refit
Refit neighborhood component analysis (NCA) model for classification
Description
mdlrefit = refit(mdl,Name=Value)mdl, with modified parameters specified by one
or more name-value arguments.
Examples
Generate checkerboard data using the generateCheckerBoardData.m function.
rng(2016,"twister"); % For reproducibility pps = 1375; [X,y] = generateCheckerBoardData(pps); X = X + 2;
Plot the data.
plot(X(y==1,1),X(y==1,2),"x") hold on plot(X(y==-1,1),X(y==-1,2),"x") hold off
[n,p] = size(X)
n = 22000
p = 2
Add irrelevant predictors to the data.
Q = 98; Xrnd = unifrnd(0,4,n,Q); Xobs = [X,Xrnd];
This piece of code creates 98 additional predictors, all uniformly distributed between 0 and 4.
Partition the data into training and test sets. To create stratified partitions, so that each partition has similar proportion of classes, use y instead of length(y) as the partitioning criteria.
cvp = cvpartition(y,"Holdout",2000);cvpartition randomly chooses 2000 of the observations to add to the test set and the rest of the data to add to the training set. Create the training and validation sets using the assignments stored in the cvpartition object cvp.
Xtrain = Xobs(cvp.training(1),:); ytrain = y(cvp.training(1),:); Xval = Xobs(cvp.test(1),:); yval = y(cvp.test(1),:);
Compute the misclassification error without feature selection.
nca = fscnca(Xtrain,ytrain,FitMethod="none",Standardize=true, ... Solver="lbfgs"); loss_nofs = loss(nca,Xval,yval)
loss_nofs = 0.5165
The FitMethod="none" option uses the default weights (all 1s), which means all features are equally important.
This time, perform feature selection using neighborhood component analysis for classification, with .
w0 = rand(100,1); n = length(ytrain)
n = 20000
lambda = 1/n; nca = refit(nca,InitialFeatureWeights=w0,FitMethod="exact", ... Lambda=lambda,Solver="sgd");
Plot the objective function value versus the iteration number.
plot(nca.FitInfo.Iteration,nca.FitInfo.Objective,"o") hold on plot(nca.FitInfo.Iteration,movmean(nca.FitInfo.Objective,10),".-") hold off xlabel("Iteration number") ylabel("Objective value")
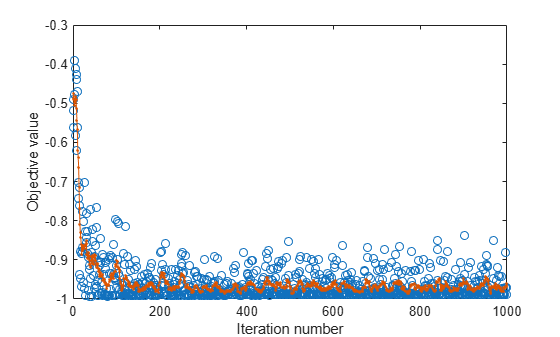
Compute the misclassification error with feature selection.
loss_withfs = loss(nca,Xval,yval)
loss_withfs = 0.0115
Plot the selected features.
semilogx(nca.FeatureWeights,"o") xlabel("Feature index") ylabel("Feature weight") grid on
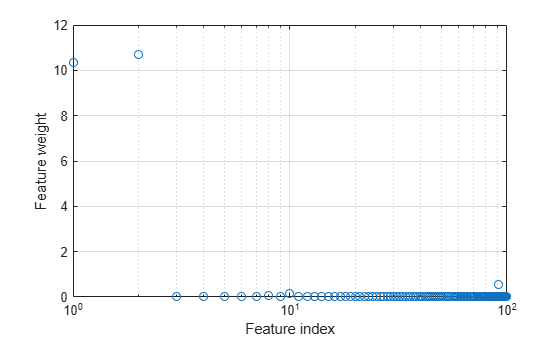
Select features using the feature weights and a relative threshold.
tol = 0.15; selidx = find(nca.FeatureWeights > tol*max(1,max(nca.FeatureWeights)))
selidx = 2×1
1
2
Feature selection improves the results and fscnca detects the correct two features as relevant.
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2016b
See Also
FeatureSelectionNCAClassification | loss | fscnca | predict | selectFeatures