mvregress
Multivariate linear regression
Syntax
Description
beta = mvregress(X,Y)Y on
the design matrices in X.
beta = mvregress(X,Y,Name,Value)
Examples
Fit a multivariate regression model to panel data, assuming different intercepts and common slopes.
Load the sample data.
load fluThe dataset array flu contains national CDC flu estimates, and nine separate regional estimates based on Google® query data.
Extract the response and predictor data.
Y = double(flu(:,2:end-1)); [n,d] = size(Y); x = flu.WtdILI;
The responses in Y are the nine regional flu estimates. Observations exist for every week over a one-year period, so = 52. The dimension of the responses corresponds to the regions, so = 9. The predictors in x are the weekly national flu estimates.
Plot the flu data, grouped by region.
figure; regions = flu.Properties.VarNames(2:end-1); plot(x,Y,"x") legend(regions,Location="NorthWest")
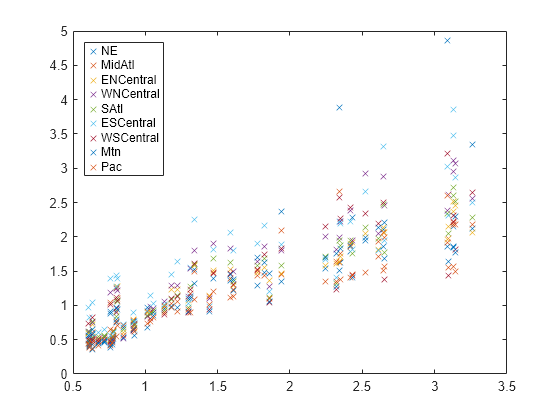
Fit the multivariate regression model , where and , with between-region concurrent correlation .
There are = 10 regression coefficients to estimate: nine intercept terms and a common slope. The input argument X should be an -element cell array of -by- design matrices.
X = cell(n,1); for i = 1:n X{i} = [eye(d) repmat(x(i),d,1)]; end [beta,Sigma] = mvregress(X,Y);
beta contains estimates of the -dimensional coefficient vector .
Sigma contains estimates of the -by- variance-covariance matrix , for the between-region concurrent correlations.
Plot the fitted regression model.
B = [beta(1:d)';repmat(beta(end),1,d)]; xx = linspace(.5,3.5)'; fits = [ones(size(xx)),xx]*B; figure; h = plot(x,Y,"x",xx,fits,"-"); for i = 1:d set(h(d+i),color=get(h(i),"color")); end legend(regions,Location="NorthWest");
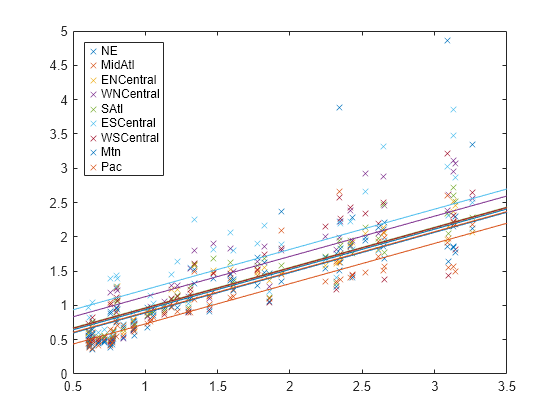
The plot shows that each regression line has a different intercept but the same slope. Upon visual inspection, some regression lines appear to fit the data better than others.
Fit a multivariate regression model to panel data using least squares, assuming different intercepts and slopes.
Load the sample data.
load flu;The dataset array flu contains national CDC flu estimates, and nine separate regional estimates based on Google® queries.
Save the response and predictor data as well as the size of the response variable.
Y = double(flu(:,2:end-1)); [n,d] = size(Y); x = flu.WtdILI;
The responses in Y are the nine regional flu estimates. Observations exist for every week over a one-year period, so = 52. The dimension of the responses corresponds to the regions, so = 9. The predictors in x are the weekly national flu estimates.
Fit the multivariate regression model , where and , with between-region concurrent correlation .
There are = 18 regression coefficients to estimate: nine intercept terms, and nine slope terms. X is an -element cell array of -by- design matrices.
X = cell(n,1); for i = 1:n X{i} = [eye(d) x(i)*eye(d)]; end [beta,Sigma] = mvregress(X,Y,'algorithm','cwls');
beta contains estimates of the -dimensional coefficient vector .
Plot the fitted regression model.
B = [beta(1:d)';beta(d+1:end)']; xx = linspace(.5,3.5)'; fits = [ones(size(xx)),xx]*B; figure; h = plot(x,Y,'x',xx,fits,'-'); for i = 1:d set(h(d+i),'color',get(h(i),'color')); end regions = flu.Properties.VarNames(2:end-1); legend(regions,'Location','NorthWest');
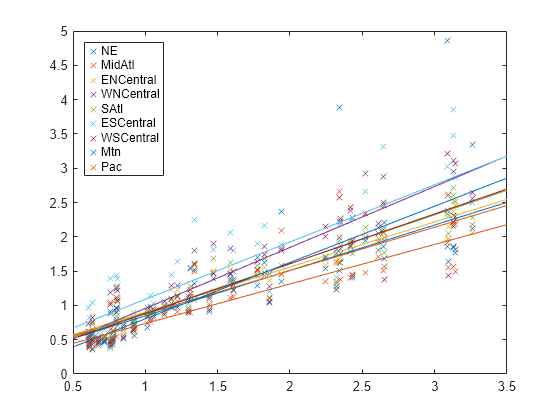
The plot shows that each regression line has a different intercept and slope.
Fit a multivariate regression model using a single -by- design matrix for all response dimensions.
Load the sample data.
load('flu')The dataset array flu contains national CDC flu estimates, and nine separate regional estimates based on Google® queries.
Extract the response and predictor data.
Y = double(flu(:,2:end-1)); [n,d] = size(Y); x = flu.WtdILI;
The responses in Y are the nine regional flu estimates. Observations exist for every week over a one-year period, so = 52. The dimension of the responses corresponds to the regions, so = 9. The predictors in x are the weekly national flu estimates.
Create an -by- design matrix X. Add a column of ones to include a constant term in the regression.
X = [ones(size(x)),x];
Fit the multivariate regression model
where and , with between-region concurrent correlation
There are 18 regression coefficients to estimate: nine intercept terms, and nine slope terms.
[beta,Sigma,E,CovB,logL] = mvregress(X,Y);
beta contains estimates of the -by- coefficient matrix. Sigma contains estimates of the -by- variance-covariance matrix for the between-region concurrent correlations. E is a matrix of the residuals. CovB is the estimated variance-covariance matrix of the regression coefficients. logL is the value of the log likelihood objective function after the last iteration.
Plot the fitted regression model.
B = beta; xx = linspace(.5,3.5)'; fits = [ones(size(xx)),xx]*B; figure h = plot(x,Y,'x', xx,fits,'-'); for i = 1:d set(h(d+i),'color',get(h(i),'color')) end regions = flu.Properties.VarNames(2:end-1); legend(regions,'Location','NorthWest')
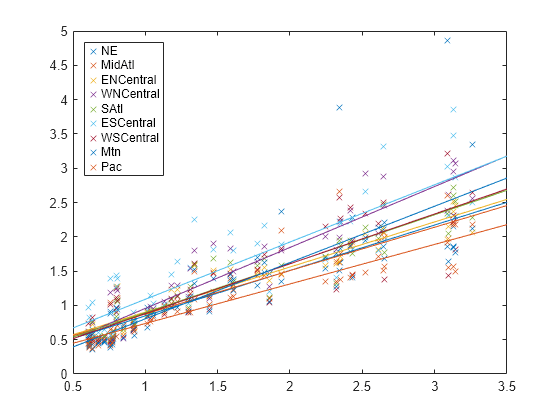
The plot shows that each regression line has a different intercept and slope.
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
[1] Little, Roderick J. A., and Donald B. Rubin. Statistical Analysis with Missing Data. 2nd ed., Hoboken, NJ: John Wiley & Sons, Inc., 2002.
[2] Meng, Xiao-Li, and Donald B. Rubin. “Maximum Likelihood Estimation via the ECM Algorithm.” Biometrika. Vol. 80, No. 2, 1993, pp. 267–278.
[3] Sexton, Joe, and A. R. Swensen. “ECM Algorithms that Converge at the Rate of EM.” Biometrika. Vol. 87, No. 3, 2000, pp. 651–662.
[4] Dempster, A. P., N. M. Laird, and D. B. Rubin. “Maximum Likelihood from Incomplete Data via the EM Algorithm.” Journal of the Royal Statistical Society. Series B, Vol. 39, No. 1, 1977, pp. 1–37.
Version History
Introduced in R2006b