Train and Apply Multilayer Shallow Neural Networks
Tip
To train a deep learning network, use trainnet.
This topic presents part of a typical multilayer shallow network workflow. For more information and other steps, see Multilayer Shallow Neural Networks and Backpropagation Training.
When the network weights and biases are initialized, the network is ready for training.
The multilayer feedforward network can be trained for function approximation (nonlinear
regression) or pattern recognition. The training process requires a set of examples of
proper network behavior—network inputs p and target outputs
t.
The process of training a neural network involves tuning the values of the weights and
biases of the network to optimize network performance, as defined by the network
performance function net.performFcn. The default performance function
for feedforward networks is mean square error mse—the average squared error between
the network outputs a and the target outputs t. It is
defined as follows:
(Individual squared errors can also be weighted. See Train Neural Networks with Error Weights.) There are two different ways in
which training can be implemented: incremental mode and batch mode. In incremental mode,
the gradient is computed and the weights are updated after each input is applied to the
network. In batch mode, all the inputs in the training set are applied to the network
before the weights are updated. This topic describes batch mode training with the train command. Incremental training with the adapt command is discussed in Incremental Training with adapt. For most
problems, when using the Deep Learning Toolbox™ software, batch training is significantly faster and produces smaller errors
than incremental training.
For training multilayer feedforward networks, any standard numerical optimization algorithm can be used to optimize the performance function, but there are a few key ones that have shown excellent performance for neural network training. These optimization methods use either the gradient of the network performance with respect to the network weights, or the Jacobian of the network errors with respect to the weights.
The gradient and the Jacobian are calculated using a technique called the backpropagation algorithm, which involves performing computations backward through the network. The backpropagation computation is derived using the chain rule of calculus and is described in Chapters 11 (for the gradient) and 12 (for the Jacobian) of [HDB96].
Training Algorithms
As an illustration of how the training works, consider the simplest optimization algorithm — gradient descent. It updates the network weights and biases in the direction in which the performance function decreases most rapidly, the negative of the gradient. One iteration of this algorithm can be written as
where xk is a vector of current weights and biases, gk is the current gradient, and αk is the learning rate. This equation is iterated until the network converges.
A list of the training algorithms that are available in the Deep Learning Toolbox software and that use gradient- or Jacobian-based methods, is shown in the following table.
For a detailed description of several of these techniques, see also Hagan, M.T., H.B. Demuth, and M.H. Beale, Neural Network Design, Boston, MA: PWS Publishing, 1996, Chapters 11 and 12.
Function | Algorithm |
|---|---|
Levenberg-Marquardt | |
Bayesian Regularization | |
BFGS Quasi-Newton | |
Resilient Backpropagation | |
Scaled Conjugate Gradient | |
Conjugate Gradient with Powell/Beale Restarts | |
Fletcher-Powell Conjugate Gradient | |
Polak-Ribiére Conjugate Gradient | |
One Step Secant | |
Variable Learning Rate Gradient Descent | |
Gradient Descent with Momentum | |
Gradient Descent |
The fastest training function is generally trainlm, and it is the default training function for feedforwardnet. The quasi-Newton method, trainbfg, is also quite fast. Both of these methods tend to be less
efficient for large networks (with thousands of weights), since they require more memory
and more computation time for these cases. Also, trainlm performs better on function fitting (nonlinear regression)
problems than on pattern recognition problems.
When training large networks, and when training pattern recognition networks,
trainscg and trainrp are good choices. Their memory requirements are relatively small,
and yet they are much faster than standard gradient descent algorithms.
See Choose a Multilayer Neural Network Training Function for a full comparison of the performances of the training algorithms shown in the table above.
As a note on terminology, the term “backpropagation” is sometimes used to refer specifically to the gradient descent algorithm, when applied to neural network training. That terminology is not used here, since the process of computing the gradient and Jacobian by performing calculations backward through the network is applied in all of the training functions listed above. It is clearer to use the name of the specific optimization algorithm that is being used, rather than to use the term backpropagation alone.
Also, the multilayer network is sometimes referred to as a backpropagation network. However, the backpropagation technique that is used to compute gradients and Jacobians in a multilayer network can also be applied to many different network architectures. In fact, the gradients and Jacobians for any network that has differentiable transfer functions, weight functions and net input functions can be computed using the Deep Learning Toolbox software through a backpropagation process. You can even create your own custom networks and then train them using any of the training functions in the table above. The gradients and Jacobians will be automatically computed for you.
Training Example
To illustrate the training process, execute the following commands:
load bodyfat_dataset
net = feedforwardnet(20);
[net,tr] = train(net,bodyfatInputs,bodyfatTargets);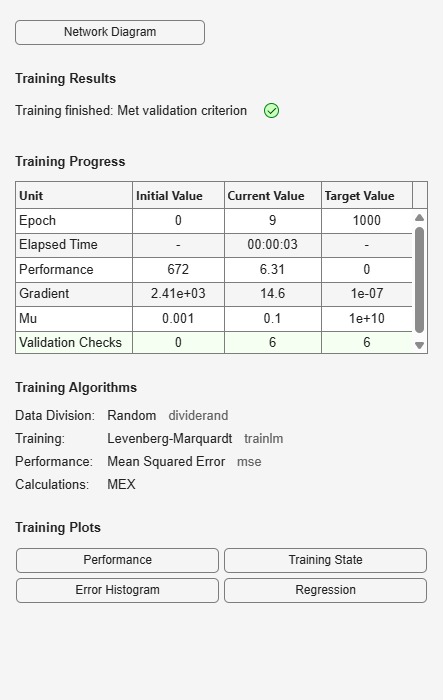
Notice that you did not need to issue the configure command, because the configuration is done automatically by the
train function. The training window will
appear during training, as shown in the following figure. (If you do not want to have
this window displayed during training, you can set the parameter
net.trainParam.showWindow to false. If you want
training information displayed in the command line, you can set the parameter
net.trainParam.showCommandLine to true.)
This window shows that the data has been divided using the dividerand function, and the Levenberg-Marquardt (trainlm) training method has been used with the mean square error
performance function. Recall that these are the default settings for feedforwardnet.
During training, the progress is constantly updated in the training window. Of most
interest are the performance, the magnitude of the gradient of performance and the
number of validation checks. The magnitude of the gradient and the number of validation
checks are used to terminate the training. The gradient will become very small as the
training reaches a minimum of the performance. If the magnitude of the gradient is less
than 1e-5, the training will stop. This limit can be adjusted by setting the parameter
net.trainParam.min_grad. The number of validation checks
represents the number of successive iterations that the validation performance fails to
decrease. If this number reaches 6 (the default value), the training will stop. In this
run, you can see that the training did stop because of the number of validation checks.
You can change this criterion by setting the parameter
net.trainParam.max_fail. (Note that your results may be different
than those shown in the training figure, because of the random setting of the initial
weights and biases.)
There are other criteria that can be used to stop network training. They are listed in the following table.
Parameter | Stopping Criteria |
|---|---|
min_grad | Minimum Gradient Magnitude |
max_fail | Maximum Number of Validation Increases |
time | Maximum Training Time |
goal | Minimum Performance Value |
epochs | Maximum Number of Training Epochs (Iterations) |
The training will also stop if you click the stop button in the training window. You
might want to do this if the performance function fails to decrease significantly over
many iterations. It is always possible to continue the training by reissuing the
train command shown above. It will
continue to train the network from the completion of the previous run.
From the training window, you can access four plots: performance, training state, error histogram, and regression. The performance plot shows the value of the performance function versus the iteration number. It plots training, validation, and test performances. The training state plot shows the progress of other training variables, such as the gradient magnitude, the number of validation checks, etc. The error histogram plot shows the distribution of the network errors. The regression plot shows a regression between network outputs and network targets. You can use the histogram and regression plots to validate network performance, as is discussed in Analyze Shallow Neural Network Performance After Training.
Use the Network
After the network is trained and validated, the network object can be used to calculate the network response to any input. For example, if you want to find the network response to the fifth input vector in the building data set, you can use the following
a = net(bodyfatInputs(:,5))
a = 27.3740
If you try this command, your output might be different, depending on the state of your random number generator when the network was initialized. Below, the network object is called to calculate the outputs for a concurrent set of all the input vectors in the body fat data set. This is the batch mode form of simulation, in which all the input vectors are placed in one matrix. This is much more efficient than presenting the vectors one at a time.
a = net(bodyfatInputs);
Each time a neural network is trained, can result in a different solution due to different initial weight and bias values and different divisions of data into training, validation, and test sets. As a result, different neural networks trained on the same problem can give different outputs for the same input. To ensure that a neural network of good accuracy has been found, retrain several times.
There are several other techniques for improving upon initial solutions if higher accuracy is desired. For more information, see Improve Shallow Neural Network Generalization and Avoid Overfitting.