predictAndUpdateState
(Not recommended) Predict responses using a trained recurrent neural network and update the network state
predictAndUpdateState is not recommended. Instead, use the
predict function and use
the state output to update the State property of the neural network. For more information,
see Version
History.
Syntax
Description
You can make predictions using a trained deep learning network on either a CPU
or GPU. Using a GPU requires
a Parallel Computing Toolbox™ license and a supported GPU device. For information about supported devices, see
GPU Computing Requirements (Parallel Computing Toolbox). Specify the hardware requirements using the ExecutionEnvironment name-value argument.
[
predicts responses for data in updatedNet,Y] = predictAndUpdateState(recNet,sequences)sequences using the trained
recurrent neural network recNet and updates the network
state.
This function supports recurrent neural networks only. The input
recNet must have at least one recurrent layer such as an
LSTM layer or a custom layer with state parameters.
[
predicts the responses for the data in the numeric or cell arrays
updatedNet,Y] = predictAndUpdateState(recNet,X1,...,XN)X1, …, XN for the multi-input network
recNet. The input Xi corresponds to the
network input recNet.InputNames(i).
[
makes predictions using the multi-input network updatedNet,Y] = predictAndUpdateState(recNet,mixed)recNet with
data of mixed data types.
[updatedNet,
predicts responses for the Y1,...,YM] = predictAndUpdateState(___)M outputs of a multi-output network
using any of the previous input arguments. The output Yj
corresponds to the network output recNet.OutputNames(j). To
return categorical outputs for the classification output layers, set the ReturnCategorical option to 1 (true).
[___] = predictAndUpdateState(___,
makes predictions with additional options specified by one or more name-value
arguments using any of the previous syntaxes. For example,
Name=Value)MiniBatchSize=27 makes predictions using mini-batches of size 27.
Tip
When you make predictions with sequences of different lengths,
the mini-batch size can impact the amount of padding added to the input data, which can result
in different predicted values. Try using different values to see which works best with your
network. To specify mini-batch size and padding options, use the MiniBatchSize and SequenceLength
options, respectively.
Examples
Predict responses using a trained recurrent neural network and update the network state.
Suppose you have a long short-term memory (LSTM) network
net that was trained on the Japanese Vowels data set as
described in [1] and [2]. Suppose the network was trained on the sequences
sorted by sequence length with a mini-batch size of 27.
View the network architecture.
net.Layers
ans =
5x1 Layer array with layers:
1 'sequenceinput' Sequence Input Sequence input with 12 dimensions
2 'lstm' LSTM LSTM with 100 hidden units
3 'fc' Fully Connected 9 fully connected layer
4 'softmax' Softmax softmax
5 'classoutput' Classification Output crossentropyex with '1' and 8 other classes
Load the test data.
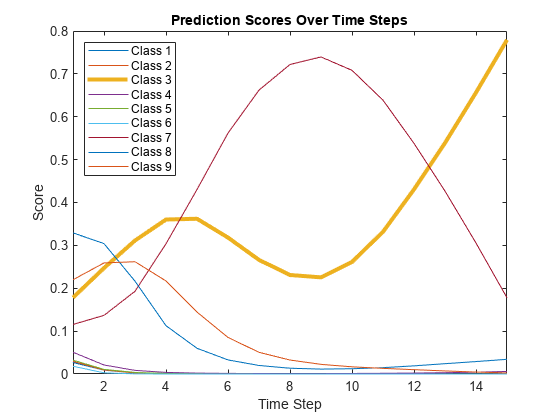
load JapaneseVowelsTestDataLoop over the time steps in a sequence. Predict the scores of each time step and update the network state.
X = XTest{94};
numTimeSteps = size(X,2);
for i = 1:numTimeSteps
v = X(:,i);
[net,score] = predictAndUpdateState(net,v);
scores(:,i) = score;
endPlot the prediction scores. The plot shows how the prediction scores change between time steps.
classNames = string(net.Layers(end).Classes); figure lines = plot(scores'); xlim([1 numTimeSteps]) legend("Class " + classNames,Location="northwest") xlabel("Time Step") ylabel("Score") title("Prediction Scores Over Time Steps")
Highlight the prediction scores over time steps for the correct class.
trueLabel = TTest(94); lines(trueLabel).LineWidth = 3;
Display the final time step prediction in a bar chart.
figure bar(score) title("Final Prediction Scores") xlabel("Class") ylabel("Score")

Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
Alternatives
For recurrent neural networks with a single classification layer only, you can compute
the predicted classes and scores and update the network state using the classifyAndUpdateState function.
To compute the activations of a network layer, use the activations
function. The activations
function does not update the network state.
To make predictions without updating the network state, use the classify
function or the predict
function.
References
[1] M. Kudo, J. Toyama, and M. Shimbo. "Multidimensional Curve Classification Using Passing-Through Regions." Pattern Recognition Letters. Vol. 20, No. 11–13, pages 1103–1111.
[2] UCI Machine Learning Repository: Japanese Vowels Dataset. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
Extended Capabilities
Version History
Introduced in R2017bSee Also
dlnetwork | minibatchpredict | predict | scores2label | sequenceInputLayer | lstmLayer | bilstmLayer | gruLayer | classifyAndUpdateState