resubPredict
Classify observations in classification tree by resubstitution
Syntax
Description
Examples
Find the total number of misclassifications of the Fisher iris data for a classification tree.
load fisheriris tree = fitctree(meas,species); Ypredict = resubPredict(tree); % The predictions Ysame = strcmp(Ypredict,species); % True when == sum(~Ysame) % How many are different?
ans = 3
Load Fisher's iris data set. Partition the data into training (50%)
load fisheririsGrow a classification tree using the all petal measurements.
Mdl = fitctree(meas(:,3:4),species); n = size(meas,1); % Sample size K = numel(Mdl.ClassNames); % Number of classes
View the classification tree.
view(Mdl,'Mode','graph');
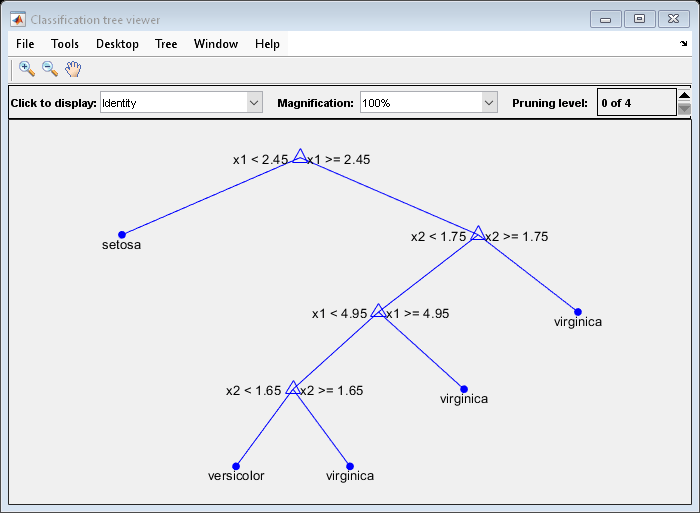
The classification tree has four pruning levels. Level 0 is the full, unpruned tree (as displayed). Level 4 is just the root node (i.e., no splits).
Estimate the posterior probabilities for each class using the subtrees pruned to levels 1 and 3.
[~,Posterior] = resubPredict(Mdl,'Subtrees',[1 3]);Posterior is an n-by- K-by- 2 array of posterior probabilities. Rows of Posterior correspond to observations, columns correspond to the classes with order Mdl.ClassNames, and pages correspond to pruning level.
Display the class posterior probabilities for iris 125 using each subtree.
Posterior(125,:,:)
ans =
ans(:,:,1) =
0 0.0217 0.9783
ans(:,:,2) =
0 0.5000 0.5000
The decision stump (page 2 of Posterior) has trouble predicting whether iris 125 is versicolor or virginica.
Classify a predictor X as true when X < 0.15 or X > 0.95, and as false otherwise.
Generate 100 uniformly distributed random numbers between 0 and 1, and classify them using a tree model.
rng("default") % For reproducibility X = rand(100,1); Y = (abs(X - 0.55) > 0.4); tree = fitctree(X,Y); view(tree,"Mode","graph")

Prune the tree.
tree1 = prune(tree,"Level",1); view(tree1,"Mode","graph")

The pruned tree correctly classifies observations that are less than 0.15 as true. It also correctly classifies observations from 0.15 to 0.95 as false. However, it incorrectly classifies observations that are greater than 0.95 as false. Therefore, the score for observations that are greater than 0.15 should be about 0.05/0.85=0.06 for true, and about 0.8/0.85=0.94 for false.
Compute the prediction scores (posterior probabilities) for the first 10 rows of X.
[~,score] = resubPredict(tree1); [score(1:10,:) X(1:10)]
ans = 10×3
0.9059 0.0941 0.8147
0.9059 0.0941 0.9058
0 1.0000 0.1270
0.9059 0.0941 0.9134
0.9059 0.0941 0.6324
0 1.0000 0.0975
0.9059 0.0941 0.2785
0.9059 0.0941 0.5469
0.9059 0.0941 0.9575
0.9059 0.0941 0.9649
Indeed, every value of X (the right-most column) that is less than 0.15 has associated scores (the left and center columns) of 0 and 1, while the other values of X have associated scores of approximately 0.91 and 0.09. The difference (score of 0.09 instead of the expected 0.06) is due to a statistical fluctuation: there are 8 observations in X in the range (0.95,1) instead of the expected 5 observations.
sum(X > 0.95)
ans = 8
Input Arguments
Output Arguments
More About
Extended Capabilities
Version History
Introduced in R2011a
See Also
resubEdge | resubMargin | resubLoss | predict | fitctree | ClassificationTree