Object Detection
Computer Vision Toolbox™ provides a comprehensive set of tools and functions to build, train, evaluate, and deploy object detection models using both deep learning and traditional computer vision techniques. You can start by creating labeled ground truth using the Image Labeler and Video Labeler apps, which support interactive and AI-assisted annotation of bounding boxes around objects in images and video frames.
Once you have labeled data, you can choose from a wide range of pretrained
deep learning object detectors, including YOLO v2, YOLO v3, YOLO v4, YOLOX,
RTMDet, SSD, and Grounding DINO. The toolbox also contains specialized detectors
like peopleDetector and faceDetector for
human and face recognition tasks. You can use these models directly for
inference or as a starting point for transfer learning, enabling you to
customize them to specific data sets and applications. For more information, see
Get Started with Object Detection Using Deep Learning. For
classical object detection methods, the toolbox includes support for the
aggregate channel features (ACF) and cascade (Viola-Jones) object
detectors.
The toolbox provides functions for training object detectors using transfer learning. The toolbox also provides functionality to manage and preprocess training data as well as data augmentation tools, that ensure robust model training by simulating real-world variations. For more information, see Get Started with Image Preprocessing and Augmentation for Deep Learning.
After you generate detections using pretrained or custom models, you can use
the Object
Detector Analyzer app to compare the detection results against ground
truth data. The app enables you to evaluate key performance metrics, such as the
confusion matrix, precision, recall, F1 score and mean Average Precision (mAP),
across a range of intersection over union (IOU) thresholds. Alternatively, you
can use the evaluateObjectDetection function to evaluate detection
performance metrics. For more information, see Evaluate Object Detector Performance and Get Started with Object Detector Analyzer App.

Apps
| Image Labeler | Label images for computer vision applications |
| Video Labeler | Label video for computer vision applications |
| Object Detector Analyzer | Interactively visualize and evaluate object detection results against ground truth (Since R2026a) |
Functions
Blocks
| Deep Learning Object Detector | Detect objects using trained deep learning object detector (Since R2021b) |
Topics
Create Ground Truth and Training Data for Object Detection
- Get Started with the Image Labeler
Interactively label rectangular ROIs for object detection, pixels for semantic segmentation, polygons for instance segmentation, and scenes for image classification. - Get Started with the Video Labeler
Interactively label rectangular ROIs for object detection, pixels for semantic segmentation, polygons for instance segmentation, and scenes for image classification in a video or image sequence. - Training Data for Object Detection and Semantic Segmentation
Create training data for object detection or semantic segmentation using the Image Labeler or Video Labeler. - Get Started with Image Preprocessing and Augmentation for Deep Learning
Preprocess data for deep learning applications with deterministic operations such as resizing, or augment training data with randomized operations such as random cropping.
Detect Objects Using Pretrained Detectors
- Get Started with Object Detection Using Deep Learning
Perform object detection using deep learning neural networks such as YOLOX, YOLO v4, RTMDet, and SSD. - Choose an Object Detector
Compare object detection deep learning models, such as YOLOX, YOLO v4, RTMDet, and SSD. - Get Started with Cascade Object Detector
Train a custom classifier. - Deep Learning in MATLAB (Deep Learning Toolbox)
Discover deep learning capabilities in MATLAB® using convolutional neural networks for classification and regression, including pretrained networks and transfer learning, and training on GPUs, CPUs, clusters, and clouds. - Pretrained Deep Neural Networks (Deep Learning Toolbox)
Learn how to download and use pretrained convolutional neural networks for classification, transfer learning and feature extraction.
Evaluate Object Detection Results
- Evaluate Object Detector Performance
Evaluate object detector performance using metrics such as average precision, precision recall, and confusion matrix. - Get Started with Object Detector Analyzer App
Use Object Detector Analyzer app to evaluate pretrained object detectors or precomputed detection results against the ground truth data, and evaluate performance metrics. - Calibrate Object Detection Confidence Scores
This example shows how to calibrate the confidence scores of an object using Platt scaling.
Featured Examples

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).
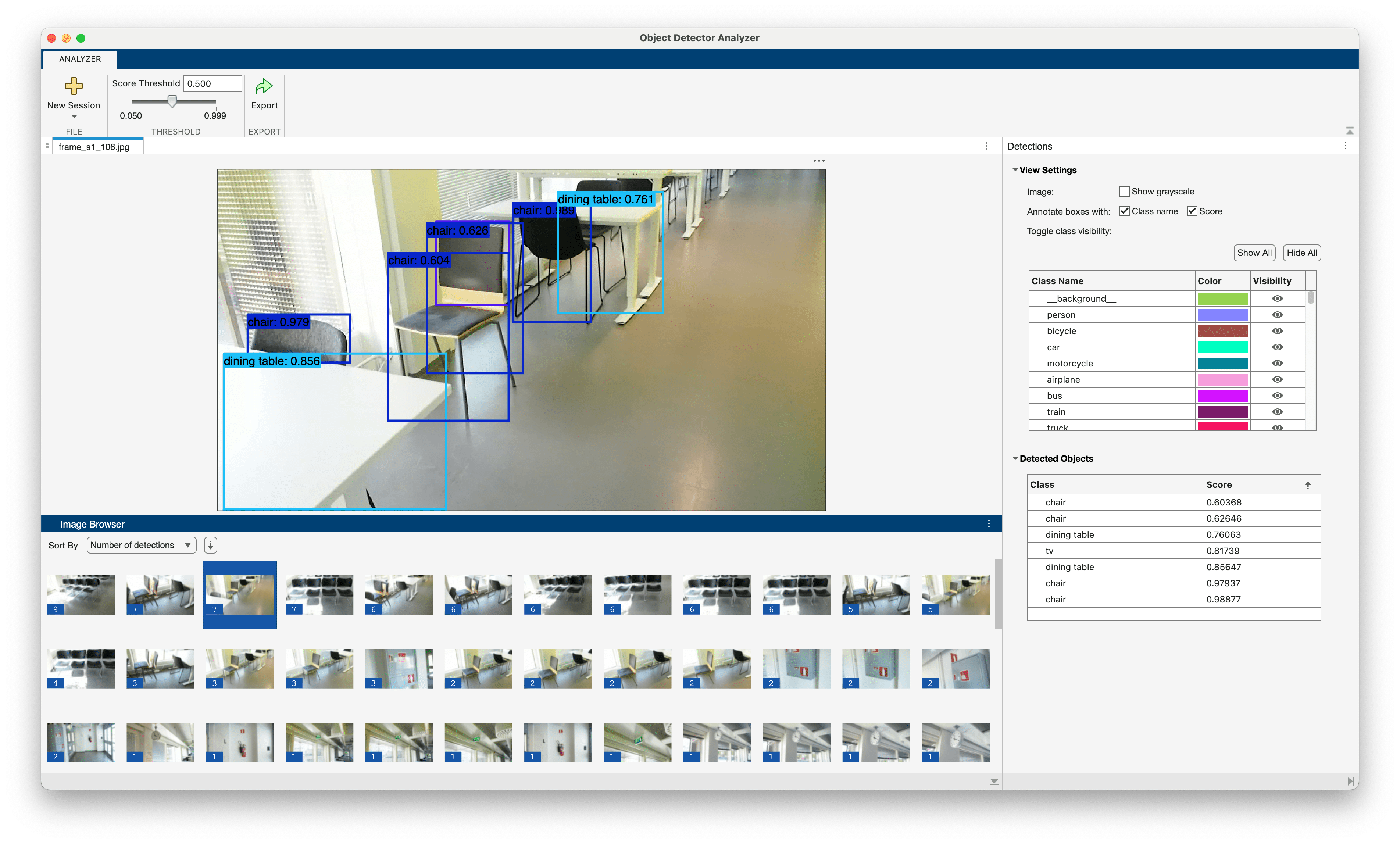
Visualize Object Detection Results from Pretrained PyTorch Model
Detect objects using a pretrained PyTorch® model and visualize the results in Object Detector Analyzer.

Automatically Label Ground Truth Using Vision-Language Model
Automatically label ground truth images for object detection using the Grounding DINO vision-language model (VLM).

Detect Small Objects Using Tiled Training of YOLOX Network
Detect small objects in full-resolution images using tiled training of a you only look once version X (YOLOX) deep learning network.

Object Detection in Large Satellite Imagery Using Deep Learning
Perform object detection on large satellite imagery using deep learning.

Object Detection Using YOLO v4 Deep Learning
Detect objects in images using you only look once version 4 (YOLO v4) deep learning network. In this example, you will

Multiclass Object Detection Using YOLO v2 Deep Learning
Train a YOLO v2 multiclass object detector and evaluate object detector performance across selected classes and overlap thresholds.

Train Object Detectors in Experiment Manager
Use the Experiment Manager app to find optimal training options for object detectors.

Find Object in Cluttered Scene Using Image Point Features
Detect a particular object in a cluttered scene, given a reference image of the object.

Detect Cars Using Gaussian Mixture Models
Detect and count cars in a video sequence using foreground detector based on Gaussian mixture models (GMMs).

Import Pretrained ONNX YOLO v2 Object Detector
Import pretrained YOLO v2 object detector from ONNX deep learning framework.
Export YOLO v2 Object Detector to ONNX
Export pretrained YOLO v2 object detector to ONNX deep learning framework.

Generate Code for Detecting Objects in Images by Using ACF Object Detector
Generate code from a MATLAB® function that detects objects in images by using an acfObjectDetector object. When you intend to generate code from your MATLAB function that uses an acfObjectDetector object, you must create the object outside of the MATLAB function. The example explains how to modify the MATLAB code in Train a Stop Sign Detector Using an ACF Object Detector to support code generation.

Code Generation for Object Detection by Using YOLO v2
Generate CUDA® code for object detection using YOLO v2.

Code Generation for Object Detection by Using Single Shot Multibox Detector
Generate CUDA code for an SSD network.

Code Generation for People Detection Using Deep Learning
Generate CUDA code for people detection