Why Use Discrete-Event Simulation? | Understanding Discrete-Event Simulation, Part 2
From the series: Understanding Discrete-Event Simulation
Learn how discrete-event simulation can help you solve problems related to scheduling, resource allocation, and capacity planning in this MATLAB® Tech Talk by Will Campbell. Some processes lend themselves well to discrete-event simulation due to their event-driven nature. In situations where the choice is less clear, you may adopt a discrete-event approach due to the computational advantages it offers over a continuous dynamics simulation. Ultimately, though, adoption depends on the problem you’re attempting to solve. In this video, you’ll learn what level of detail needs to be modeled in a discrete-event simulation, and what level of detail is important for your model.
Published: 6 Jul 2017
Discrete-event simulation analyzes the behavior of a dynamic system by approximating it as a sequence of instantaneous occurrences. Let’s examine why they are so powerful for certain applications, and why you might use them over other simulation techniques. Some processes lend themselves well to discrete-event simulation due to their event-driven nature. In situations where the choice is less clear, you may adopt a discrete-event approach due to the computational advantages it offers over a continuous dynamics simulation. Ultimately though, adoption will depend on what problem you’re attempting to solve. Discrete-event simulations are often used to answer questions concerning scheduling, resource allocation, and capacity planning.
Statistician George E. P. Box wrote that "all models are wrong, but some are useful." Understanding the purpose of your simulation dictates how you approximate the system. In many cases, discrete-event simulation is a straightforward way to model the problem and acquire the desired data. For example, if your task is to understand how the number of cashiers impacts line lengths at a grocery store, you probably wouldn’t worry about simulating every bar code swipe. If you want to predict bit drop rates in a data network, you likely don’t care about the voltage across every single transistor. It’s these kinds of applications, when questions such as resource management are at play, that low-level details become irrelevant and discrete-event simulations become useful. Let’s take a closer look.
Consider the task of simulating the flight of an aircraft. One approach would be a trajectory-based simulation in which the model diligently tracks the position of the aircraft. You could run this simulation to any point in time and precisely know the history of the vehicle’s latitude, longitude, and altitude through all stages of flight.
But perhaps we aren’t concerned with just one aircraft. Perhaps we want to simulate an entire fleet of aircraft flying between dozens of airports in a number of countries. And the reason we’re simulating is because we want to understand how weather and air traffic delays in one region impact fleet performance globally. If this were the goal, the only information that’s relevant is what the aircraft are doing and what region they’re in. Calculating latitude, longitude, and altitude of every single aircraft at every point in time is computationally wasteful. We simply don’t need all that data to get the answer we’re seeking.
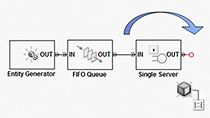
So instead, let’s only track which phases of flight the aircraft are in. Modeling in this manner enables us to use a discrete-event simulation, with the events being the transitions between phases of flight. Time spent in each phase is represented by servers, and queues represent ground delays and holding patterns. By simplifying things, the effort for a design engineer to develop the model can be greatly diminished. Plus, the computational overhead of the simulation is drastically reduced since the only calculations performed are the updates to the flight phase for each aircraft. This means we can run more simulations, providing us a more thorough picture of the system under different scenarios. And what are the kind of things these simulations can teach us? Well, we can use the simulation results to identify bottlenecks in our process, characterize deadlock conditions, and gain a clear picture of latency throughout the system. This information enables us to make informed decisions about optimizing the performance of an aircraft fleet, or any other system we choose to investigate.