fscnca
Feature selection using neighborhood component analysis for classification
Syntax
Description
fscnca performs feature selection using neighborhood
component analysis (NCA) for classification.
To perform NCA-based feature selection for regression, see fsrnca.
mdl = fscnca(Tbl,ResponseVarName)Tbl.
ResponseVarName is the name of the variable in
Tbl that contains the class labels.
fscnca learns the feature weights by using a diagonal
adaptation of NCA with regularization.
mdl = fscnca(X,Y,Name,Value)
Examples
Generate toy data where the response variable depends on the 3rd, 9th, and 15th predictors.
rng(0,'twister'); % For reproducibility N = 100; X = rand(N,20); y = -ones(N,1); y(X(:,3).*X(:,9)./X(:,15) < 0.4) = 1;
Fit the neighborhood component analysis model for classification.
mdl = fscnca(X,y,'Solver','sgd','Verbose',1);
o Tuning initial learning rate: NumTuningIterations = 20, TuningSubsetSize = 100
|===============================================|
| TUNING | TUNING SUBSET | LEARNING |
| ITER | FUN VALUE | RATE |
|===============================================|
| 1 | -3.755936e-01 | 2.000000e-01 |
| 2 | -3.950971e-01 | 4.000000e-01 |
| 3 | -4.311848e-01 | 8.000000e-01 |
| 4 | -4.903195e-01 | 1.600000e+00 |
| 5 | -5.630190e-01 | 3.200000e+00 |
| 6 | -6.166993e-01 | 6.400000e+00 |
| 7 | -6.255669e-01 | 1.280000e+01 |
| 8 | -6.255669e-01 | 1.280000e+01 |
| 9 | -6.255669e-01 | 1.280000e+01 |
| 10 | -6.255669e-01 | 1.280000e+01 |
| 11 | -6.255669e-01 | 1.280000e+01 |
| 12 | -6.255669e-01 | 1.280000e+01 |
| 13 | -6.255669e-01 | 1.280000e+01 |
| 14 | -6.279210e-01 | 2.560000e+01 |
| 15 | -6.279210e-01 | 2.560000e+01 |
| 16 | -6.279210e-01 | 2.560000e+01 |
| 17 | -6.279210e-01 | 2.560000e+01 |
| 18 | -6.279210e-01 | 2.560000e+01 |
| 19 | -6.279210e-01 | 2.560000e+01 |
| 20 | -6.279210e-01 | 2.560000e+01 |
o Solver = SGD, MiniBatchSize = 10, PassLimit = 5
|==========================================================================================|
| PASS | ITER | AVG MINIBATCH | AVG MINIBATCH | NORM STEP | LEARNING |
| | | FUN VALUE | NORM GRAD | | RATE |
|==========================================================================================|
| 0 | 9 | -5.658450e-01 | 4.492407e-02 | 9.290605e-01 | 2.560000e+01 |
| 1 | 19 | -6.131382e-01 | 4.923625e-02 | 7.421541e-01 | 1.280000e+01 |
| 2 | 29 | -6.225056e-01 | 3.738784e-02 | 3.277588e-01 | 8.533333e+00 |
| 3 | 39 | -6.233366e-01 | 4.947901e-02 | 5.431133e-01 | 6.400000e+00 |
| 4 | 49 | -6.238576e-01 | 3.445763e-02 | 2.946188e-01 | 5.120000e+00 |
Two norm of the final step = 2.946e-01
Relative two norm of the final step = 6.588e-02, TolX = 1.000e-06
EXIT: Iteration or pass limit reached.
Plot the selected features. The weights of the irrelevant features should be close to zero.
figure() plot(mdl.FeatureWeights,'ro') grid on xlabel('Feature index') ylabel('Feature weight')
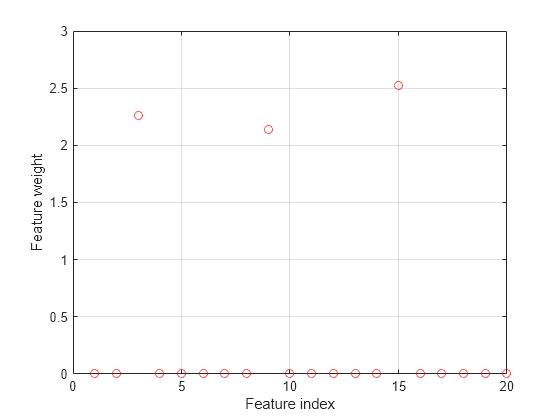
fscnca correctly detects the relevant features.
Load and partition the ovarian cancer data set, and determine if feature selection is necessary. Fit the model, plot the feature weights, and then classify observations using the selected features.
load ovariancancer;
whosName Size Bytes Class Attributes grp 216x1 26784 cell obs 216x4000 3456000 single
The obs variable consists of 216 observations with 4000 features. Each element in grp defines the group to which the corresponding row of obs belongs.
Use cvpartition to divide the data into a training set of size 160 and a test set of size 56. Both the training set and the test set have roughly the same group proportions as in grp.
rng(1,"twister"); % For reproducibility cvp = cvpartition(grp,Holdout=56)
cvp =
Hold-out cross validation partition
NumObservations: 216
NumTestSets: 1
TrainSize: 160
TestSize: 56
IsCustom: 0
IsGrouped: 0
IsStratified: 1
Properties, Methods
Xtrain = obs(cvp.training,:); ytrain = grp(cvp.training,:); Xtest = obs(cvp.test,:); ytest = grp(cvp.test,:);
To determine if feature selection is necessary, first compute the generalization error without fitting.
nca = fscnca(Xtrain,ytrain,FitMethod="none");
loss(nca,Xtest,ytest)ans = 0.0893
The software computes the generalization error of the neighborhood component analysis (NCA) feature selection model using the initial feature weights (in this case, the default feature weights) provided by fscnca.
Fit the NCA model without the regularization parameter (that is, Lambda = 0).
nca = fscnca(Xtrain,ytrain,FitMethod="exact",Lambda=0,... Solver="sgd",Standardize=true); loss(nca,Xtest,ytest)
ans = 0.0714
The improvement in the loss value suggests that feature selection is worthwhile. Tuning the regularization parameter (Lambda value) usually improves the results.
Tuning the regularization parameter for the NCA model means finding the Lambda value that produces the minimum classification loss. To tune the parameter using five-fold cross-validation:
1. Partition the training data into five folds and extract the number of validation (test) sets. For each fold, cvpartition assigns four-fifths of the data as a training set, and one-fifth of the data as a test set.
cvp = cvpartition(ytrain,KFold=5); numvalidsets = cvp.NumTestSets;
Assign Lambda values and create an array to store the loss function values.
n = length(ytrain); lambdavals = linspace(0,20,20)/n; lossvals = zeros(length(lambdavals),numvalidsets);
2. Train the NCA model for each Lambda value, using the training set in each fold.
3. Compute the classification loss for the corresponding test set in the fold using the NCA model. Record the loss value.
4. Repeat this process for all folds and all Lambda values.
for i = 1:length(lambdavals) for k = 1:numvalidsets X = Xtrain(cvp.training(k),:); y = ytrain(cvp.training(k),:); Xvalid = Xtrain(cvp.test(k),:); yvalid = ytrain(cvp.test(k),:); nca = fscnca(X,y,FitMethod="exact", ... Solver="sgd",Lambda=lambdavals(i), ... IterationLimit=30,GradientTolerance=1e-4, ... Standardize=true); lossvals(i,k) = loss(nca,Xvalid,yvalid,LossFunction="classiferror"); end end
Compute the average loss obtained from the folds for each Lambda value.
meanloss = mean(lossvals,2);
Plot the average loss values versus the Lambda values.
figure() plot(lambdavals,meanloss,"ro-") xlabel("Lambda") ylabel("Loss (MSE)") grid on
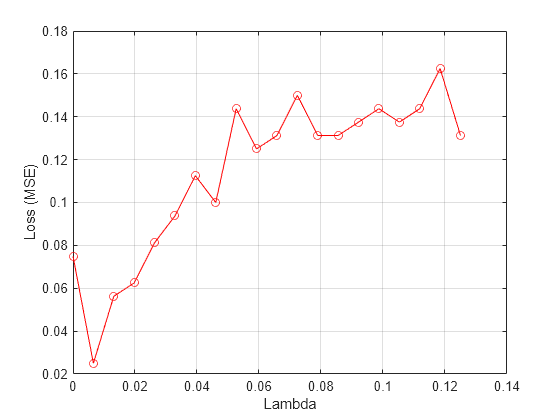
Find the best Lambda value that corresponds to the minimum average loss.
[~,idx] = min(meanloss) % Find the indexidx = 2
bestlambda = lambdavals(idx) % Find the best Lambda valuebestlambda = 0.0066
bestloss = meanloss(idx)
bestloss = 0.0312
Fit the NCA model on all the data using the best Lambda value. Use the solver sgd and standardize the predictor values.
nca = fscnca(Xtrain,ytrain,FitMethod="exact",Solver="sgd",... Lambda=bestlambda,Standardize=true,Verbose=1);
o Tuning initial learning rate: NumTuningIterations = 20, TuningSubsetSize = 100
|===============================================|
| TUNING | TUNING SUBSET | LEARNING |
| ITER | FUN VALUE | RATE |
|===============================================|
| 1 | 2.403497e+01 | 2.000000e-01 |
| 2 | 2.275050e+01 | 4.000000e-01 |
| 3 | 2.036845e+01 | 8.000000e-01 |
| 4 | 1.627647e+01 | 1.600000e+00 |
| 5 | 1.023512e+01 | 3.200000e+00 |
| 6 | 3.864283e+00 | 6.400000e+00 |
| 7 | 4.743816e-01 | 1.280000e+01 |
| 8 | -7.260138e-01 | 2.560000e+01 |
| 9 | -7.260138e-01 | 2.560000e+01 |
| 10 | -7.260138e-01 | 2.560000e+01 |
| 11 | -7.260138e-01 | 2.560000e+01 |
| 12 | -7.260138e-01 | 2.560000e+01 |
| 13 | -7.260138e-01 | 2.560000e+01 |
| 14 | -7.260138e-01 | 2.560000e+01 |
| 15 | -7.260138e-01 | 2.560000e+01 |
| 16 | -7.260138e-01 | 2.560000e+01 |
| 17 | -7.260138e-01 | 2.560000e+01 |
| 18 | -7.260138e-01 | 2.560000e+01 |
| 19 | -7.260138e-01 | 2.560000e+01 |
| 20 | -7.260138e-01 | 2.560000e+01 |
o Solver = SGD, MiniBatchSize = 10, PassLimit = 5
|==========================================================================================|
| PASS | ITER | AVG MINIBATCH | AVG MINIBATCH | NORM STEP | LEARNING |
| | | FUN VALUE | NORM GRAD | | RATE |
|==========================================================================================|
| 0 | 9 | 4.016078e+00 | 2.835465e-02 | 5.395984e+00 | 2.560000e+01 |
| 1 | 19 | -6.726156e-01 | 6.111354e-02 | 5.021138e-01 | 1.280000e+01 |
| 1 | 29 | -8.316555e-01 | 4.024186e-02 | 1.196031e+00 | 1.280000e+01 |
| 2 | 39 | -8.838656e-01 | 2.333416e-02 | 1.225834e-01 | 8.533333e+00 |
| 3 | 49 | -8.669034e-01 | 3.413162e-02 | 3.421902e-01 | 6.400000e+00 |
| 3 | 59 | -8.906936e-01 | 1.946295e-02 | 2.232511e-01 | 6.400000e+00 |
| 4 | 69 | -8.778630e-01 | 3.561290e-02 | 3.290645e-01 | 5.120000e+00 |
| 4 | 79 | -8.857135e-01 | 2.516638e-02 | 3.902979e-01 | 5.120000e+00 |
Two norm of the final step = 3.903e-01
Relative two norm of the final step = 6.171e-03, TolX = 1.000e-06
EXIT: Iteration or pass limit reached.
Plot the feature weights.
figure() plot(nca.FeatureWeights,"ro") xlabel("Feature Index") ylabel("Feature Weight") grid on
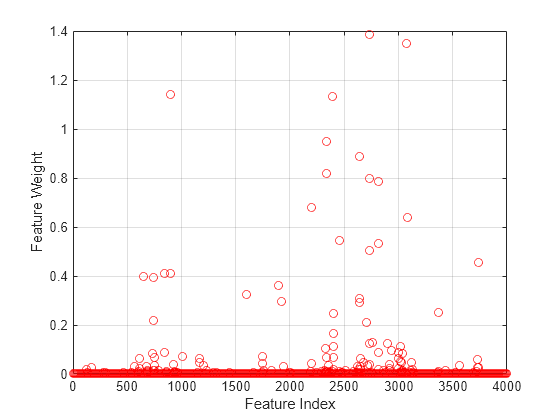
Most of the feature weights are very close to zero, which means that they are irrelevant. Some features have much higher feature weight values. In this case, to select a reasonable number of predictors, specify a threshold of 0.02 times the maximum feature weight value.
selidx = find(nca.FeatureWeights > 0.02*max(1,max(nca.FeatureWeights)))
selidx = 72×1
565
611
654
681
737
743
744
750
754
839
840
897
899
925
1010
⋮
Compute the classification loss using the test set.
loss(nca,Xtest,ytest)
ans = 0.0179
Extract the features with feature weights greater than the specified threshold value from the training data.
features = Xtrain(:,selidx);
Apply a support vector machine classifier to the reduced training set using the selected features.
svmMdl = fitcsvm(features,ytrain);
Evaluate the accuracy of the trained classifier on the test data, which has not been used for feature selection.
loss(svmMdl,Xtest(:,selidx),ytest)
ans = single
0
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2016b