regress
Multiple linear regression
Syntax
Description
Examples
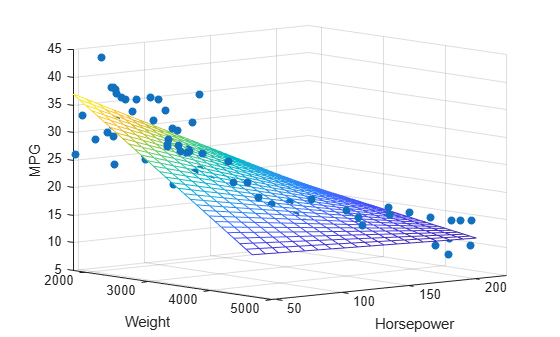
Load the carsmall data set. Identify weight and horsepower as predictors and mileage as the response.
load carsmall x1 = Weight; x2 = Horsepower; % Contains NaN data y = MPG;
Compute the regression coefficients for a linear model with an interaction term.
X = [ones(size(x1)) x1 x2 x1.*x2];
b = regress(y,X) % Removes NaN datab = 4×1
60.7104
-0.0102
-0.1882
0.0000
Plot the data and the model.
scatter3(x1,x2,y,'filled') hold on x1fit = min(x1):100:max(x1); x2fit = min(x2):10:max(x2); [X1FIT,X2FIT] = meshgrid(x1fit,x2fit); YFIT = b(1) + b(2)*X1FIT + b(3)*X2FIT + b(4)*X1FIT.*X2FIT; mesh(X1FIT,X2FIT,YFIT) xlabel('Weight') ylabel('Horsepower') zlabel('MPG') view(50,10) hold off
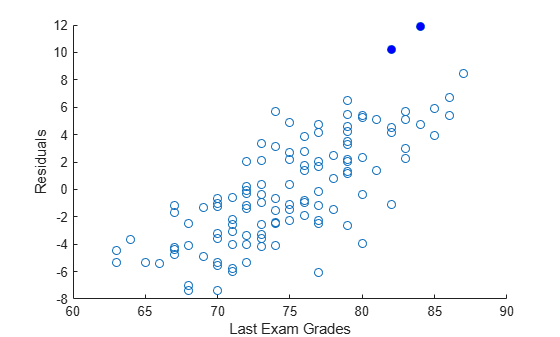
Load the examgrades data set.
load examgradesUse the last exam scores as response data and the first two exam scores as predictor data.
y = grades(:,5); X = [ones(size(grades(:,1))) grades(:,1:2)];
Perform multiple linear regression with alpha = 0.01.
[~,~,r,rint] = regress(y,X,0.01);
Diagnose outliers by finding the residual intervals rint that do not contain 0.
contain0 = (rint(:,1)<0 & rint(:,2)>0); idx = find(contain0==false)
idx = 2×1
53
54
Observations 53 and 54 are possible outliers.
Create a scatter plot of the residuals. Fill in the points corresponding to the outliers.
hold on scatter(y,r) scatter(y(idx),r(idx),'b','filled') xlabel("Last Exam Grades") ylabel("Residuals") hold off
Load the hald data set. Use heat as the response variable and ingredients as the predictor data.
load hald y = heat; X1 = ingredients; x1 = ones(size(X1,1),1); X = [x1 X1]; % Includes column of ones
Perform multiple linear regression and generate model statistics.
[~,~,~,~,stats] = regress(y,X)
stats = 1×4
0.9824 111.4792 0.0000 5.9830
Because the value of 0.9824 is close to 1, and the p-value of 0.0000 is less than the default significance level of 0.05, a significant linear regression relationship exists between the response y and the predictor variables in X.
Input Arguments
Output Arguments
Tips
Algorithms
Alternative Functionality
regress is useful when you simply need the output arguments of
the function and when you want to repeat fitting a model multiple times in a loop. If
you need to investigate a fitted regression model further, create a linear regression
model object LinearModel by using fitlm or stepwiselm. A LinearModel
object provides more features than regress.
Use the properties of
LinearModelto investigate a fitted linear regression model. The object properties include information about coefficient estimates, summary statistics, fitting method, and input data.Use the object functions of
LinearModelto predict responses and to modify, evaluate, and visualize the linear regression model.Unlike
regress, thefitlmfunction does not require a column of ones in the input data. A model created byfitlmalways includes an intercept term unless you specify not to include it by using the'Intercept'name-value pair argument.You can find the information in the output of
regressusing the properties and object functions ofLinearModel.Output of regressEquivalent Values in LinearModelbSee the Estimatecolumn of theCoefficientsproperty.bintUse the coefCIfunction.rSee the Rawcolumn of theResidualsproperty.rintNot supported. Instead, use studentized residuals ( Residualsproperty) and observation diagnostics (Diagnosticsproperty) to find outliers.statsSee the model display in the Command Window. You can find the statistics in the model properties ( MSEandRsquared) and by using theanovafunction.
References
[1] Chatterjee, S., and A. S. Hadi. “Influential Observations, High Leverage Points, and Outliers in Linear Regression.” Statistical Science. Vol. 1, 1986, pp. 379–416.
Extended Capabilities
Version History
Introduced before R2006a
See Also
LinearModel | fitlm | stepwiselm | mvregress | rcoplot