Cox
Description
Create and analyze a Cox model object to calculate
lifetime probability of default (PD) using this workflow:
Use
fitLifetimePDModelto create aCoxmodel object.Optionally, use
discardResidualsto remove residual information from theCoxmodel object.Use
predictto predict the conditional PD andpredictLifetimeto predict the lifetime PD.Use
modelDiscriminationto return AUROC and ROC data. You can plot the results usingmodelDiscriminationPlot.Use
modelCalibrationto return the root mean square error (RMSE) of observed and predicted PD data. You can plot the results usingmodelCalibrationPlot.
Creation
Syntax
Description
CoxPDModel = fitLifetimePDModel(data,ModelType,AgeVar=agevar_value)Cox PD model object.
If you do not specify variable information for
IDVar, LoanVars,
MacroVars, and
ResponseVar, then:
IDVaris set to the first column in thedatainput.LoanVarsis set to include all columns from the second to the second-to-last columns of thedatainput.ResponseVaris set to the last column in thedatainput.
CoxPDModel = fitLifetimePDModel(___,Name=Value)CoxPDModel =
fitLifetimePDModel(data(TrainDataInd,:),"Cox",ModelID="Cox_A",Description="Cox_model",AgeVar="YOB",IDVar="ID",LoanVars="ScoreGroup",MacroVars={'GDP','Market'},ResponseVar="Default",TimeInterval=1,TieBreakMethod="Efron",WeightsVar="Weights")
creates a CoxPDModel using a Cox model
type. You can specify multiple name-value arguments.
Input Arguments
Name-Value Arguments
Properties
Object Functions
predict | Compute conditional PD |
predictLifetime | Compute cumulative lifetime PD, marginal PD, and survival probability |
modelDiscrimination | Compute AUROC and ROC data |
modelCalibration | Compute RMSE of predicted and observed PDs on grouped data |
modelDiscriminationPlot | Plot ROC curve |
modelCalibrationPlot | Plot observed default rates compared to predicted PDs on grouped data |
discardResiduals | Discard residual information of underlying Cox model |
Examples
This example shows how to use fitLifetimePDModel to create a Cox model using credit and macroeconomic data.
Load Data
Load the credit portfolio data.
load RetailCreditPanelData.mat
disp(head(data)) ID ScoreGroup YOB Default Year
__ __________ ___ _______ ____
1 Low Risk 1 0 1997
1 Low Risk 2 0 1998
1 Low Risk 3 0 1999
1 Low Risk 4 0 2000
1 Low Risk 5 0 2001
1 Low Risk 6 0 2002
1 Low Risk 7 0 2003
1 Low Risk 8 0 2004
disp(head(dataMacro))
Year GDP Market
____ _____ ______
1997 2.72 7.61
1998 3.57 26.24
1999 2.86 18.1
2000 2.43 3.19
2001 1.26 -10.51
2002 -0.59 -22.95
2003 0.63 2.78
2004 1.85 9.48
Join the two data components into a single data set.
data = join(data,dataMacro); disp(head(data))
ID ScoreGroup YOB Default Year GDP Market
__ __________ ___ _______ ____ _____ ______
1 Low Risk 1 0 1997 2.72 7.61
1 Low Risk 2 0 1998 3.57 26.24
1 Low Risk 3 0 1999 2.86 18.1
1 Low Risk 4 0 2000 2.43 3.19
1 Low Risk 5 0 2001 1.26 -10.51
1 Low Risk 6 0 2002 -0.59 -22.95
1 Low Risk 7 0 2003 0.63 2.78
1 Low Risk 8 0 2004 1.85 9.48
Partition Data
Separate the data into training and test partitions.
nIDs = max(data.ID); uniqueIDs = unique(data.ID); rng('default'); % For reproducibility c = cvpartition(nIDs,'HoldOut',0.4); TrainIDInd = training(c); TestIDInd = test(c); TrainDataInd = ismember(data.ID,uniqueIDs(TrainIDInd)); TestDataInd = ismember(data.ID,uniqueIDs(TestIDInd));
Create a Cox Lifetime PD Model
Use fitLifetimePDModel to create a Cox model using the training data.
pdModel = fitLifetimePDModel(data(TrainDataInd,:),"Cox",... AgeVar="YOB", ... IDVar="ID", ... LoanVars="ScoreGroup", ... MacroVars={'GDP','Market'}, ... ResponseVar="Default"); disp(pdModel)
Cox with properties:
ExtrapolationFactor: 1
ModelID: "Cox"
Description: ""
UnderlyingModel: [1×1 CoxModel]
IDVar: "ID"
AgeVar: "YOB"
LoanVars: "ScoreGroup"
MacroVars: ["GDP" "Market"]
ResponseVar: "Default"
WeightsVar: ""
TimeInterval: 1
Display the underlying model.
disp(pdModel.UnderlyingModel)
Cox Proportional Hazards regression model
Beta SE zStat pValue
__________ _________ _______ ___________
ScoreGroup_Medium Risk -0.6794 0.037029 -18.348 3.4442e-75
ScoreGroup_Low Risk -1.2442 0.045244 -27.501 1.7116e-166
GDP -0.084533 0.043687 -1.935 0.052995
Market -0.0084411 0.0032221 -2.6198 0.0087991
Log-likelihood: -41742.871
Validate Model
Use modelDiscrimination to measure the ranking of customers by PD.
DataSetChoice ="Testing"; if DataSetChoice=="Training" Ind = TrainDataInd; else Ind = TestDataInd; end DiscMeasure = modelDiscrimination(pdModel,data(Ind,:),SegmentBy="ScoreGroup")
DiscMeasure=3×1 table
AUROC
_______
Cox, ScoreGroup=High Risk 0.64112
Cox, ScoreGroup=Medium Risk 0.61989
Cox, ScoreGroup=Low Risk 0.6314
disp(DiscMeasure)
AUROC
_______
Cox, ScoreGroup=High Risk 0.64112
Cox, ScoreGroup=Medium Risk 0.61989
Cox, ScoreGroup=Low Risk 0.6314
Use modelDiscriminationPlot to visualize the ROC curve.
modelDiscriminationPlot(pdModel,data(Ind,:),SegmentBy="ScoreGroup")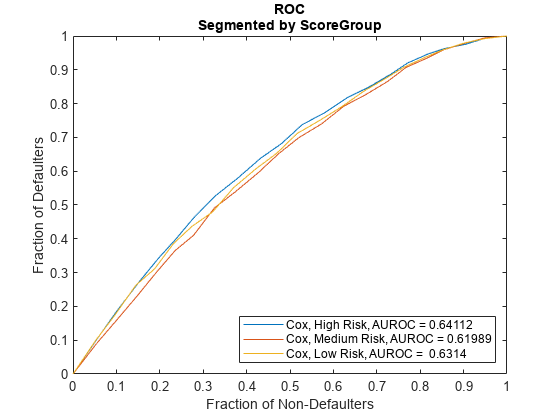
Use modelCalibration to measure the calibration of the predicted PD values. The modelCalibration function requires a grouping variable and compares the accuracy of the observed default rate in the group with the average predicted PD for the group.
CalMeasure = modelCalibration(pdModel,data(Ind,:),{'YOB','ScoreGroup'})CalMeasure=table
RMSE
_________
Cox, grouped by YOB, ScoreGroup 0.0012471
disp(CalMeasure)
RMSE
_________
Cox, grouped by YOB, ScoreGroup 0.0012471
Use modelCalibrationPlot to visualize the observed default rates compared to the predicted PD.
modelCalibrationPlot(pdModel,data(Ind,:),{'YOB','ScoreGroup'})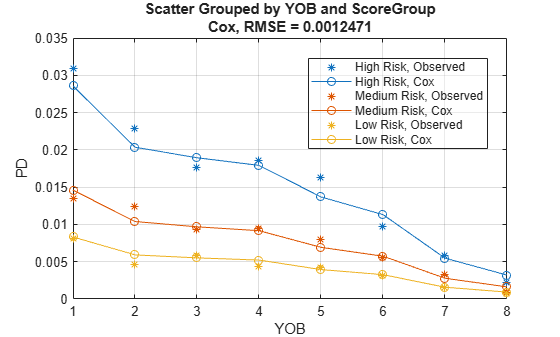
Predict Conditional and Lifetime PD
Use the predict function to predict conditional PD values. The prediction is a row-by-row prediction.
%dataCustomer1 = data(1:8,:);
CondPD = predict(pdModel,data(Ind,:));Use predictLifetime to predict the lifetime cumulative PD values (computing marginal and survival PD values is also supported).
LifetimePD = predictLifetime(pdModel,data(Ind,:));
Since R2023a
This example shows how to create a Cox model and select the tie-break method while fitting a Cox lifetime PD model.
Load Data
Load the credit portfolio data.
load RetailCreditPanelData.mat
disp(head(data)) ID ScoreGroup YOB Default Year
__ __________ ___ _______ ____
1 Low Risk 1 0 1997
1 Low Risk 2 0 1998
1 Low Risk 3 0 1999
1 Low Risk 4 0 2000
1 Low Risk 5 0 2001
1 Low Risk 6 0 2002
1 Low Risk 7 0 2003
1 Low Risk 8 0 2004
disp(head(dataMacro))
Year GDP Market
____ _____ ______
1997 2.72 7.61
1998 3.57 26.24
1999 2.86 18.1
2000 2.43 3.19
2001 1.26 -10.51
2002 -0.59 -22.95
2003 0.63 2.78
2004 1.85 9.48
Join the two data components into a single data set.
data = join(data,dataMacro); disp(head(data))
ID ScoreGroup YOB Default Year GDP Market
__ __________ ___ _______ ____ _____ ______
1 Low Risk 1 0 1997 2.72 7.61
1 Low Risk 2 0 1998 3.57 26.24
1 Low Risk 3 0 1999 2.86 18.1
1 Low Risk 4 0 2000 2.43 3.19
1 Low Risk 5 0 2001 1.26 -10.51
1 Low Risk 6 0 2002 -0.59 -22.95
1 Low Risk 7 0 2003 0.63 2.78
1 Low Risk 8 0 2004 1.85 9.48
Join the Data
Join the two data components into a single data set.
data = join(data,dataMacro); disp(head(data))
ID ScoreGroup YOB Default Year GDP Market
__ __________ ___ _______ ____ _____ ______
1 Low Risk 1 0 1997 2.72 7.61
1 Low Risk 2 0 1998 3.57 26.24
1 Low Risk 3 0 1999 2.86 18.1
1 Low Risk 4 0 2000 2.43 3.19
1 Low Risk 5 0 2001 1.26 -10.51
1 Low Risk 6 0 2002 -0.59 -22.95
1 Low Risk 7 0 2003 0.63 2.78
1 Low Risk 8 0 2004 1.85 9.48
Partition the Data
Separate the data into training and test partitions.
nIDs = max(data.ID); uniqueIDs = unique(data.ID); rng('default'); % for reproducibility c = cvpartition(nIDs,'HoldOut',0.4); TrainIDInd = training(c); TestIDInd = test(c); TrainDataInd = ismember(data.ID,uniqueIDs(TrainIDInd)); TestDataInd = ismember(data.ID,uniqueIDs(TestIDInd));
Create a Cox Lifetime PD Model with Breslow's Method
Use fitLifetimePDModel to create a Cox model using the training data. Use the name-value argument TieBreakMethod to set tie-break method to 'breslow'. This is the default choice for this argument.
pdModel1 = fitLifetimePDModel(data(TrainDataInd,:),"Cox",... ModelID="Cox-Breslow", IDVar="ID", AgeVar="YOB", ... LoanVars="ScoreGroup", MacroVars={'GDP','Market'}, ... ResponseVar="Default",TieBreakMethod='breslow');
Display the underlying model.
disp(pdModel1.Model)
Cox Proportional Hazards regression model
Beta SE zStat pValue
__________ _________ _______ ___________
ScoreGroup_Medium Risk -0.6794 0.037029 -18.348 3.4442e-75
ScoreGroup_Low Risk -1.2442 0.045244 -27.501 1.7116e-166
GDP -0.084533 0.043687 -1.935 0.052995
Market -0.0084411 0.0032221 -2.6198 0.0087991
Log-likelihood: -41742.871
Use predict to predict the conditional PD.
pd1 = predict(pdModel1,data(TestDataInd,:));
Create a Cox Lifetime PD Model with Efron's Method
Use fitLifetimePDModel to create a Cox model using the training data. Use the name-value argument TieBreakMethod to set tie-break method to 'Efron'. This is the default choice for this argument.
pdModel2 = fitLifetimePDModel(data(TrainDataInd,:),"Cox",... ModelID="Cox-Efron", IDVar="ID", AgeVar="YOB", ... LoanVars="ScoreGroup", MacroVars={'GDP','Market'}, ... ResponseVar="Default",TieBreakMethod='efron');
Display the underlying model. The coefficients are only slightly different for this data set.
disp(pdModel2.Model)
Cox Proportional Hazards regression model
Beta SE zStat pValue
__________ _________ _______ __________
ScoreGroup_Medium Risk -0.6844 0.037029 -18.483 2.8461e-76
ScoreGroup_Low Risk -1.2515 0.045243 -27.662 2.006e-168
GDP -0.084985 0.043691 -1.9452 0.051756
Market -0.0085126 0.0032223 -2.6418 0.0082469
Log-likelihood: -41713.445
Use predict to predict the conditional PD for the second Cox model.
pd2 = predict(pdModel2,data(TestDataInd,:));
Compare Cox Models
The predictions for the two Cox models are almost the same for this data set.
[pd1(1:10) pd2(1:10)]
ans = 10×2
0.0162 0.0161
0.0091 0.0090
0.0081 0.0081
0.0073 0.0072
0.0064 0.0064
0.0072 0.0072
0.0030 0.0030
0.0016 0.0016
0.0162 0.0161
0.0091 0.0090
For this data set, the model discrimination (modelDiscrimination) does not seem to change with the TieBreakMethod method and the model accuracy (modelCalibration) shows only a negligible difference in RMSE.
modelDiscriminationPlot(pdModel1,data(TestDataInd,:),ReferencePD=pd2,ReferenceID=pdModel2.ModelID)

modelCalibrationPlot(pdModel1,data(TestDataInd,:),'Year',ReferencePD=pd2,ReferenceID=pdModel2.ModelID)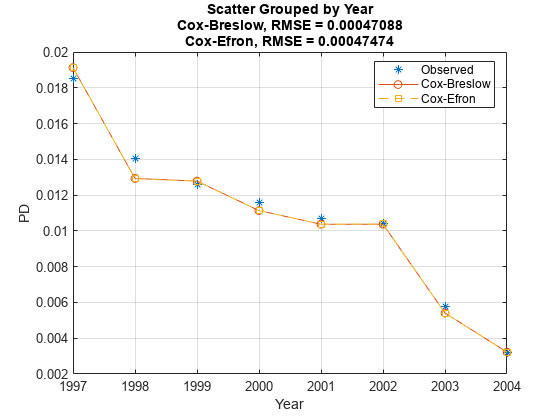
More About
References
[1] Baesens, Bart, Daniel Roesch, and Harald Scheule. Credit Risk Analytics: Measurement Techniques, Applications, and Examples in SAS. Wiley, 2016.
[2] Bellini, Tiziano. IFRS 9 and CECL Credit Risk Modelling and Validation: A Practical Guide with Examples Worked in R and SAS. San Diego, CA: Elsevier, 2019.
[3] Breeden, Joseph. Living with CECL: The Modeling Dictionary. Santa Fe, NM: Prescient Models LLC, 2018.
[4] Roesch, Daniel and Harald Scheule. Deep Credit Risk: Machine Learning with Python. Independently published, 2020.
Version History
Introduced in R2021bSee Also
Functions
Topics
- Basic Lifetime PD Model Validation
- Compare Logistic Model for Lifetime PD to Champion Model
- Compare Lifetime PD Models Using Cross-Validation
- Expected Credit Loss Computation
- Compare Model Discrimination and Model Calibration to Validate of Probability of Default
- Compare Probability of Default Using Through-the-Cycle and Point-in-Time Models
- Modeling Probabilities of Default with Cox Proportional Hazards
- Create Weighted Lifetime PD Model
- Overview of Lifetime Probability of Default Models