smooth
Backward recursion of Bayesian nonlinear non-Gaussian state-space model
Since R2024a
Syntax
Description
smooth provides approximate posterior means and
covariances, conditioned on model parameters Θ and the full-sample response data, to summarize
the smoothing distribution of the state of a Bayesian nonlinear non-Gaussian state-space model
(bnlssm).
To compute the smoothed state distribution and likelihood,
smooth uses the forward-backward smoothing
method, in which it implements sequential Monte Carlo (SMC) to perform forward
filtering, and then it resamples and reweights particles (weighted
random samples) generated by SMC to perform backward smoothing.
[
returns approximate posterior means and covariances of the smoothing state distribution, for
each sampling time in the input response data, and the corresponding loglikelihood resulting
from performing backward recursion of, or smoothing, the input Bayesian nonlinear
state-space model. X,logL] = smooth(Mdl,Y,params)smooth evaluates the parameter map
Mdl.ParamMap by using the input vector of parameter values.
[
additionally returns smoothing results by sampling period using any of the input-argument
combinations in the previous syntaxes. X,logL,Output] = smooth(___)Output contains the following quantities:
Approximate loglikelihood values associated with the input data, input parameters, and particles
Approximate posterior means of smoothed state distribution
Approximate posterior covariance of smoothed state distribution
Effective sample size
Flags indicating which data the software used to smooth
Flags indicating resampling
Examples
This example uses simulated data to compute means of the approximate posterior smoothed state distribution of the following Bayesian nonlinear state-space model in equation. The state-space model contains two independent, stationary, autoregressive states each with a model constant. The observations are a nonlinear function of the states with Gaussian noise. The prior distribution of the parameters is flat. Symbolically, the system of equations is
and are the unconditional means of the corresponding states. The initial distribution moments of each state are their unconditional mean and covariance.
Create a Bayesian nonlinear state-space model characterized by the system. The observation equation is in equation form, that is, the function composing the states is nonlinear and the innovation series is additive, linear, and Gaussian. The Local Functions section contains two functions required to specify the Bayesian nonlinear state-space model: the state-space model parameter mapping function and the prior distribution of the parameters. You can use the functions only within this script.
Mdl = bnlssm(@paramMap,@priorDistribution)
Mdl =
bnlssm with properties:
ParamMap: @paramMap
ParamDistribution: @priorDistribution
ObservationForm: "equation"
Multipoint: [1×0 string]
ParticleOptions: [1×1 particleoptions]
Mdl is a bnlssm model specifying the state-space model structure and prior distribution of the state-space model parameters. Because Mdl contains unknown values, it serves as a template for posterior analysis with observations.
Simulate a series of 100 observations from the following stationary 2-D VAR process.
where the disturbance series are standard Gaussian random variables.
rng(1,"twister") % For reproducibility T = 100; thetatrue = [0.9; 1; -0.75; -1; 0.3; 0.2; 0.1]; MdlSim = varm(AR={diag(thetatrue([1 3]))},Covariance=diag(thetatrue(5:6).^2), ... Constant=thetatrue([2 4])); XSim = simulate(MdlSim,T);
Compose simulated observations using the following equation.
where the innovation series is a standard Gaussian random variable.
ysim = log(sum(exp(XSim - mean(XSim)),2)) + thetatrue(7)*randn(T,1);
To compute means of the approximate posterior smoothed state distribution, the smooth function requires response data and a model with known state-space model parameters. Choose a random set with the following constraints:
and are within the unit circle. Use to generate values.
and are real numbers. Use the distribution to generate values.
, , and are positive real numbers. Use the distribution to generate values.
theta13 = (-1+(1-(-1)).*rand(2,1)); theta24 = 3*randn(2,1); theta567 = chi2rnd(1,3,1); theta = [theta13(1); theta24(1); theta13(2); theta24(2); theta567];
Compute approximate smoothed state posterior means and corresponding loglikelihood by passing the Bayesian nonlinear model, simulated data, and parameter values to smooth.
[SmoothX,logL] = smooth(Mdl,ysim,theta); size(SmoothX)
ans = 1×2
100 4
logL
logL = -134.1053
SmoothX is a 100-by-4 matrix of approximate smoothed state posterior means, with rows corresponding to periods in the sample and columns corresponding to the state variables. The smooth function uses the forward-backward smoothing method (SMC and simulation smoothing by default) to obtain draws from the posterior smoothed state distribution. logL is the approximate loglikelihood function estimate evaluated at the data and parameter values.
Compare the loglikelihood logL and the loglikelihood computed using from the data simulation.
[SmoothXSim,logLSim] = smooth(Mdl,ysim,thetatrue); logLSim
logLSim = -0.2036
logLSim > logL, suggesting that the model evaluated at thetaSim has the better fit.
Plot the two sets of approximate smoothed state posterior means with the true state values.
figure tiledlayout(2,1) nexttile plot([SmoothX(:,1) SmoothXSim(:,1) XSim(:,1)]) title("x_{t,1}") legend("Smoothed State, random \theta","Smoothed State, true \theta","XSim") nexttile plot([SmoothX(:,3) SmoothXSim(:,3) XSim(:,2)]) title("x_{t,3}") legend("Smoothed State, random \theta","Smoothed State, true \theta","XSim")

The approximate smoothed state posterior means using the true value of and the simulated state paths are close. The approximate smoothed state posterior means are far from the simulated state paths.
Local Functions
These functions specify the state-space model parameter mappings, in equation form, and log prior distribution of the parameters.
function [A,B,C,D,Mean0,Cov0,StateType] = paramMap(theta) A = @(x)blkdiag([theta(1) theta(2); 0 1],[theta(3) theta(4); 0 1])*x; B = [theta(5) 0; 0 0; 0 theta(6); 0 0]; C = @(x)log(exp(x(1)-theta(2)/(1-theta(1))) + ... exp(x(3)-theta(4)/(1-theta(3)))); D = theta(7); Mean0 = [theta(2)/(1-theta(1)); 1; theta(4)/(1-theta(3)); 1]; Cov0 = diag([theta(5)^2/(1-theta(1)^2) 0 theta(6)^2/(1-theta(3)^2) 0]); StateType = [0; 1; 0; 1]; % Stationary state and constant 1 processes end function logprior = priorDistribution(theta) paramconstraints = [(abs(theta([1 3])) >= 1) (theta(5:7) <= 0)]; if(sum(paramconstraints)) logprior = -Inf; else logprior = 0; % Prior density is proportional to 1 for all values % in the parameter space. end end
This example shows how to use smooth and Bayesian optimization to calibrate a Bayesian nonlinear state-space. Consider this nonlinear state-space model.
where has a flat prior and the series and are standard Gaussian random variables.
Simulate Series
Simulate a series of 100 observations from the following stationary 2-D VAR process.
where the series and are standard Gaussian random variables.
rng(500,"twister") % For reproducibility T = 100; thetaDGP = [0.5; 0.6; -1; 2; 0.75]; numparams = numel(thetaDGP); MdlSim = arima(AR=thetaDGP(1),Variance=thetaDGP(2).^2, ... Constant=0); xsim = simulate(MdlSim,T); ysim = exp(thetaDGP(3).*xsim) + thetaDGP(4) + thetaDGP(5)*randn(T,1);
Create Bayesian Nonlinear Model
Create a Bayesian nonlinear state-space model. The Local Functions section contains two functions required to specify the Bayesian nonlinear state-space model: the state-space model parameter mapping function and the prior distribution of the parameters. You can use the functions only within this script. Specify Multipoint=["A" "C"] because the state-transition and measurement-sensitivity parameter mappings in paraMap can evaluate multiple particles simultaneously.
Mdl = bnlssm(@paramMap,@priorDistribution,Multipoint=["A" "C"]);
Perform Random Exploration
One way to explore the parameter space for the point that maximizes the likelihood is by random exploration:
Randomly generated set of parameters.
Compute the loglikelihood for that set derived from the approximate posterior smoothed state distribution. Generate 5000 particles for the SMC algorithm.
Repeat steps 1 and 2 for 100 epochs.
Choose the set of parameters that yields the largest loglikelihood.
Choose a random set using the following arbitrary recipe:
.
and are .
and are.
numepochs = 100; numparticles = 5000; theta = NaN(numparams,numepochs); logL = NaN(numepochs,1); for j = 1:numepochs theta(:,j) = [(-1+(1-(-1)).*rand(1,1)); chi2rnd(1,1,1); ... 2*randn(2,1); chi2rnd(1,1,1);]; [~,logL(j)] = smooth(Mdl,ysim,theta(:,j),NumParticles=numparticles); end
Choose the set of parameters that maximizes the loglikelihood.
[bestlogL,idx] = max(logL); bestTheta = theta(:,idx); [bestTheta thetaDGP]
ans = 5×2
0.9587 0.5000
0.7193 0.6000
-1.3370 -1.0000
2.3146 2.0000
1.1942 0.7500
The values that maximize the likelihood are fairly close to the values that generated the data.
Perform Bayesian Optimization
Bayesian optimization requires you to specify which variables require optimization and their support. To do this, use optimizableVariable to provide a name to the variable and its support. This example limits the support of each variable to a small interval; you must experiment with the support for your application.
thetaOp(5) = optimizableVariable("theta5",[0,2]); thetaOp(1) = optimizableVariable("theta1",[0,0.9]); thetaOp(2) = optimizableVariable("theta2",[0,2]); thetaOp(3) = optimizableVariable("theta3",[-3,0]); thetaOp(4) = optimizableVariable("theta4",[-3,3]);
thetaOp is an optimizableVariable object specifying the name and support of each variable of .
bayesopt accepts a function handle to the function that you want to minimize with respect to one argument and the optimizable variable specifications. Therefore, provide the function handle neglog, which is associated with the negative loglikelihood function smoothneglogl located in Local Functions. Specify the Expected Improvement Plus acquisition function and an exploration ratio of 1.
neglogl = @(var)smoothneglogl(var,Mdl,ysim,numparticles); rng(1,"twister") results = bayesopt(neglogl,thetaOp,AcquisitionFunctionName="expected-improvement-plus", ... ExplorationRatio=1);
|==================================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | theta1 | theta2 | theta3 | theta4 | theta5 |
| | result | | runtime | (observed) | (estim.) | | | | | |
|==================================================================================================================================================|
| 1 | Best | 1127.7 | 0.4179 | 1127.7 | 1127.7 | 0.0761 | 0.51116 | -0.78522 | -2.272 | 0.44888 |
| 2 | Best | 322.81 | 0.31024 | 322.81 | 369.76 | 0.5021 | 0.8957 | -0.11662 | -1.1518 | 1.8165 |
| 3 | Best | 245.79 | 0.098121 | 245.79 | 245.82 | 0.67392 | 0.54178 | -2.091 | -0.82814 | 0.63451 |
| 4 | Accept | 380.45 | 0.10544 | 245.79 | 245.98 | 0.74179 | 1.8872 | -1.9159 | -2.5691 | 1.596 |
| 5 | Accept | 279.79 | 0.089381 | 245.79 | 246.06 | 0.60214 | 0.50418 | -2.9322 | -1.1527 | 0.14964 |
| 6 | Best | 186.84 | 0.27795 | 186.84 | 186.74 | 0.66193 | 1.9357 | -0.33867 | 2.9992 | 1.8346 |
| 7 | Best | 153.66 | 0.47146 | 153.66 | 153.7 | 0.89991 | 1.5878 | -1.5033 | 2.9704 | 1.0028 |
| 8 | Accept | 160.98 | 0.19096 | 153.66 | 153.81 | 0.80693 | 1.6709 | -0.82659 | 2.0055 | 0.52136 |
| 9 | Accept | 208.77 | 0.71719 | 153.66 | 155.96 | 0.89976 | 0.1645 | -0.23015 | 1.7263 | 0.64494 |
| 10 | Accept | 192.1 | 0.49989 | 153.66 | 169.31 | 0.80968 | 0.61633 | -0.5705 | 2.9999 | 0.73426 |
| 11 | Accept | 5074.3 | 0.47124 | 153.66 | 157.3 | 6.7446e-05 | 0.21918 | -0.44794 | 2.9988 | 0.13107 |
| 12 | Accept | 3776.4 | 0.55923 | 153.66 | 159.36 | 0.35597 | 1.1767 | -0.10703 | -2.9996 | 0.54014 |
| 13 | Accept | 772.4 | 0.61843 | 153.66 | 158.8 | 0.15145 | 0.12378 | -2.9147 | -1.8421 | 0.7186 |
| 14 | Accept | 197.02 | 0.30931 | 153.66 | 159.42 | 0.86146 | 1.9966 | -2.0547 | 2.9694 | 0.49212 |
| 15 | Accept | 207.43 | 0.14253 | 153.66 | 176.65 | 0.54225 | 1.9994 | -0.8381 | 0.8757 | 1.3717 |
| 16 | Accept | 211.23 | 0.18293 | 153.66 | 159.99 | 0.64091 | 0.28665 | -1.5521 | -0.49818 | 0.067427 |
| 17 | Accept | 167.71 | 0.12634 | 153.66 | 160.4 | 0.82594 | 1.999 | -0.47576 | 1.2389 | 0.62764 |
| 18 | Accept | 189.02 | 0.32769 | 153.66 | 175.54 | 0.89987 | 1.9649 | -1.2043 | 1.7928 | 1.5587 |
| 19 | Accept | 384.72 | 0.32266 | 153.66 | 173.57 | 0.25092 | 1.9786 | -0.13459 | -1.5242 | 1.6339 |
| 20 | Accept | 171.29 | 0.25017 | 153.66 | 156.34 | 0.21772 | 1.4343 | -0.0077847 | 1.3683 | 1.2372 |
|==================================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | theta1 | theta2 | theta3 | theta4 | theta5 |
| | result | | runtime | (observed) | (estim.) | | | | | |
|==================================================================================================================================================|
| 21 | Accept | 306.01 | 0.089676 | 153.66 | 156.54 | 0.18279 | 1.7441 | -1.517 | -0.12855 | 0.067269 |
| 22 | Accept | 361.45 | 0.55589 | 153.66 | 156.1 | 0.89994 | 0.086227 | -0.94613 | -2.1633 | 1.1276 |
| 23 | Accept | 314.99 | 0.12941 | 153.66 | 156.07 | 0.33385 | 0.36509 | -2.8442 | 1.0493 | 0.021546 |
| 24 | Accept | 298.17 | 0.19835 | 153.66 | 156.06 | 6.6241e-05 | 1.5744 | -0.62369 | -0.94811 | 0.94084 |
| 25 | Accept | 200.83 | 0.22656 | 153.66 | 156.09 | 0.54857 | 0.92469 | -2.8041 | 1.9448 | 1.8312 |
| 26 | Accept | 275.97 | 0.10842 | 153.66 | 156.15 | 0.00016917 | 1.8928 | -1.6495 | 0.58567 | 0.5557 |
| 27 | Accept | 328.4 | 0.081449 | 153.66 | 156.1 | 0.89194 | 0.71832 | -2.4274 | -2.9749 | 0.25469 |
| 28 | Accept | 223.12 | 0.41265 | 153.66 | 156.03 | 0.72871 | 1.6159 | -0.073243 | 0.44319 | 1.2739 |
| 29 | Accept | 233.58 | 0.17645 | 153.66 | 156.14 | 0.14766 | 1.1859 | -2.542 | 0.87784 | 1.6968 |
| 30 | Accept | 315.82 | 0.095437 | 153.66 | 155.33 | 0.26821 | 1.0919 | -2.0256 | -0.89028 | 0.022533 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 14.6733 seconds
Total objective function evaluation time: 8.5634
Best observed feasible point:
theta1 theta2 theta3 theta4 theta5
_______ ______ _______ ______ ______
0.89991 1.5878 -1.5033 2.9704 1.0028
Observed objective function value = 153.6623
Estimated objective function value = 155.3334
Function evaluation time = 0.47146
Best estimated feasible point (according to models):
theta1 theta2 theta3 theta4 theta5
_______ ______ _______ ______ ______
0.89991 1.5878 -1.5033 2.9704 1.0028
Estimated objective function value = 155.3334
Estimated function evaluation time = 0.47138

results is a BayesianOptmization object containing properties summarizing the results of Bayesian optimization.
Extract the value that minimizes the negative loglikelihood from results by using bestPoint.
restbl = [bestPoint(results); num2cell(thetaDGP')]; restbl.Properties.RowNames = ["calibrated" "true"]
restbl=2×5 table
theta1 theta2 theta3 theta4 theta5
_______ ______ _______ ______ ______
calibrated 0.89991 1.5878 -1.5033 2.9704 1.0028
true 0.5 0.6 -1 2 0.75
The results are fairly close to the values that generated the data.
Local Functions
These functions specify the state-space model parameter mappings, in equation form, and the log prior distribution of the parameters, and they compute the negative loglikelihood of the model.
function [A,B,C,D,Mean0,Cov0,StateType] = paramMap(theta) A = @(x)theta(1)*x; B = theta(2); C = @(x)exp(theta(3).*x) + theta(4); D = theta(5); Mean0 = 0; Cov0 = 1; StateType = 0; % Stationary state process end function logprior = priorDistribution(theta) paramconstraints = [abs(theta(1)) >= 1; theta([2 4]) <= 0]; if(sum(paramconstraints)) logprior = -Inf; else logprior = 0; % Prior density is proportional to 1 for all values % in the parameter space. end end function neglogL = smoothneglogl(theta,mdl,resp,np) theta = table2array(theta); [~,logL] = smooth(mdl,resp,theta,NumParticles=np); neglogL = -logL; end
smooth runs SMC to forward filter the state-space model, which includes resampling particles. To assess the quality of the sample, including whether any posterior smoothed state distribution is close to degenerate, you can monitor these algorithms by returning the third output of smooth.
Consider this nonlinear state-space model.
where has a flat prior and the series and are standard Gaussian random variables.
Simulate a series of 100 observations from the following stationary 2-D VAR process.
where the series and are standard Gaussian random variables.
rng(500,"twister") % For reproducibility T = 100; thetaDGP = [0.5; 0.6; -1; 2; 0.75]; numparams = numel(thetaDGP); MdlSim = arima(AR=thetaDGP(1),Variance=sqrt(thetaDGP(2)), ... Constant=0); xsim = simulate(MdlSim,T); y = exp(thetaDGP(3).*xsim) + thetaDGP(4) + thetaDGP(5)*randn(T,1);
Create a Bayesian nonlinear state-space model, and specify Multipoint=["A" "C"]. The Local Functions section contains the required functions specifying the Bayesian nonlinear state-space model structure and joint prior distribution.
Mdl = bnlssm(@paramMap,@priorDistribution,Multipoint=["A" "C"]);
Approximate the posterior smoothed state distribution of the state-space model. As in the Calibrate State-Space Model Parameters example, choose a random set of initial parameter values. Specify the resampling residuals for the SMC. Return the third output.
theta0 = [(-1+(1-(-1)).*rand(1,1)); chi2rnd(1,1,1); ... 2*randn(2,1); chi2rnd(1,1,1);]; [~,~,Output] = smooth(Mdl,y,theta0,Resample="residual");
Output is a 100-by-1 structure array containing several fields, one set of fields for each observation, including:
SmoothedStatesCov— Approximate posterior smoothed state distribution covariance for the states at each sampling timeDataUsed— Whethersmoothused an observation for posterior estimationResample— Whethersmoothresampled the particles associated with an observation
Plot the approximate posterior smoothed state covariances.
figure
plot([Output.SmoothedStatesCov])
title("Approx. Post. Smoothed State Covariances")
Any covariance close to 0 indicates a close-to-degenerate distribution. No covariances in the analysis are close to 0.
Determine whether smooth omitted any observations from posterior estimation.
anyObsOmitted = sum([Output.DataUsed]) ~= T
anyObsOmitted = logical
0
anyObsOmitted = 0 indicates that smooth used all observations.
Determine whether smooth resampled any particles associated with observations.
whichResampled = find([Output.Resampled] == true)
whichResampled = 1×2
37 56
smooth resampled particles associated with observations 37 and 56.
Local Functions
These functions specify the state-space model parameter mappings, in equation form, and the log prior distribution of the parameters, and they compute the negative loglikelihood of the model.
function [A,B,C,D,Mean0,Cov0,StateType] = paramMap(theta) A = @(x)theta(1)*x; B = theta(2); C = @(x)exp(theta(3).*x) + theta(4); D = theta(5); Mean0 = 0; Cov0 = 1; StateType = 0; % Stationary state process end function logprior = priorDistribution(theta) paramconstraints = [abs(theta(1)) >= 1; theta([2 4]) <= 0]; if(sum(paramconstraints)) logprior = -Inf; else logprior = 0; % Prior density is proportional to 1 for all values % in the parameter space. end end
This example compares the performance of several SMC proposal particle resampling methods for obtaining smoothed state estimates of a quasi-nonnegative constrained state space model, which models nonnegative state quantities such as interest rates and prices:
and are iid standard Gaussian random variables.
Generate Artificial Data
Consider the following data-generating process (DGP)
Generate a random series of 200 observations from the DGP.
a0 = 0.1; a1 = 0.95; b = 1; d = 0.5; theta = [a0; a1; b; d]; T = 50; % Preallocate variables x = zeros(T,1); y = zeros(T,1); rng(0,"twister") % For reproducibility u = randn(T,1); e = randn(T,1); for t = 2:T x(t) = max(0,a0 + a1*x(t-1)) + b*u(t); y(t) = x(t) + d*e(t); end
Create Bayesian Nonlinear State-Space Model
The Local Functions section contains two functions required to specify the Bayesian nonlinear state-space model: the state-space model parameter mapping function paramMap and the prior distribution of the parameters priorDistribution. You can use the functions only within this script.
The paramMap function has these qualities:
Functions can simultaneously evaluate the state equation for multiple values of
A. Therefore, you can speed up calculations by specifying theMultipoint="A"option.The observation equation is in equation form, that is, the function composing the states is nonlinear and the innovation series is additive, linear, and Gaussian.
The priorDistribution function specifies a flat prior, which has a density that is proportional to 1 everywhere in the parameter space; it constrains the error standard deviations to be positive.
Create a Bayesian nonlinear state-space model characterized by the system.
Mdl = bnlssm(@paramMap,@priorDistribution,Multipoint="A");Obtain Smoothed State Estimates Using Each Proposal Sampler Method
Obtain smoothed state estimates using the joint distribution of the parameters, at a randomly drawn set of values in [0,1], using the bootstrap, optimal, and one-pass unscented particle resampling methods. Specify drawing 5000 particles for SMC.
numParticles = 5000; params = rand(4,1); smcMethod = ["bootstrap" "optimal" "unscented"]; for j = 3:-1:1 % Set last element first to preallocate entire cell vector xSmooth{j} = smooth(Mdl,y,params,NewSamples=smcMethod(j),NumParticles=numParticles); end
Compare the posterior means from each method with the true values.
figure tiledlayout(3,1) for j = 1:3 nexttile plot([x xSmooth{j}]) title("SMC Method: " + upper(smcMethod(j))) end legend("True","Smooth")
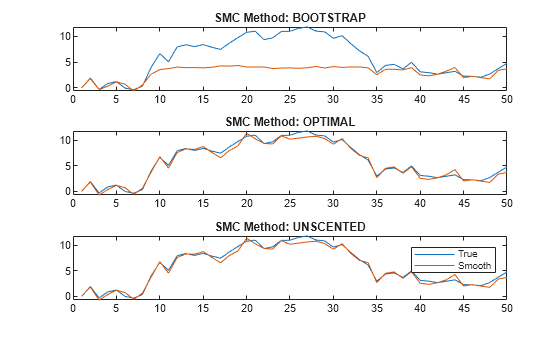
The figure shows that, in this case, the optimal and one-pass unscented methods yield smoothed state estimates closer to the true values than the bootstrap method. For the bootstrap method, smoothed state estimates in periods 10 through 35 level off around 5, while the true values jump as high as 10. The reason is the bootstrap filter updates particles solely by the transition equation—observations do not inform how particles are updated unlike the optimal and unscented methods.
Regardless of method, smooth weighs particles by the observation densities. In this example, the observation equation is (as specified in params). For the bootstrap filter, the normally distributed observation innovation, with small loading 0.17, cannot accommodate large jumps, such as from 5 to 10. Consequently, the weights are degenerate: the largest particle takes all the weight, and smooth discards the remaining particles during resampling because they have zero weight. The smoothed states level off until period 35 when the observations fall below 5.
Local Functions
These functions specify the state-space model parameter mappings, in equation form, and log prior distribution of the parameters.
function [A,B,C,D,mean0,Cov0] = paramMap(params) a0 = params(1); a1 = params(2); b = params(3); d = params(4); A = @(x) max(0,a0+a1.*x); B = b; C = 1; D = d; mean0 = 0; Cov0 = 1; end function logprior = priorDistribution(theta) paramconstraints = theta(3:4) <= 0; % b and d are greater than 0 if(sum(paramconstraints)) logprior = -Inf; else logprior = 0; % Prior density is proportional to 1 for all values % in the parameter space. end end
Input Arguments
Name-Value Arguments
Output Arguments
Tips
Smoothing has several advantages over filtering.
The smoothed state estimator is more accurate than the online filter state estimator because it is based on the full-sample data, rather than only observations up to the estimated sampling time.
A stable approximation to the gradient of the loglikelihood function, which is important for numerical optimization, is available from the smoothed state samples of the simulation smoother (finite differences of the approximated loglikelihood computed from the filter state estimates is numerically unstable).
You can use the simulation smoother to perform Bayesian estimation of the nonlinear state-space model via the Metropolis-within-Gibbs sampler.
Unless you set
Cutoff=0,smoothresamples particles according to the specified resampling methodResample. Although resampling particles with high weights improves the results of the SMC, you should also allow the sampler traverse the proposal distribution to obtain novel, high-weight particles. To do this, experiment withCutoff.Avoid an arbitrary choice of the initial state distribution.
bnlssmfunctions generate the initial particles from the specified initial state distribution, which impacts the performance of the nonlinear filter. If the initial state specification is bad enough, importance weights concentrate on a small number of particles in the first SMC iteration, which might produce unreasonable filtering results. This vulnerability of the nonlinear model behavior contrasts with the stability of the Kalman filter for the linear model, in which the initial state distribution usually has little impact on the filter because the prior is washed out as it processes data.
Algorithms
smooth accommodates missing data by not updating filtered state estimates corresponding to missing observations. In other words, suppose there is a missing observation at period t. Then, the state forecast for period t based on the previous t – 1 observations and filtered state for period t are equivalent.
Alternative Functionality
To monitor the forward-filtering stage or to conduct a Gibbs sampler, use simsmooth instead of
smooth.
References
[6] Fernández-Villaverde, Jesús, and Juan F. Rubio-Ramírez. "Estimating Macroeconomic Models: A Likelihood Approach." Review of Economic Studies 70(October 2007): 1059–1087. https://doi.org/10.1111/j.1467-937X.2007.00437.x.