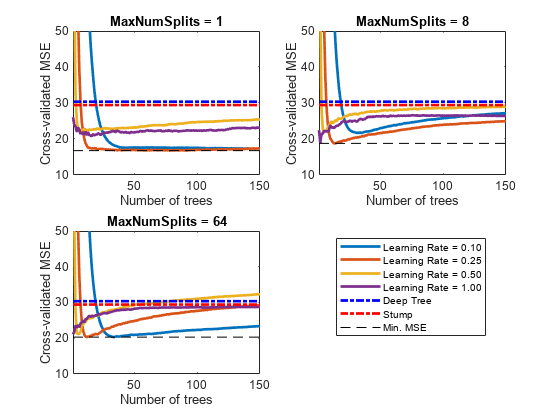
Each curve contains a minimum cross-validated MSE occurring at the optimal number of trees in the ensemble.
Identify the maximum number of splits, number of trees, and learning rate that yields the lowest MSE overall.
[minErr,minErrIdxLin] = min(error(:));
[idxNumTrees,idxMNS,idxLR] = ind2sub(size(error),minErrIdxLin);
fprintf('\nMin. MSE = %0.5f',minErr)Min. MSE = 16.77593
fprintf('\nOptimal Parameter Values:\nNum. Trees = %d',idxNumTrees);Optimal Parameter Values: Num. Trees = 78
fprintf('\nMaxNumSplits = %d\nLearning Rate = %0.2f\n',... maxNumSplits(idxMNS),learnRate(idxLR))
MaxNumSplits = 1 Learning Rate = 0.25
Create a predictive ensemble based on the optimal hyperparameters and the entire training set.
tFinal = templateTree('MaxNumSplits',maxNumSplits(idxMNS),'Surrogate','on'); MdlFinal = fitrensemble(Tbl,'MPG','NumLearningCycles',idxNumTrees, ... 'Learners',tFinal,'LearnRate',learnRate(idxLR))
MdlFinal =
RegressionEnsemble
PredictorNames: {'Cylinders' 'Displacement' 'Horsepower' 'Weight'}
ResponseName: 'MPG'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
NumTrained: 78
Method: 'LSBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [78×1 double]
FitInfoDescription: {2×1 cell}
Regularization: []
Properties, Methods
MdlFinal is a RegressionEnsemble. To predict the fuel economy of a car given its number of cylinders, volume displaced by the cylinders, horsepower, and weight, you can pass the predictor data and MdlFinal to predict.
Instead of searching optimal values manually by using the cross-validation option ('KFold') and the kfoldLoss function, you can use the 'OptimizeHyperparameters' name-value pair argument. When you specify 'OptimizeHyperparameters', the software finds optimal parameters automatically using Bayesian optimization. The optimal values obtained by using 'OptimizeHyperparameters' can be different from those obtained using manual search.
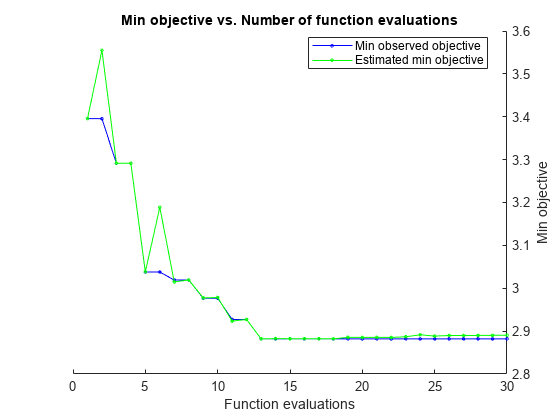
t = templateTree('Surrogate','on'); mdl = fitrensemble(Tbl,'MPG','Learners',t, ... 'OptimizeHyperparameters',{'NumLearningCycles','LearnRate','MaxNumSplits'})
|====================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits |
| | result | log(1+loss) | runtime | (observed) | (estim.) | ycles | | |
|====================================================================================================================|
| 1 | Best | 3.3955 | 0.27764 | 3.3955 | 3.3955 | 26 | 0.072054 | 3 |
| 2 | Accept | 6.0976 | 0.38981 | 3.3955 | 3.5549 | 170 | 0.0010295 | 70 |
| 3 | Best | 3.2914 | 0.49048 | 3.2914 | 3.2917 | 273 | 0.61026 | 6 |
| 4 | Accept | 6.1839 | 0.11118 | 3.2914 | 3.2915 | 80 | 0.0016871 | 1 |
| 5 | Best | 3.0379 | 0.08038 | 3.0379 | 3.0384 | 18 | 0.21288 | 37 |
| 6 | Accept | 3.169 | 0.4818 | 3.0379 | 3.0397 | 369 | 0.17992 | 4 |
| 7 | Accept | 3.0501 | 0.045081 | 3.0379 | 3.0402 | 10 | 0.28387 | 44 |
| 8 | Accept | 3.5336 | 0.047223 | 3.0379 | 3.1625 | 10 | 0.16084 | 99 |
| 9 | Best | 2.9907 | 0.046076 | 2.9907 | 3.1233 | 12 | 0.3484 | 3 |
| 10 | Best | 2.9378 | 0.043398 | 2.9378 | 2.968 | 11 | 0.3631 | 4 |
| 11 | Accept | 2.9629 | 0.030803 | 2.9378 | 2.943 | 10 | 0.2995 | 1 |
| 12 | Accept | 3.1123 | 0.029387 | 2.9378 | 2.9337 | 10 | 0.95361 | 1 |
| 13 | Best | 2.9067 | 0.076107 | 2.9067 | 2.9493 | 71 | 0.30342 | 1 |
| 14 | Best | 2.9016 | 0.083214 | 2.9016 | 2.9095 | 59 | 0.28365 | 1 |
| 15 | Accept | 5.891 | 0.031032 | 2.9016 | 2.9072 | 10 | 0.028505 | 1 |
| 16 | Accept | 6.318 | 0.032695 | 2.9016 | 2.9079 | 10 | 0.0064473 | 1 |
| 17 | Accept | 2.9406 | 0.40265 | 2.9016 | 2.9282 | 494 | 0.2463 | 1 |
| 18 | Accept | 3.101 | 0.032536 | 2.9016 | 2.9189 | 10 | 0.23598 | 1 |
| 19 | Accept | 3.3256 | 1.0379 | 2.9016 | 2.9085 | 500 | 0.33176 | 66 |
| 20 | Accept | 2.9474 | 0.032808 | 2.9016 | 2.9062 | 10 | 0.51189 | 1 |
|====================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | NumLearningC-| LearnRate | MaxNumSplits |
| | result | log(1+loss) | runtime | (observed) | (estim.) | ycles | | |
|====================================================================================================================|
| 21 | Accept | 2.9906 | 0.040708 | 2.9016 | 2.9105 | 10 | 0.26521 | 7 |
| 22 | Accept | 2.9384 | 0.032004 | 2.9016 | 2.9066 | 10 | 0.41211 | 1 |
| 23 | Accept | 3.2353 | 0.043367 | 2.9016 | 2.9034 | 10 | 0.76556 | 98 |
| 24 | Accept | 3.0165 | 0.029857 | 2.9016 | 2.9021 | 10 | 0.6993 | 1 |
| 25 | Accept | 2.9599 | 0.083848 | 2.9016 | 2.9214 | 72 | 0.25746 | 2 |
| 26 | Best | 2.8927 | 0.031856 | 2.8927 | 2.912 | 10 | 0.37133 | 1 |
| 27 | Best | 2.8783 | 0.030043 | 2.8783 | 2.9011 | 10 | 0.36962 | 1 |
| 28 | Accept | 2.8895 | 0.030452 | 2.8783 | 2.8978 | 10 | 0.36592 | 1 |
| 29 | Accept | 2.8908 | 0.030437 | 2.8783 | 2.896 | 10 | 0.36275 | 1 |
| 30 | Accept | 6.1839 | 0.063397 | 2.8783 | 2.896 | 10 | 0.013418 | 1 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 12.208 seconds
Total objective function evaluation time: 4.2182
Best observed feasible point:
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
10 0.36962 1
Observed objective function value = 2.8783
Estimated objective function value = 2.896
Function evaluation time = 0.030043
Best estimated feasible point (according to models):
NumLearningCycles LearnRate MaxNumSplits
_________________ _________ ____________
10 0.36962 1
Estimated objective function value = 2.896
Estimated function evaluation time = 0.031984
mdl =
RegressionEnsemble
PredictorNames: {'Cylinders' 'Displacement' 'Horsepower' 'Weight'}
ResponseName: 'MPG'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 94
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
NumTrained: 10
Method: 'LSBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [10×1 double]
FitInfoDescription: {2×1 cell}
Regularization: []
Properties, Methods
Input Arguments
Name-Value Arguments
Output Arguments
Tips
NumLearningCyclescan vary from a few dozen to a few thousand. Usually, an ensemble with good predictive power requires from a few hundred to a few thousand weak learners. However, you do not have to train an ensemble for that many cycles at once. You can start by growing a few dozen learners, inspect the ensemble performance and then, if necessary, train more weak learners usingresume.Ensemble performance depends on the ensemble setting and the setting of the weak learners. That is, if you specify weak learners with default parameters, then the ensemble can perform poorly. Therefore, like ensemble settings, it is good practice to adjust the parameters of the weak learners using templates, and to choose values that minimize generalization error.
If you specify to resample using
Resample, then it is good practice to resample to entire data set. That is, use the default setting of1forFResample.After training a model, you can generate C/C++ code that predicts responses for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
For details of ensemble aggregation algorithms, see Ensemble Algorithms.
If you specify
'Method','LSBoost', then the software grows shallow decision trees by default. You can adjust tree depth by specifying theMaxNumSplits,MinLeafSize, andMinParentSizename-value pair arguments usingtemplateTree.For dual-core systems and above,
fitrensembleparallelizes training using Intel Threading Building Blocks (TBB). For details on Intel TBB, see https://www.intel.com/content/www/us/en/developer/tools/oneapi/onetbb.html.
References
[1] Breiman, L. “Bagging Predictors.” Machine Learning. Vol. 26, pp. 123–140, 1996.
[2] Breiman, L. “Random Forests.” Machine Learning. Vol. 45, pp. 5–32, 2001.
[3] Freund, Y. and R. E. Schapire. “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting.” J. of Computer and System Sciences, Vol. 55, pp. 119–139, 1997.
[4] Friedman, J. “Greedy function approximation: A gradient boosting machine.” Annals of Statistics, Vol. 29, No. 5, pp. 1189–1232, 2001.
[5] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning section edition, Springer, New York, 2008.