fitrlinear
Fit linear regression model to high-dimensional data
Syntax
Description
fitrlinear efficiently trains linear regression models with high-dimensional, full or sparse predictor data. Available linear regression models include regularized support vector machines (SVM) and least-squares regression methods. fitrlinear minimizes the objective function using techniques that reduce computing time (e.g., stochastic gradient descent).
For reduced computation time on a high-dimensional data set that includes many predictor variables, train a linear regression model by using fitrlinear. For low- through medium-dimensional predictor data sets, see Alternatives for Lower-Dimensional Data.
Mdl = fitrlinear(Tbl,ResponseVarName)Tbl and the response values in Tbl.ResponseVarName.
Mdl = fitrlinear(X,Y,Name,Value)'Kfold' name-value pair argument. The cross-validation results determine how well the model generalizes.
[
also returns the hyperparameter optimization results when you specify
Mdl,FitInfo,HyperparameterOptimizationResults] = fitrlinear(___)OptimizeHyperparameters.
[
also returns Mdl,FitInfo,AggregateOptimizationResults] = fitrlinear(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments.
You must also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this
syntax to optimize on compact model size instead of cross-validation loss, and
to perform a set of multiple optimization problems that have the same options
but different constraint bounds.
Examples
Train a linear regression model using SVM, dual SGD, and ridge regularization.
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Train a linear regression model. By default, fitrlinear uses support vector machines with a ridge penalty, and optimizes using dual SGD for SVM. Determine how well the optimization algorithm fit the model to the data by extracting a fit summary.
[Mdl,FitInfo] = fitrlinear(X,Y)
Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0056
Lambda: 1.0000e-04
Learner: 'svm'
Properties, Methods
FitInfo = struct with fields:
Lambda: 1.0000e-04
Objective: 0.2725
PassLimit: 10
NumPasses: 10
BatchLimit: []
NumIterations: 100000
GradientNorm: NaN
GradientTolerance: 0
RelativeChangeInBeta: 0.4907
BetaTolerance: 1.0000e-04
DeltaGradient: 1.5816
DeltaGradientTolerance: 0.1000
TerminationCode: 0
TerminationStatus: {'Iteration limit exceeded.'}
Alpha: [10000×1 double]
History: []
FitTime: 0.0539
Solver: {'dual'}
Mdl is a RegressionLinear model. You can pass Mdl and the training or new data to loss to inspect the in-sample mean-squared error. Or, you can pass Mdl and new predictor data to predict to predict responses for new observations.
FitInfo is a structure array containing, among other things, the termination status (TerminationStatus) and how long the solver took to fit the model to the data (FitTime). It is good practice to use FitInfo to determine whether optimization-termination measurements are satisfactory. In this case, fitrlinear reached the maximum number of iterations. Because training time is fast, you can retrain the model, but increase the number of passes through the data. Or, try another solver, such as LBFGS.
To determine a good lasso-penalty strength for a linear regression model that uses least squares, implement 5-fold cross-validation.
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Create a set of 15 logarithmically-spaced regularization strengths from through .
Lambda = logspace(-5,-1,15);
Cross-validate the models. To increase execution speed, transpose the predictor data and specify that the observations are in columns. Optimize the objective function using SpaRSA.
X = X'; CVMdl = fitrlinear(X,Y,'ObservationsIn','columns','KFold',5,'Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numCLModels = numel(CVMdl.Trained)
numCLModels = 5
CVMdl is a RegressionPartitionedLinear model. Because fitrlinear implements 5-fold cross-validation, CVMdl contains 5 RegressionLinear models that the software trains on each fold.
Display the first trained linear regression model.
Mdl1 = CVMdl.Trained{1}Mdl1 =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×15 double]
Bias: [-0.0049 -0.0049 -0.0049 -0.0049 -0.0049 -0.0048 -0.0044 -0.0037 -0.0030 -0.0031 -0.0033 -0.0036 -0.0041 -0.0051 -0.0071]
Lambda: [1.0000e-05 1.9307e-05 3.7276e-05 7.1969e-05 1.3895e-04 2.6827e-04 5.1795e-04 1.0000e-03 0.0019 0.0037 0.0072 0.0139 0.0268 0.0518 0.1000]
Learner: 'leastsquares'
Properties, Methods
Mdl1 is a RegressionLinear model object. fitrlinear constructed Mdl1 by training on the first four folds. Because Lambda is a sequence of regularization strengths, you can think of Mdl1 as 15 models, one for each regularization strength in Lambda.
Estimate the cross-validated MSE.
mse = kfoldLoss(CVMdl);
Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a regression model. For each regularization strength, train a linear regression model using the entire data set and the same options as when you cross-validated the models. Determine the number of nonzero coefficients per model.
Mdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numNZCoeff = sum(Mdl.Beta~=0);
In the same figure, plot the cross-validated MSE and frequency of nonzero coefficients for each regularization strength. Plot all variables on the log scale.
figure [h,hL1,hL2] = plotyy(log10(Lambda),log10(mse),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} MSE') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') hold off
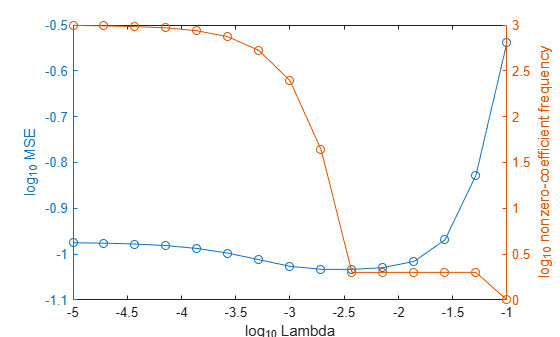
Choose the index of the regularization strength that balances predictor variable sparsity and low MSE (for example, Lambda(10)).
idxFinal = 10;
Extract the model with corresponding to the minimal MSE.
MdlFinal = selectModels(Mdl,idxFinal)
MdlFinal =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0050
Lambda: 0.0037
Learner: 'leastsquares'
Properties, Methods
idxNZCoeff = find(MdlFinal.Beta~=0)
idxNZCoeff = 2×1
100
200
EstCoeff = Mdl.Beta(idxNZCoeff)
EstCoeff = 2×1
1.0051
1.9965
MdlFinal is a RegressionLinear model with one regularization strength. The nonzero coefficients EstCoeff are close to the coefficients that simulated the data.
This example shows how to optimize hyperparameters automatically using fitrlinear. The example uses artificial (simulated) data for the model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Find hyperparameters that minimize five-fold cross validation loss by using automatic hyperparameter optimization.
For reproducibility, use the 'expected-improvement-plus' acquisition function.
hyperopts = struct('AcquisitionFunctionName','expected-improvement-plus'); [Mdl,FitInfo,HyperparameterOptimizationResults] = fitrlinear(X,Y,... 'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',hyperopts)
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Lambda | Learner |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 1 | Best | 0.10584 | 1.5884 | 0.10584 | 0.10584 | 2.4206e-09 | svm |
| 2 | Best | 0.10564 | 1.4292 | 0.10564 | 0.10564 | 0.001807 | svm |
| 3 | Best | 0.10091 | 0.38718 | 0.10091 | 0.10092 | 2.4681e-09 | leastsquares |
| 4 | Accept | 0.11397 | 0.30181 | 0.10091 | 0.10094 | 0.021027 | leastsquares |
| 5 | Accept | 0.10091 | 0.37456 | 0.10091 | 0.10091 | 2.0258e-09 | leastsquares |
| 6 | Accept | 0.45312 | 0.54484 | 0.10091 | 0.10091 | 9.8803 | svm |
| 7 | Accept | 0.10582 | 1.2122 | 0.10091 | 0.10091 | 9.6038e-06 | svm |
| 8 | Best | 0.10091 | 0.37696 | 0.10091 | 0.10087 | 1.6009e-05 | leastsquares |
| 9 | Accept | 0.44998 | 0.19055 | 0.10091 | 0.10089 | 9.9615 | leastsquares |
| 10 | Best | 0.10069 | 0.36864 | 0.10069 | 0.10067 | 0.00079258 | leastsquares |
| 11 | Accept | 0.10586 | 1.1421 | 0.10069 | 0.10065 | 9.7512e-08 | svm |
| 12 | Accept | 0.10091 | 0.359 | 0.10069 | 0.10085 | 3.0897e-07 | leastsquares |
| 13 | Accept | 0.10577 | 1.2015 | 0.10069 | 0.10085 | 0.00019626 | svm |
| 14 | Best | 0.10062 | 0.36292 | 0.10062 | 0.10043 | 0.0037706 | leastsquares |
| 15 | Accept | 0.10091 | 0.40852 | 0.10062 | 0.10085 | 2.4399e-08 | leastsquares |
| 16 | Accept | 0.10091 | 0.38087 | 0.10062 | 0.10087 | 2.4005e-06 | leastsquares |
| 17 | Accept | 0.10091 | 0.32277 | 0.10062 | 0.10089 | 1.0029e-09 | leastsquares |
| 18 | Accept | 0.10584 | 1.1288 | 0.10062 | 0.10089 | 1.0049e-09 | svm |
| 19 | Accept | 0.10088 | 0.34766 | 0.10062 | 0.10089 | 0.00010204 | leastsquares |
| 20 | Accept | 0.10583 | 1.1832 | 0.10062 | 0.10089 | 9.8999e-07 | svm |
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Lambda | Learner |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 21 | Best | 0.10052 | 0.33263 | 0.10052 | 0.10025 | 0.002124 | leastsquares |
| 22 | Accept | 0.10091 | 0.32723 | 0.10052 | 0.10024 | 8.7079e-08 | leastsquares |
| 23 | Best | 0.10052 | 0.31501 | 0.10052 | 0.10033 | 0.0021352 | leastsquares |
| 24 | Accept | 0.10091 | 0.32383 | 0.10052 | 0.10033 | 8.0672e-09 | leastsquares |
| 25 | Accept | 0.10052 | 0.33733 | 0.10052 | 0.10038 | 0.0021099 | leastsquares |
| 26 | Accept | 0.10091 | 0.3751 | 0.10052 | 0.10038 | 8.5163e-07 | leastsquares |
| 27 | Accept | 0.1009 | 0.40716 | 0.10052 | 0.10038 | 3.8212e-05 | leastsquares |
| 28 | Accept | 0.31858 | 0.94709 | 0.10052 | 0.10046 | 0.17205 | svm |
| 29 | Accept | 0.10574 | 1.2253 | 0.10052 | 0.10047 | 0.00070859 | svm |
| 30 | Accept | 0.10082 | 0.32635 | 0.10052 | 0.10047 | 0.00028825 | leastsquares |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 32.0065 seconds
Total objective function evaluation time: 18.5287
Best observed feasible point:
Lambda Learner
_________ ____________
0.0021352 leastsquares
Observed objective function value = 0.10052
Estimated objective function value = 0.10047
Function evaluation time = 0.31501
Best estimated feasible point (according to models):
Lambda Learner
_________ ____________
0.0021352 leastsquares
Estimated objective function value = 0.10047
Estimated function evaluation time = 0.33572
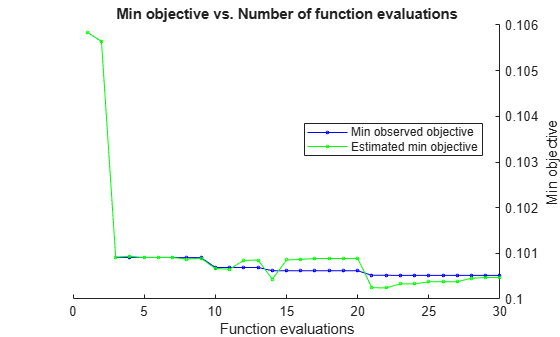
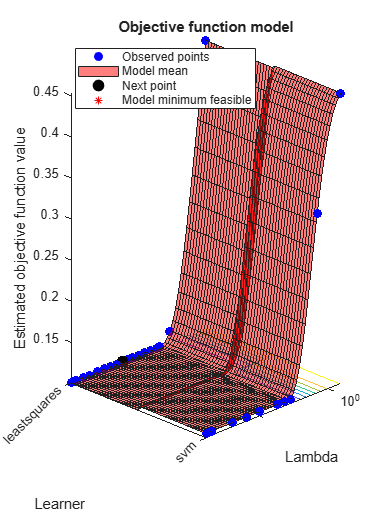
Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0071
Lambda: 0.0021
Learner: 'leastsquares'
Properties, Methods
FitInfo = struct with fields:
Lambda: 0.0021
Objective: 0.0472
IterationLimit: 1000
NumIterations: 15
GradientNorm: 2.4347e-06
GradientTolerance: 1.0000e-06
RelativeChangeInBeta: 3.3860e-05
BetaTolerance: 1.0000e-04
DeltaGradient: []
DeltaGradientTolerance: []
TerminationCode: 1
TerminationStatus: {'Tolerance on coefficients satisfied.'}
History: []
FitTime: 0.0776
Solver: {'lbfgs'}
HyperparameterOptimizationResults =
SupervisedLearningBayesianOptimization
ObjectiveFcn: @createObjFcn/inMemoryObjFcn
VariableDescriptions: [3×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 0.1005
XAtMinObjective: [1×2 table]
MinEstimatedObjective: 0.1005
XAtMinEstimatedObjective: [1×2 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 32.0065
NextPoint: [1×2 table]
XTrace: [30×2 table]
ObjectiveTrace: [30×1 double]
LossFun: 'mse'
LossTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
This optimization technique is simpler than that shown in Find Good Lasso Penalty Using Cross-Validation, but does not allow you to trade off model complexity and cross-validation loss.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
It is a best practice to orient your predictor matrix so that observations correspond to columns and to specify
'ObservationsIn','columns'. As a result, you can experience a significant reduction in optimization-execution time.If your predictor data has few observations but many predictor variables, then:
Specify
'PostFitBias',true.For SGD or ASGD solvers, set
PassLimitto a positive integer that is greater than 1, for example, 5 or 10. This setting often results in better accuracy.
For SGD and ASGD solvers,
BatchSizeaffects the rate of convergence.If
BatchSizeis too small, thenfitrlinearachieves the minimum in many iterations, but computes the gradient per iteration quickly.If
BatchSizeis too large, thenfitrlinearachieves the minimum in fewer iterations, but computes the gradient per iteration slowly.
Large learning rates (see
LearnRate) speed up convergence to the minimum, but can lead to divergence (that is, over-stepping the minimum). Small learning rates ensure convergence to the minimum, but can lead to slow termination.When using lasso penalties, experiment with various values of
TruncationPeriod. For example, setTruncationPeriodto1,10, and then100.For efficiency,
fitrlineardoes not standardize predictor data. To standardizeXwhere you orient the observations as the columns, enterX = normalize(X,2);
If you orient the observations as the rows, enter
X = normalize(X);
For memory-usage economy, the code replaces the original predictor data the standardized data.
After training a model, you can generate C/C++ code that predicts responses for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
If you specify
ValidationData, then, during objective-function optimization:fitrlinearestimates the validation loss ofValidationDataperiodically using the current model, and tracks the minimal estimate.When
fitrlinearestimates a validation loss, it compares the estimate to the minimal estimate.When subsequent, validation loss estimates exceed the minimal estimate five times,
fitrlinearterminates optimization.
If you specify
ValidationDataand to implement a cross-validation routine (CrossVal,CVPartition,Holdout, orKFold), then:fitrlinearrandomly partitionsXandY(orTbl) according to the cross-validation routine that you choose.fitrlineartrains the model using the training-data partition. During objective-function optimization,fitrlinearusesValidationDataas another possible way to terminate optimization (for details, see the previous bullet).Once
fitrlinearsatisfies a stopping criterion, it constructs a trained model based on the optimized linear coefficients and intercept.If you implement k-fold cross-validation, and
fitrlinearhas not exhausted all training-set folds, thenfitrlinearreturns to Step 2 to train using the next training-set fold.Otherwise,
fitrlinearterminates training, and then returns the cross-validated model.
You can determine the quality of the cross-validated model. For example:
To determine the validation loss using the holdout or out-of-fold data from step 1, pass the cross-validated model to
kfoldLoss.To predict observations on the holdout or out-of-fold data from step 1, pass the cross-validated model to
kfoldPredict.
References
[1] Ho, C. H. and C. J. Lin. “Large-Scale Linear Support Vector Regression.” Journal of Machine Learning Research, Vol. 13, 2012, pp. 3323–3348.
Extended Capabilities
Version History
Introduced in R2016aSee Also
fitrsvm | fitlm | lasso | ridge | fitclinear | predict | kfoldPredict | kfoldLoss | RegressionLinear | RegressionPartitionedLinear