ClassificationTree
Binary decision tree for multiclass classification
Description
A ClassificationTree object represents a
decision tree with binary splits for classification. An object of this class can predict
responses for new data using predict. The object contains the data used
for training, so it can also compute resubstitution predictions using resubPredict.
Creation
Create a ClassificationTree object by using fitctree.
Properties
Object Functions
compact | Reduce size of machine learning model |
compareHoldout | Compare accuracies of two classification models using new data |
crossval | Cross-validate machine learning model |
cvloss | Classification error by cross-validation for classification tree model |
edge | Classification edge for classification tree model |
gather | Gather properties of Statistics and Machine Learning Toolbox object from GPU |
lime | Local interpretable model-agnostic explanations (LIME) |
loss | Classification loss for classification tree model |
margin | Classification margins for classification tree model |
nodeVariableRange | Retrieve variable range of decision tree node |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict | Predict labels using classification tree model |
predictorImportance | Estimates of predictor importance for classification tree |
prune | Produce sequence of classification subtrees by pruning classification tree |
resubEdge | Resubstitution classification edge for classification tree model |
resubLoss | Resubstitution classification loss for classification tree model |
resubMargin | Resubstitution classification margins for classification tree model |
resubPredict | Classify observations in classification tree by resubstitution |
shapley | Shapley values |
surrogateAssociation | Mean predictive measure of association for surrogate splits in classification tree |
testckfold | Compare accuracies of two classification models by repeated cross-validation |
view | View classification tree |
Examples
Grow a classification tree using the ionosphere data set.
load ionosphere
tc = fitctree(X,Y)tc =
ClassificationTree
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
Properties, Methods
You can control the depth of the trees using the MaxNumSplits, MinLeafSize, or MinParentSize name-value pair parameters. fitctree grows deep decision trees by default. You can grow shallower trees to reduce model complexity or computation time.
Load the ionosphere data set.
load ionosphereThe default values of the tree depth controllers for growing classification trees are:
n - 1forMaxNumSplits.nis the training sample size.1forMinLeafSize.10forMinParentSize.
These default values tend to grow deep trees for large training sample sizes.
Train a classification tree using the default values for tree depth control. Cross-validate the model by using 10-fold cross-validation.
rng(1); % For reproducibility MdlDefault = fitctree(X,Y,'CrossVal','on');
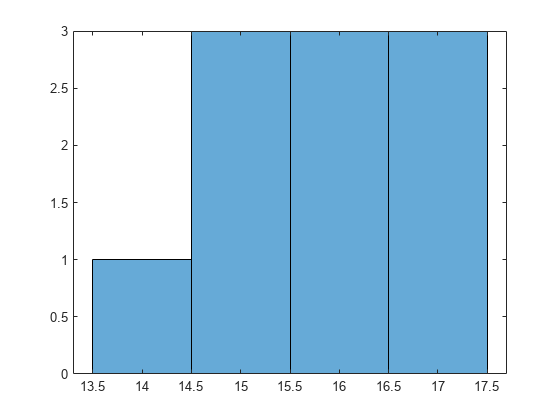
Draw a histogram of the number of imposed splits on the trees. Also, view one of the trees.
numBranches = @(x)sum(x.IsBranch); mdlDefaultNumSplits = cellfun(numBranches, MdlDefault.Trained); figure; histogram(mdlDefaultNumSplits)
view(MdlDefault.Trained{1},'Mode','graph')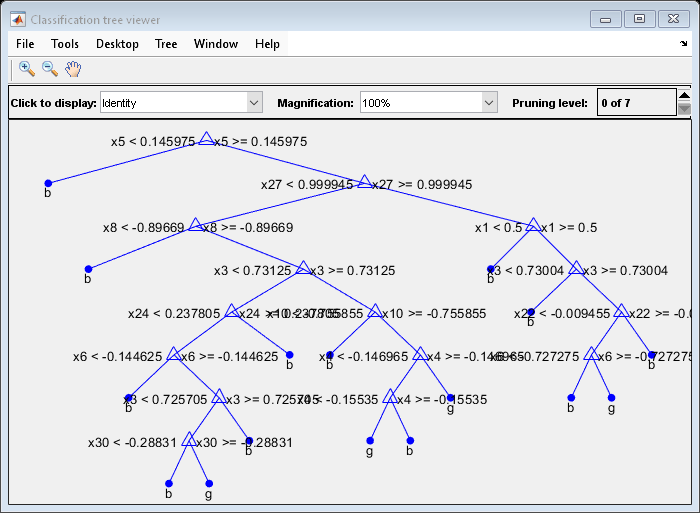
The average number of splits is around 15.
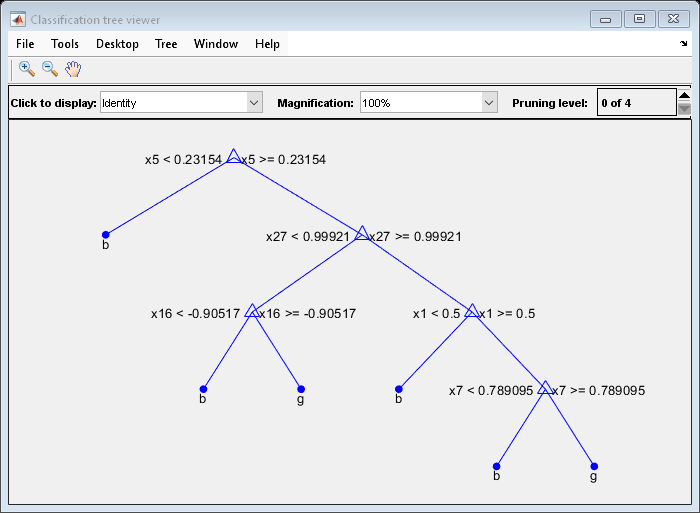
Suppose that you want a classification tree that is not as complex (deep) as the ones trained using the default number of splits. Train another classification tree, but set the maximum number of splits at 7, which is about half the mean number of splits from the default classification tree. Cross-validate the model by using 10-fold cross-validation.
Mdl7 = fitctree(X,Y,'MaxNumSplits',7,'CrossVal','on'); view(Mdl7.Trained{1},'Mode','graph')
Compare the cross-validation classification errors of the models.
classErrorDefault = kfoldLoss(MdlDefault)
classErrorDefault = 0.1168
classError7 = kfoldLoss(Mdl7)
classError7 = 0.1311
Mdl7 is much less complex and performs only slightly worse than MdlDefault.
More About
References
[1] Breiman, L., J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
Extended Capabilities
Version History
Introduced in R2011a