Get Started with Semantic Segmentation Using Deep Learning
Segmentation is an essential technique in computer vision and image processing. Semantic segmentation associates each pixel of an image with a class label, such as flower, person, road, or car. It does not differentiate between separate objects of the same class.
Traditional semantic segmentation techniques, such as region-based methods and edge detection, are often limited in handling variations and complexities in real-world images. Deep learning-based methods, particularly those leveraging convolutional neural networks (CNNs) and architectures like U-Net and fully convolutional networks (FCNs), can automatically learn and generalize complex patterns, enabling superior performance and adaptability across diverse datasets.

Use deep learning-based semantic segmentation for complex image scenes where the overall composition of the scene is important, but the identity of individual objects is not. To distinguish between segmented objects of the same class using instance segmentation, see Get Started with Instance Segmentation Using Deep Learning. You can use semantic segmentation for various tasks, including:
Autonomous driving
Industrial inspection
Classification of terrain visible in satellite imagery
Medical imaging analysis
You can perform inference on a test image with default network options using a pretrained semantic segmentation model, or train a semantic segmentation network on a custom data set.
Select Semantic Segmentation Model
Which semantic segmentation technique you choose often depends on your specific application and the characteristics of the images to be segmented. Use this table to choose an architecture for semantic segmentation available in Computer Vision Toolbox™ based on your application and image data.
| Semantic Segmentation Model | Functionality | Use Case | Examples |
|---|---|---|---|
BiSeNet v2 | bisenetv2 | Segment images using BiSeNet v2 when your application requires a real-time and precise segmentation, such as autonomous driving and video analysis. When rapid inference is a priority, especially when computational resources are limited, use BiSeNet v2 over U-Net and DeepLab v3+. Use a pretrained BiSeNet v2 network to perform inference on images containing standard scenes (such as people or cars), or train the network on a custom data set. | |
U-Net | Segment images using U-Net when training data is limited, such as in certain medical image applications. You must train this network. | Semantic Segmentation of Multispectral Images Using Deep Learning | |
Deeplab v3+ | deeplabv3plus | Use DeepLab v3+ when your application requires precise boundary delineation (such as in autonomous driving or satellite imagery). If computational resources are limited, or if the task involves simpler segmentation problems, U-Net, BiSeNet V2, or other lightweight architectures might be more appropriate. You must train this network. |
|
After you select a model architecture, you must prepare ground truth data and train the semantic segmentation network.
Perform Inference Using a Pretrained Semantic Segmentation Network
Follow these steps to perform semantic segmentation on a test image using a pretrained semantic segmentation model BiSeNet v2, or a model of your choice that you train. The pretrained BiSeNet v2 network in this example is pretrained on 171 object classes from the COCO Stuff dataset. You can install the Computer Vision Toolbox Model for BiSeNet v2 Semantic Segmentation Network from Add-On Explorer. For more information about installing add-ons, see Get and Manage Add-Ons. The add-on also requires Deep Learning Toolbox™.
Configure the pretrained network using the bisenetv2 function. The output, pretrainedNet, is a dlnetwork (Deep Learning Toolbox) object. The second output, classes is a string vector containing the class names the that the model was pretrained to segment.
[pretrainedNet,classes] = bisenetv2();
Load the test image into the workspace. Resize the test image to match input size of the network. Display the image.
I = imread("sunsetboats.png");
inputSize = pretrainedNet.Layers(1).InputSize(1:2);
img = imresize(I,inputSize);
imshow(img)
Segment objects in a test image using the semanticseg function. The function returns a segmentation map, a categorical array which relates the labels to each pixel in the input image.
segMap = semanticseg(img,pretrainedNet,Classes=classes);
Display the segmentation map overlaid on the image, ordered by the smallest object masks on top, using the labeloverlay function.
segmentedImage = labeloverlay(img,segMap,Transparency=0.4); imshow(segmentedImage)

To perform inference on a test image using any other pretrained semantic segmentation network, use the previously introduced process, but specify the pretrained network to the semanticseg function.
Prepare Ground Truth Data for Training
To prepare ground truth data for training a semantic segmentation network, you can label your ground truth data using an app or import existing labeled data. For an example of how to import a data set with existing pixel labels, see Import Pixel Labeled Dataset for Semantic Segmentation.
You can use these apps to interactively assign pixel labels to your image data.
Image Labeler – Label ground truth data in a collection of images using a pixel-labeling tool. To get started, see Get Started with the Image Labeler.
Video Labeler – Label ground truth data in a video, in an image sequence, or from a custom data source reader. To get started, see Get Started with the Video Labeler.
Ground Truth Labeler (Automated Driving Toolbox) – Label ground truth data in multiple videos, image sequences, or lidar point clouds. To get started, see Get Started with Ground Truth Labeling (Automated Driving Toolbox).
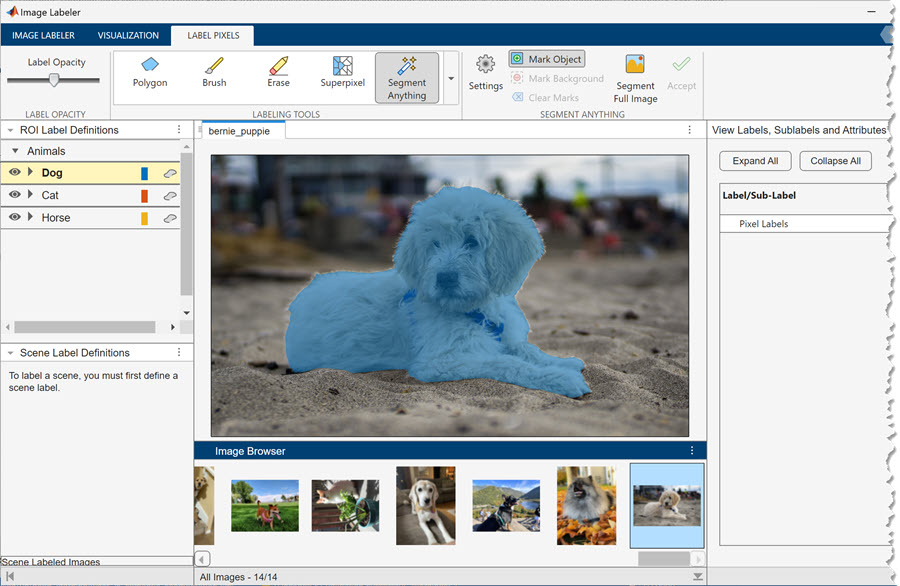
Label and Export Ground Truth Data
Once you choose the app required for your application, follow these steps to label and export your ground truth data:
Use one of the built-in algorithms in the apps or create your own custom algorithm to label your image data. To select a built-in pixel-labeling tool, such as the automatic segmentation algorithm Segment Anything, and label image data, see Label Pixels for Semantic Segmentation. To learn how to create your own automation algorithm, see Create Automation Algorithm Function for Labeling.
Export the labeled ground truth data as a
groundTruthobject, or if you are using the Ground Truth Labeler app, as agroundTruthMultisignal(Automated Driving Toolbox) object. To learn how to export pixel label data, see Share and Store Labeled Ground Truth Data. To learn how to access and verify pixel label data after exporting it, see How Labeler Apps Store Exported Pixel Labels.
Create Training Datastore
Next, follow these steps to create the training datastore:
Create training data from the
groundTruthobject using thepixelLabelTrainingDatafunction. If you are using the Ground Truth Labeler app, create training data from thegroundTruthMultisignalobject using thegatherLabelData(Automated Driving Toolbox) function.Combine the image datastore and the pixel label datastore returned by the
pixelLabelTrainingDatafunction into a single training datastore using thecombinefunction.
Preprocess and Augment Image Data for Training
At this stage, you must ensure that your training image data matches the input size of
the network. Otherwise, adjust the size of images to match the input size of the network
using the imresize
function.
To increase the diversity of training images without increasing the data set size and memory footprint, you can optionally apply a randomized augmentation to your image data. Apply augmentations, such as translation, cropping, or transforming an image to increase data versatility for training. To get started with data preprocessing and augmentation, see Get Started with Image Preprocessing and Augmentation for Deep Learning.
Train Semantic Segmentation Network
Train a deep learning network for semantic segmentation on the labeled data set in these steps.
Configure Network
Configure a semantic segmentation model based on the requirements of your use case. You can create your own deep learning network for semantic segmentation, or use one of the three trainable network architectures available – BiSeNet V2, U-Net, and Deeplab v3+. Use the table in the Select Semantic Segmentation Model section to choose one of these networks based on the characteristics of your data set and available computing resources.
If your segmentation task has specific requirements not well-addressed by these existing architectures, a custom network may be necessary. To help tailor the model architecture, design a custom network when you have strict constraints on model size, inference speed, or memory usage. For an example of how to create a custom semantic segmentation network, see the Create a Semantic Segmentation Network example.
Configure Training Options
Configure the training options using the trainingOptions (Deep Learning Toolbox) function. Specify the number of epochs and the
mini-batch size based on your available computing resources.
Train Network
Train the network on the training datastore, with the specified training options,
using the trainnet (Deep Learning Toolbox) function. Specify an untrained or a pretrained network as a
dlnetwork (Deep Learning Toolbox) to the
trainnet function to perform transfer learning. For most
multi-class segmentation tasks, specify categorical cross-entropy loss as the loss
function to the trainnet function using
"cross-entropy" or a function handle with crossentropy (Deep Learning Toolbox). The loss function must contain a metric that
quantifies the difference between the predicted segmentation map and the ground
truth labels. For example, you can also use the generalizedDice function to calculate the generalized Dice
loss.
For an example of how to train a simple custom segmentation network, see the Train a Semantic Segmentation Network example.
Evaluate Semantic Segmentation Results
Evaluate the quality of your instance segmentation results against the ground truth by
using the evaluateSemanticSegmentation function. Ensure that your predicted pixel
label datastore and ground truth datastore is set up so that using the read function on the datastores returns a categorical array, a cell
array, or a table. If the read function returns a multicolumn cell
array or table, the second column must contain categorical arrays.
To calculate the prediction metrics, specify predicted pixel label datastore and your
ground truth datastore as inputs to the
evaluateSemanticSegmentation function. The function calculates
metrics such as the confusion matrix and average precision, and stores the metrics in an
semanticSegmentationMetrics object.
For an example of how to use the semantic segmentation metrics to evaluate your results, see these examples:
See Also
Apps
- Image Labeler | Video Labeler | Ground Truth Labeler (Automated Driving Toolbox) | Medical Image Labeler (Medical Imaging Toolbox)
Functions
semanticseg|bisenetv2|unet|unet3d|deeplabv3plus|dlnetwork(Deep Learning Toolbox) |pixelLabelDatastore|evaluateSemanticSegmentation|semanticSegmentationMetrics|segmentationConfusionMatrix|generalizedDice
See Also
Topics
- Get Started with Image Segmentation
- Augment Pixel Labels for Semantic Segmentation
- Import Pixel Labeled Dataset for Semantic Segmentation
- Automatically Label Ground Truth Using Segment Anything Model
- Label Pixels for Semantic Segmentation
- Semantic Segmentation Using Deep Learning
- Semantic Segmentation Using Dilated Convolutions
- Calculate Segmentation Metrics in Block-Based Workflow
- Explore Semantic Segmentation Network Using Grad-CAM
- Deep Learning in MATLAB (Deep Learning Toolbox)