System Integration of Deep Learning Processor IP Core
You can integrate the deep learning processor IP core into your system by:
Generating and integrating DL Processor IP Core—Generate a generic deep learning processor IP core by using Deep Learning HDL Toolbox. The generated deep learning processor IP core is a generic HDL Coder IP core with standard AXI4 interfaces. You can integrate the generated generic DL IP core into your Vivado® or Quartus® design.
Accelerate the integration of the generated DL processor IP core into your system design by:
Reading the AXI4 register maps in the generated IP core report. The AXI4 registers allow MATLAB® or other AXI4 Master devices to control and program the DL processor IP core.
Using the compiler generated external memory buffer allocation.
Formatting the input and output external memory data.

Reference design based DL Processor IP core integration—Generate a generic deep learning processor IP core by using Deep Learning HDL Toolbox. Integrate the generated deep learning processor IP core into your custom reference design by using HDL Coder. See Deploy IP Core on Custom Hardware (HDL Coder). You can design the pre-processing and post-processing DUT logic in Simulink® or MATLAB, and use the HDL Coder IP core generation workflow to integrate the pre-processing and post-processing logic with the deep learning processor.

Use MATLAB to run your custom deep learning network on the deep learning processor IP core and retrieve the deep learning network prediction results from you integrated system design.
Functions
Blocks
| Deep Learning HDL Processing System | Simulate deep learning processor IP core interface (Since R2023b) |
| Deep Learning HDL Int8 To Single Conversion | Convert 8-bit signed integer data to single-precision data (Since R2024b) |
| Deep Learning HDL Single To Int8 Conversion | Convert single-precision data to 8-bit signed integer data (Since R2024b) |
| Deep Learning HDL Handshake Interface | Model interface signals for data processing modes (Since R2026a) |
Topics
Generate and Integrate DL Processor IP Core
- Generate Custom Generic Deep Learning Processor IP Core
This example shows how to generate a custom generic deep learning processor IP core. - Deep Learning Processor IP Core
Learn about the generated deep learning processor IP core. - Use the Compiler Output for System Integration
Use the compiler outputs to integrate the generated deep learning processor IP core into your design. - Deep Learning Processor IP Core External Memory Data Format
Learn how to write, store, and read data from external memory for access by the Deep learning Processor IP core. - Deep Learning Processor IP Core Report
Learn about the generated files, register address mapping, and how to integrate the generated deep learning processor IP core. - Interface with the Deep Learning Processor IP Core
Choose between batch processing mode and streaming mode to process multiple data frames. - Initialize Deployed Deep Learning Processor Without Using a MATLAB Connection
Deploy your network and deep learning processor IP core to a custom file. Use a script to parse the created file and initialize your deployed network and deep learning processor IP core.
Reference Design-Based DL Processor IP Core Integration
- Deep Learning Processor IP Core Generation for Custom Board
This example shows how to create custom board and generate a deep learning processor IP core for the custom board.
Featured Examples

Run a Deep Learning Network on FPGA with Live Camera Input
Model preprocessing logic that receives a live camera input. You implement it on a Zynq® Ultrascale+™ MPSoC ZCU102 board by using a custom video reference design that has an integrated deep learning processor IP core for object classification. This example uses the HDL Coder™ HW/SW co-design workflow. For this example, you need:

Deploy Simple Adder Network by Using MATLAB Deployment Script and Deployment Instructions File
Create a .dln file for deploying a pretrained adder network. Deploy and initialize the generated deep learning processor IP core and adder network by using a MATLAB® deployment utility script to parse the generated .dln file.

Debug Deep Learning Processors by Reading Status Registers
Debug hardware stalls for a deployed ResNet-18 network by reading the debug register status information. You can emulate a hardware stall by sending incorrect data to the double data rate (DDR) memory. You can identify the layer that causes the stall by using the debug status register information.

Deploy and Verify YOLO v2 Vehicle Detector on FPGA
Deploy a you only look once (YOLO) v2 vehicle detector on FPGA and verify the end-to-end application using MATLAB.

Debug YOLO v2 Vehicle Detector on FPGA
Debug a vehicle detector design by viewing internal signals while the design is deployed on a board.

Integrate YOLO v2 Vehicle Detector System on SoC
Simulate a YOLO v2 vehicle detection algorithm that contains FPGA and ARM sections for deployment to an SoC device.

YOLO v2 Vehicle Detector with Live Camera Input on Zynq-Based Hardware
Deploy a YOLO v2 vehicle detection algorithm to the FPGA and ARM® processor on an SoC device and process live HDMI video input.
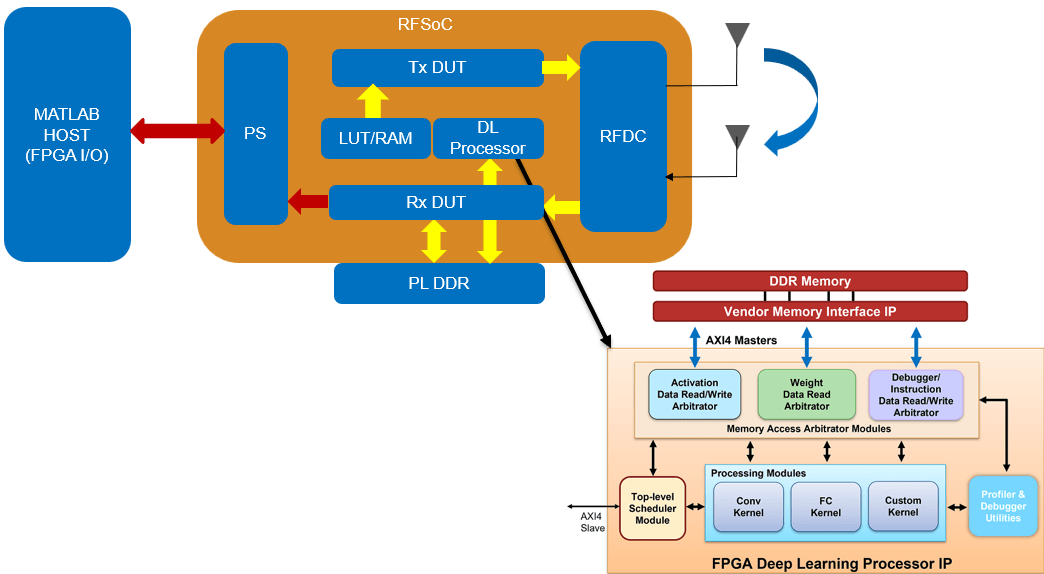
Deploy and Verify Modulation Classification on RFSoC Devices
Deploy pretrained CNN for modulation classification on AMD® RFSoC device.