fitckernel
Fit binary Gaussian kernel classifier using random feature expansion
Syntax
Description
fitckernel trains or cross-validates a binary Gaussian
kernel classification model for nonlinear classification.
fitckernel is more practical for big data applications that
have large training sets but can also be applied to smaller data sets that fit in
memory.
fitckernel maps data in a low-dimensional space into a
high-dimensional space, then fits a linear model in the high-dimensional space by
minimizing the regularized objective function. Obtaining the linear model in the
high-dimensional space is equivalent to applying the Gaussian kernel to the model in the
low-dimensional space. Available linear classification models include regularized
support vector machine (SVM) and logistic regression models.
To train a nonlinear SVM model for binary classification of in-memory data, see
fitcsvm.
Mdl = fitckernel(X,Y)X and the corresponding class labels in
Y. The fitckernel function maps
the predictors in a low-dimensional space into a high-dimensional space, then
fits a binary SVM model to the transformed predictors and class labels. This
linear model is equivalent to the Gaussian kernel classification model in the
low-dimensional space.
Mdl = fitckernel(Tbl,ResponseVarName)Mdl trained using the
predictor variables contained in the table Tbl and the
class labels in Tbl.ResponseVarName.
Mdl = fitckernel(___,Name,Value)
[
also returns the hyperparameter optimization results when you specify
Mdl,FitInfo,HyperparameterOptimizationResults] = fitckernel(___)OptimizeHyperparameters.
[
also returns Mdl,FitInfo,AggregateOptimizationResults] = fitckernel(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments.
You must also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this
syntax to optimize on compact model size instead of cross-validation loss, and
to perform a set of multiple optimization problems that have the same options
but different constraint bounds.
Examples
Train a binary kernel classification model using SVM.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphere
[n,p] = size(X)n = 351
p = 34
resp = unique(Y)
resp = 2×1 cell
{'b'}
{'g'}
Train a binary kernel classification model that identifies whether the radar return is bad ('b') or good ('g'). Extract a fit summary to determine how well the optimization algorithm fits the model to the data.
rng('default') % For reproducibility [Mdl,FitInfo] = fitckernel(X,Y)
Mdl =
ClassificationKernel
ResponseName: 'Y'
ClassNames: {'b' 'g'}
Learner: 'svm'
NumExpansionDimensions: 2048
KernelScale: 1
Lambda: 0.0028
BoxConstraint: 1
Properties, Methods
FitInfo = struct with fields:
Solver: 'LBFGS-fast'
LossFunction: 'hinge'
Lambda: 0.0028
BetaTolerance: 1.0000e-04
GradientTolerance: 1.0000e-06
ObjectiveValue: 0.2604
GradientMagnitude: 0.0028
RelativeChangeInBeta: 8.2512e-05
FitTime: 0.0670
History: []
Mdl is a ClassificationKernel model. To inspect the in-sample classification error, you can pass Mdl and the training data or new data to the loss function. Or, you can pass Mdl and new predictor data to the predict function to predict class labels for new observations. You can also pass Mdl and the training data to the resume function to continue training.
FitInfo is a structure array containing optimization information. Use FitInfo to determine whether optimization termination measurements are satisfactory.
For better accuracy, you can increase the maximum number of optimization iterations ('IterationLimit') and decrease the tolerance values ('BetaTolerance' and 'GradientTolerance') by using the name-value pair arguments. Doing so can improve measures like ObjectiveValue and RelativeChangeInBeta in FitInfo. You can also optimize model parameters by using the 'OptimizeHyperparameters' name-value pair argument.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphere rng('default') % For reproducibility
Cross-validate a binary kernel classification model. By default, the software uses 10-fold cross-validation.
CVMdl = fitckernel(X,Y,'CrossVal','on')
CVMdl =
ClassificationPartitionedKernel
CrossValidatedModel: 'Kernel'
ResponseName: 'Y'
NumObservations: 351
KFold: 10
Partition: [1×1 cvpartition]
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Properties, Methods
numel(CVMdl.Trained)
ans = 10
CVMdl is a ClassificationPartitionedKernel model. Because fitckernel implements 10-fold cross-validation, CVMdl contains 10 ClassificationKernel models that the software trains on training-fold (in-fold) observations.
Estimate the cross-validated classification error.
kfoldLoss(CVMdl)
ans = 0.0940
The classification error rate is approximately 9%.
Optimize hyperparameters automatically using the OptimizeHyperparameters name-value argument.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphereFind hyperparameters that minimize five-fold cross-validation loss by using automatic hyperparameter optimization. Specify OptimizeHyperparameters as 'auto' so that fitckernel finds optimal values of the KernelScale, Lambda, and Standardize name-value arguments. For reproducibility, set the random seed and use the 'expected-improvement-plus' acquisition function.
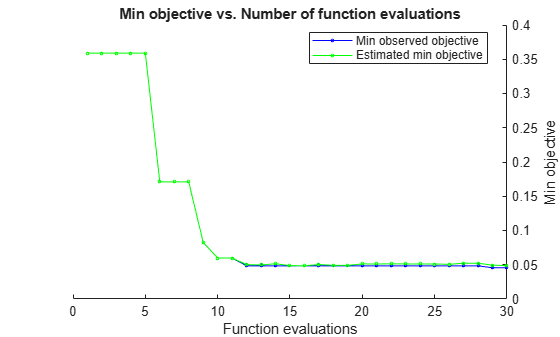
rng('default') [Mdl,FitInfo,HyperparameterOptimizationResults] = fitckernel(X,Y,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName','expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | KernelScale | Lambda | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 1 | Best | 0.35897 | 1.0989 | 0.35897 | 0.35897 | 3.8653 | 2.7394 | true |
| 2 | Accept | 0.35897 | 0.19983 | 0.35897 | 0.35897 | 429.99 | 0.0006775 | false |
| 3 | Accept | 0.35897 | 0.46283 | 0.35897 | 0.35897 | 0.11801 | 0.025493 | false |
| 4 | Accept | 0.41311 | 0.44156 | 0.35897 | 0.35898 | 0.0010694 | 9.1346e-06 | true |
| 5 | Accept | 0.4245 | 0.43444 | 0.35897 | 0.35898 | 0.0093918 | 2.8526e-06 | false |
| 6 | Best | 0.17094 | 0.32368 | 0.17094 | 0.17102 | 15.285 | 0.0038931 | false |
| 7 | Accept | 0.18234 | 0.31235 | 0.17094 | 0.17099 | 9.9078 | 0.0090818 | false |
| 8 | Accept | 0.35897 | 0.22198 | 0.17094 | 0.17097 | 26.961 | 0.46727 | false |
| 9 | Best | 0.082621 | 0.43261 | 0.082621 | 0.082677 | 7.7184 | 0.0025676 | false |
| 10 | Best | 0.059829 | 0.61709 | 0.059829 | 0.059839 | 5.6125 | 0.0013416 | false |
| 11 | Accept | 0.062678 | 0.62037 | 0.059829 | 0.059793 | 7.3294 | 0.00062394 | false |
| 12 | Best | 0.048433 | 0.93143 | 0.048433 | 0.050198 | 3.7772 | 0.00032964 | false |
| 13 | Accept | 0.051282 | 0.73324 | 0.048433 | 0.049662 | 3.4417 | 0.00077524 | false |
| 14 | Accept | 0.054131 | 0.73928 | 0.048433 | 0.051494 | 4.3694 | 0.00055199 | false |
| 15 | Accept | 0.051282 | 0.96946 | 0.048433 | 0.04872 | 1.7463 | 0.00012886 | false |
| 16 | Accept | 0.048433 | 0.71638 | 0.048433 | 0.048475 | 3.9086 | 3.1147e-05 | false |
| 17 | Accept | 0.054131 | 0.86538 | 0.048433 | 0.050325 | 3.1489 | 9.1315e-05 | false |
| 18 | Accept | 0.051282 | 0.65002 | 0.048433 | 0.049131 | 2.3414 | 4.8238e-06 | false |
| 19 | Accept | 0.062678 | 0.93699 | 0.048433 | 0.049062 | 7.2203 | 3.2694e-06 | false |
| 20 | Accept | 0.054131 | 0.56964 | 0.048433 | 0.051225 | 3.5381 | 1.0341e-05 | false |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | KernelScale | Lambda | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 21 | Accept | 0.068376 | 0.55637 | 0.048433 | 0.05111 | 1.4267 | 1.7614e-05 | false |
| 22 | Accept | 0.054131 | 0.72054 | 0.048433 | 0.05127 | 3.2173 | 2.9573e-06 | false |
| 23 | Accept | 0.05698 | 0.83249 | 0.048433 | 0.051187 | 2.4241 | 0.0003272 | false |
| 24 | Accept | 0.059829 | 0.96871 | 0.048433 | 0.051097 | 2.5948 | 4.5059e-05 | false |
| 25 | Accept | 0.059829 | 0.56318 | 0.048433 | 0.051018 | 7.2989 | 2.6908e-05 | false |
| 26 | Accept | 0.068376 | 1.0088 | 0.048433 | 0.048938 | 3.9585 | 6.9173e-06 | false |
| 27 | Accept | 0.05698 | 0.92743 | 0.048433 | 0.051222 | 4.2751 | 0.0002231 | false |
| 28 | Accept | 0.062678 | 0.44954 | 0.048433 | 0.051232 | 1.4533 | 2.8533e-06 | false |
| 29 | Accept | 0.051282 | 0.67025 | 0.048433 | 0.051122 | 3.8449 | 0.00059747 | false |
| 30 | Accept | 0.21083 | 0.92541 | 0.048433 | 0.0512 | 45.588 | 3.056e-06 | false |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 26.8064 seconds
Total objective function evaluation time: 19.9001
Best observed feasible point:
KernelScale Lambda Standardize
___________ __________ ___________
3.7772 0.00032964 false
Observed objective function value = 0.048433
Estimated objective function value = 0.05162
Function evaluation time = 0.93143
Best estimated feasible point (according to models):
KernelScale Lambda Standardize
___________ __________ ___________
3.8449 0.00059747 false
Estimated objective function value = 0.0512
Estimated function evaluation time = 0.75141
Mdl =
ClassificationKernel
ResponseName: 'Y'
ClassNames: {'b' 'g'}
Learner: 'svm'
NumExpansionDimensions: 2048
KernelScale: 3.8449
Lambda: 5.9747e-04
BoxConstraint: 4.7684
Properties, Methods
FitInfo = struct with fields:
Solver: 'LBFGS-fast'
LossFunction: 'hinge'
Lambda: 5.9747e-04
BetaTolerance: 1.0000e-04
GradientTolerance: 1.0000e-06
ObjectiveValue: 0.1006
GradientMagnitude: 0.0114
RelativeChangeInBeta: 9.3027e-05
FitTime: 0.1684
History: []
HyperparameterOptimizationResults =
SupervisedLearningBayesianOptimization
ObjectiveFcn: @createObjFcn/inMemoryObjFcn
VariableDescriptions: [5×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 0.0484
XAtMinObjective: [1×3 table]
MinEstimatedObjective: 0.0512
XAtMinEstimatedObjective: [1×3 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 26.8064
NextPoint: [1×3 table]
XTrace: [30×3 table]
ObjectiveTrace: [30×1 double]
LossFun: 'classiferror'
LossTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
For big data, the optimization procedure can take a long time. If the data set is too large to run the optimization procedure, you can try to optimize the parameters using only partial data. Use the datasample function and specify 'Replace','false' to sample data without replacement.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Standardizing predictors before training a model can be helpful.
You can standardize training data and scale test data to have the same scale as the training data by using the
normalizefunction.Alternatively, use the
Standardizename-value argument to standardize the numeric predictors before training. The returned model includes the predictor means and standard deviations in itsMuandSigmaproperties, respectively. (since R2023b)
After training a model, you can generate C/C++ code that predicts labels for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
fitckernelminimizes the regularized objective function using a Limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) solver with ridge (L2) regularization. To find the type of LBFGS solver used for training, typeFitInfo.Solverin the Command Window.'LBFGS-fast'— LBFGS solver.'LBFGS-blockwise'— LBFGS solver with a block-wise strategy. Iffitckernelrequires more memory than the value ofBlockSizeto hold the transformed predictor data, then the function uses a block-wise strategy.'LBFGS-tall'— LBFGS solver with a block-wise strategy for tall arrays.
When
fitckerneluses a block-wise strategy, it implements LBFGS by distributing the calculation of the loss and gradient among different parts of the data at each iteration. Also,fitckernelrefines the initial estimates of the linear coefficients and the bias term by fitting the model locally to parts of the data and combining the coefficients by averaging. If you specify'Verbose',1, thenfitckerneldisplays diagnostic information for each data pass and stores the information in theHistoryfield ofFitInfo.When
fitckerneldoes not use a block-wise strategy, the initial estimates are zeros. If you specify'Verbose',1, thenfitckerneldisplays diagnostic information for each iteration and stores the information in theHistoryfield ofFitInfo.If you specify the
Cost,Prior, andWeightsname-value arguments, the output model object stores the specified values in theCost,Prior, andWproperties, respectively. TheCostproperty stores the user-specified cost matrix (C) without modification. ThePriorandWproperties store the prior probabilities and observation weights, respectively, after normalization. For model training, the software updates the prior probabilities and observation weights to incorporate the penalties described in the cost matrix. For details, see Misclassification Cost Matrix, Prior Probabilities, and Observation Weights.