similarityDistance
Syntax
Description
Examples
Load the data, which consists of T1 and T2. T1 is a timetable containing armature current measurements on a degrading DC motor. T2 is a timetable that contains data collected from a known faulty motor.
load matrix_profile_data T1 T2
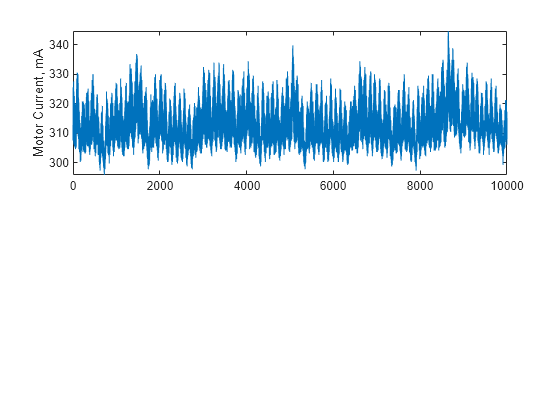
Set x to the MotorCurrent variable in T1. Plot x in a subplot.
x = T1.MotorCurrent; subplot(211) plot(x) ylabel("Motor Current, mA") hold on
T2 contains anomalous data in a segment that begins at location 3000 and has a length of 100. Extract this data as the target segment y.
len = 100; loc = 3000; iy = loc:loc+len-1; y = T2.MotorCurrent(iy);
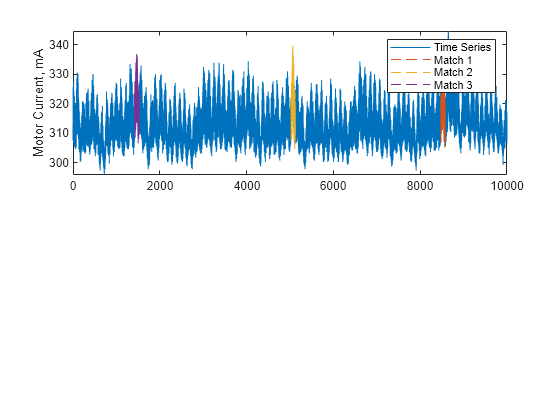
Compute the similarity distance of the target anomaly segment y to the subsequences within the motor data in x.
[d,i] = similarityDistance(x,y);
Using the first three indices in i, plot the three closest matching subsequences. These matches indicate potentially similar anomalies to the anomaly in y.
for k = 1:3 id = i(k):i(k)+len-1; plot(id,x(id),"--"); hold on end legend({"Time Series", "Match 1", "Match 2", "Match 3"}) hold off
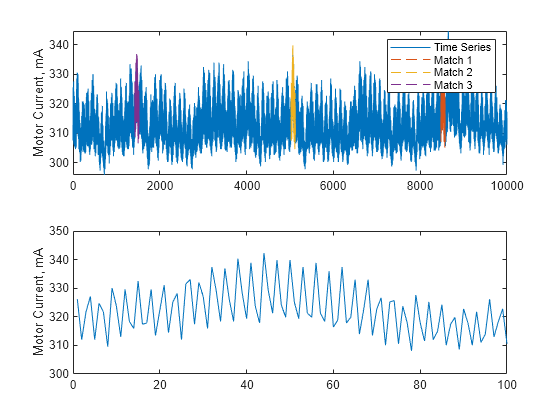
For comparison, plot the target anomaly sequence.
subplot(212) plot(y); hold on ylabel("Motor Current, mA")
Plot the data in the three matching subsequences with the target anomaly.
for k = 1:3 id = i(k):i(k)+len-1; plot(x(id),"--"); hold on end legend({"Target Anomaly", "Match 1", "Match 2", "Match 3"}) hold off
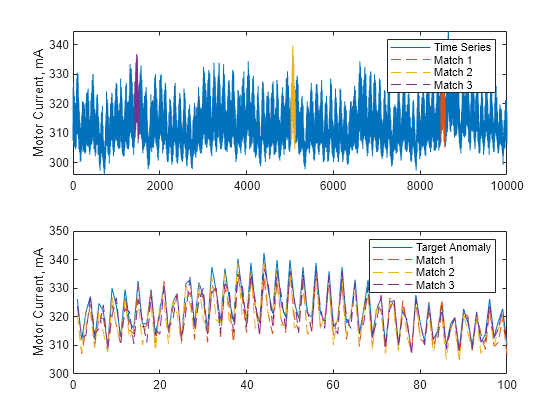
The matching subsequences appear similar to the target anomaly.
Input Arguments
Output Arguments
References
[1] Zhong, Sheng, and Abdullah Mueen. “MASS: Distance Profile of a Query over a Time Series.” Data Mining and Knowledge Discovery, vol. 38, no. 3, May 2024, pp. 1466–92. DOI.org (Crossref), https://doi.org/10.1007/s10618-024-01005-2.