spapi
Spline interpolation
Syntax
Description
spline = spapi(knots,x,y)
k = length(knots) - length(x)
knots for which (*) f(x(j)) = y(:,j), all j.
x are the same, then:
with and Dmf the m-th derivative of f. In this case, the r-fold repetition of a site z in x corresponds to the prescribing of value and the first r – 1 derivatives of f at z. To match the average of all data values with the same data instead, call spapi with an additional fourth argument.
The data values, y(:,j), can be scalars, vectors, matrices, or ND-arrays.
spapi( , with k,x,y)k a positive integer, specifies the desired spline order, k. In this case the spapi function calls the aptknt function to determine a workable, but not necessarily optimal, knot sequence for the given sites x. In other words, the command spapi(k,x,y) has the same effect as the more explicit command spapi(aptknt(x,k),x,y).
spapi({knork1,...,knorkm},{x1,...,xm},y) returns the B-form of a tensor-product spline interpolant to gridded data. Here, each knorki is either a knot sequence, or a positive integer specifying the polynomial order used in the i-th variable. The spapi function then provides a corresponding knot sequence for the i-th variable. Further, y must be an (r+m)-dimensional array, with y(:,i1,...,im) the datum to fit at the site [x{1}(i1),...,x{m}(im)], for all i1, ..., im. In contrast to the univariate case, if the spline is scalar-valued, then y can be an m-dimensional array.
spapi(...,'noderiv') with the character vector or string scalar 'noderiv' as a fourth argument, has the same effect as spapi(...) except that data values sharing the same site are interpreted differently. With the fourth argument present, the average of the data values with the same data site is interpolated at such a site. Without it, data values with the same data site are interpreted as values of successive derivatives to be matched at such a site, as described above, in the first paragraph of this Description.
Examples
The function spapi([0 0 0 0 1 2 2 2 2],[0 1 1 1 2],[2 0 1 2 -1]) produces the unique cubic spline f on the interval [0...2] with exactly one interior knot, at 1, that satisfies the five conditions
These include 3-fold matching at 1, i.e., matching there to prescribed values of the function and its first two derivatives.
Here is an example of osculatory interpolation, to values y and slopes s at the sites x by a quintic spline:
sp = spapi(augknt(x,6,2),[x,x,min(x),max(x)],[y,s,ddy0,ddy1]);
with ddy0 and ddy1 values for the second derivative at the endpoints.
As a related example, if you want to interpolate the sin(x) function at the distinct data sites by a cubic spline, and to match its slope at a subsequence x(s), then call the spapi function with these arguments:
sp = spapi(4,[x x(s)], [sin(x) cos(x(s))]).
The aptknt function will provide a suitable knot sequence. If you want to interpolate the same data by quintic splines, then simply change the value 4 to 6.
As a bivariate example, here is a bivariate interpolant.
x = -2:.5:2; y = -1:.25:1; [xx, yy] = ndgrid(x,y);
z = exp(-(xx.^2+yy.^2));
sp = spapi({3,4},{x,y},z); fnplt(sp)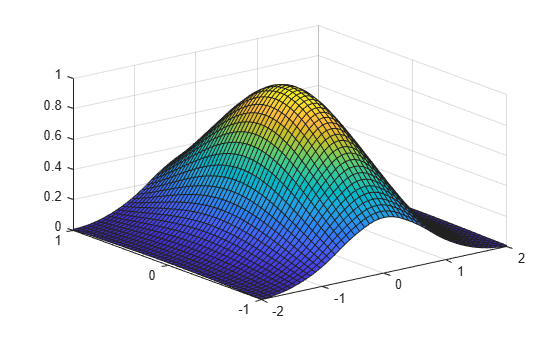
As an illustration of osculatory interpolation to gridded data, here is complete bicubic interpolation, with the data explicitly derived from the bicubic polynomial . This is helpful to see exactly where the slopes, and slopes of slopes (the cross derivatives), must be placed in the data values supplied. Since g is a bicubic polynomial, its interpolant, f, must be g itself. Test this:
sites = {[0,1],[0,2]}; coefs = zeros(4,4); coefs(1,1) = 1;
g = ppmak(sites,coefs);
Dxg = fnval(fnder(g,[1,0]),sites);
Dyg = fnval(fnder(g,[0,1]),sites);
Dxyg = fnval(fnder(g,[1,1]),sites);
f = spapi({4,4}, {sites{1}([1,2,1,2]),sites{2}([1,2,1,2])}, ...
[fnval(g,sites), Dyg ; ...
Dxg.' , Dxyg]);
if any( squeeze( fnbrk(fn2fm(f,'pp'), 'c') ) - coefs )
'something went wrong', endInput Arguments
Output Arguments
Limitations
The given (univariate) knots and sites must satisfy the Schoenberg-Whitney conditions for the interpolant to be defined. If the site sequence x is nondecreasing, then
with equality possible at knots(1) and knots(end)). In the multivariate case, these conditions must hold in each variable separately.
Algorithms
The function calls spcol to provide the almost-block-diagonal collocation matrix (Bj,k(x)) (with repeats in x denoting derivatives, as described above), and slvblk solves the linear system (*), using a block QR factorization.
The function fits gridded data, in tensor-product fashion, one variable at a time, taking advantage of the fact that a univariate spline fit depends linearly on the values that are being fitted.
Version History
Introduced in R2006b