knnsearch
Find k-nearest neighbors using input data
Description
Idx = knnsearch(X,Y,Name,Value)Idx with additional options specified using one or more
name-value pair arguments. For example, you can specify the number of nearest
neighbors to search for and the distance metric used in the search.
Examples
Find the patients in the hospital data set that most closely resemble the patients in Y, according to age and weight.
Load the hospital data set.
load hospital; X = [hospital.Age hospital.Weight]; Y = [20 162; 30 169; 40 168; 50 170; 60 171]; % New patients
Perform a knnsearch between X and Y to find indices of nearest neighbors.
Idx = knnsearch(X,Y);
Find the patients in X closest in age and weight to those in Y.
X(Idx,:)
ans = 5×2
25 171
25 171
39 164
49 170
50 172
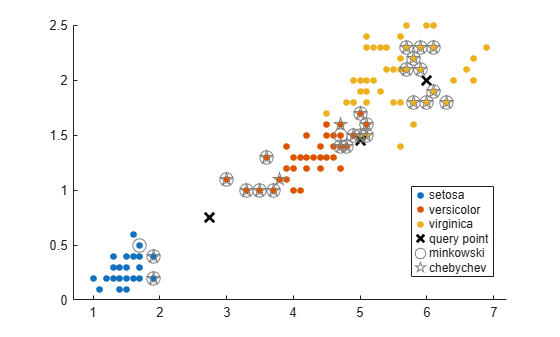
Find the 10 nearest neighbors in X to each point in Y, first using the Minkowski distance metric and then using the Chebychev distance metric.
Load Fisher's iris data set.
load fisheriris X = meas(:,3:4); % Measurements of original flowers Y = [5 1.45;6 2;2.75 .75]; % New flower data
Perform a knnsearch between X and the query points Y using Minkowski and Chebychev distance metrics.
[mIdx,mD] = knnsearch(X,Y,'K',10,'Distance','minkowski','P',5); [cIdx,cD] = knnsearch(X,Y,'K',10,'Distance','chebychev');
Visualize the results of the two nearest neighbor searches. Plot the training data. Plot the query points with the marker X. Use circles to denote the Minkowski nearest neighbors. Use pentagrams to denote the Chebychev nearest neighbors.
gscatter(X(:,1),X(:,2),species) line(Y(:,1),Y(:,2),'Marker','x','Color','k',... 'Markersize',10,'Linewidth',2,'Linestyle','none') line(X(mIdx,1),X(mIdx,2),'Color',[.5 .5 .5],'Marker','o',... 'Linestyle','none','Markersize',10) line(X(cIdx,1),X(cIdx,2),'Color',[.5 .5 .5],'Marker','p',... 'Linestyle','none','Markersize',10) legend('setosa','versicolor','virginica','query point',... 'minkowski','chebychev','Location','best')
Create two large matrices of points, and then measure the time used by knnsearch with the default "euclidean" distance metric.
rng default % For reproducibility N = 10000; X = randn(N,1000); Y = randn(N,1000); Idx = knnsearch(X,Y); % Warm up function for more reliable timing information tic Idx = knnsearch(X,Y); standard = toc
standard = 20.0400
Next, measure the time used by knnsearch with the "fasteuclidean" distance metric. Specify a cache size of 100.
Idx2 = knnsearch(X,Y,Distance="fasteuclidean",CacheSize=100); % Warm up function tic Idx2 = knnsearch(X,Y,Distance="fasteuclidean",CacheSize=100); accelerated = toc
accelerated = 2.0339
Evaluate how many times faster the accelerated computation is compared to the standard.
standard/accelerated
ans = 9.8531
The accelerated version is more than three times faster for this example.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
For a fixed positive integer k,
knnsearchfinds the k points inXthat are the nearest to each point inY. To find all points inXwithin a fixed distance of each point inY, userangesearch.knnsearchdoes not save a search object. To create a search object, usecreatens.
Algorithms
Alternative Functionality
If you set the knnsearch function's 'NSMethod'
name-value pair argument to the appropriate value ('exhaustive' for
an exhaustive search algorithm or 'kdtree' for a
Kd-tree algorithm), then the search results are equivalent to the
results obtained by conducting a distance search using the knnsearch object function. Unlike the knnsearch
function, the knnsearch object function requires an
ExhaustiveSearcher or a KDTreeSearcher model object.
Simulink Block
To integrate a k-nearest neighbor search into Simulink®, you can use the KNN Search
block in the Statistics and Machine Learning Toolbox™ library or a MATLAB Function block with the knnsearch function. For
an example, see Predict Class Labels Using MATLAB Function Block.
When deciding which approach to use, consider the following:
If you use the Statistics and Machine Learning Toolbox library block, you can use the Fixed-Point Tool (Fixed-Point Designer) to convert a floating-point model to fixed point.
Support for variable-size arrays must be enabled for a MATLAB Function block with the
knnsearchfunction.
References
[1] Albanie, Samuel. Euclidean Distance Matrix Trick. June, 2019. Available at https://samuelalbanie.com/files/Euclidean_distance_trick.pdf.
[2] Friedman, J. H., J. Bentley, and R. A. Finkel. “An Algorithm for Finding Best Matches in Logarithmic Expected Time.” ACM Transactions on Mathematical Software 3, no. 3 (1977): 209–226.