Accelerate Audio Machine Learning Workflows Using a GPU
This example shows how to use GPU computing to accelerate machine learning workflows for audio, speech, and acoustic applications.
One of the easiest ways to speed up your code is to run it on a GPU, and many functions in MATLAB® automatically run on a GPU if you supply a gpuArray data argument. Starting from the code in the Speaker Identification Using Pitch and MFCC example, this example demonstrates how to speed up execution in a machine learning workflow by modifying it to run on a GPU. You can use a similar approach to accelerate many of your machine learning audio workflows.
As this figure shows, you can significantly speed up feature extraction, prediction, and loss calculation using a GPU.

Check GPU Support
Using a GPU requires Parallel Computing Toolbox™ and a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox).
Check whether you have a supported GPU.
gpu = gpuDevice;
disp(gpu.Name + " GPU selected.")NVIDIA RTX A5000 GPU selected.
If a function supports GPU array input, the documentation page for that function lists GPU support in the Extended Capabilities section. You can also filter lists of functions in the documentation to show only functions that support GPU array input. For more information, see Run MATLAB Functions on a GPU (Parallel Computing Toolbox).
After checking that you have a supported GPU, you follow the same steps as the previous example, with minor modifications to send data to the GPU and run functions on the GPU where possible. The code requires very little modification to run on a GPU. This diagram shows the approach used in this example, which includes feature extraction, training a classifier model, and testing the model on unknown data.

Download Data Set
This example uses a subset of the Common Voice data set from Mozilla [1]. The data set contains 48 kHz recordings of subjects speaking short sentences. The helper function in this section organizes the downloaded data and returns an audioDatastore object. The data set uses 1.36 GB of memory.
Download the data set if it doesn't already exist and unzip it into tempdir.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","commonvoice.zip"); dataFolder = tempdir; if ~datasetExists(string(dataFolder) + "commonvoice") unzip(downloadFolder,dataFolder); end
Extract the speech files for 10 speakers (5 female and 5 male) and place them into an audioDatastore using the commonVoiceHelper function, which is placed in the current folder when you open this example. The datastore lets you collect necessary files of a file format and read them.
ads = commonVoiceHelper;
Convert Data to gpuArray
To make the datastore output gpuArray (Parallel Computing Toolbox) data, set the OutputEnvironment property to "gpu". If your workflow does not use an audioDatastore, you can copy any numeric or logical data to GPU memory by calling gpuArray on your data.
ads.OutputEnvironment = "gpu";The splitEachLabel function of audioDatastore splits the datastore into two or more datastores. The resulting datastores have the specified proportion of the audio files from each label. In this example, you split the datastore into two parts, using 80% of the data for each label for training and using the remaining 20% for testing. Here, the label identifies the speaker.
[adsTrain,adsTest] = splitEachLabel(ads,0.8);
The splitEachLabel function creates datastores with the same OutputEnvironment property as the original datastore ads. Check the OutputEnvironment properties of the training and testing datastores.
adsTrain.OutputEnvironment
ans = 'gpu'
adsTest.OutputEnvironment
ans = 'gpu'
To preview the content of your datastore, read a sample file and play it using your default audio device.
[sampleTrain,dsInfo] = read(adsTrain); sound(sampleTrain,dsInfo.SampleRate)
Reading from the train datastore pushes a read pointer so that you can iterate through the database. Reset the train datastore to return the read pointer to the start for feature extraction.
reset(adsTrain)
Extract Features
Extract pitch features and mel frequency cepstrum coefficients (MFCC) features from each frame that corresponds to voiced speech in the training datastore. Audio Toolbox™ provides audioFeatureExtractor so that you can quickly and efficiently extract multiple features. Configure an audioFeatureExtractor to extract pitch, short-time energy, zero-crossing rate (ZCR), and MFCC.
fs = dsInfo.SampleRate; windowLength = round(0.03*fs); overlapLength = round(0.025*fs); afe = audioFeatureExtractor(SampleRate=fs, ... Window=hamming(windowLength,"periodic"),OverlapLength=overlapLength, ... zerocrossrate=true,shortTimeEnergy=true,pitch=true,mfcc=true);
When you call the extract function of audioFeatureExtractor, all features are concatenated and returned in a matrix. You can use the info function to determine which columns of the matrix correspond to which features.
featureMap = info(afe)
featureMap = struct with fields:
mfcc: [1 2 3 4 5 6 7 8 9 10 11 12 13]
pitch: 14
zerocrossrate: 15
shortTimeEnergy: 16
Extract features from the data set. As the training datastore outputs gpuArray data, the extract function runs on the GPU.
features = []; labels = []; energyThreshold = 0.005; zcrThreshold = 0.2; allFeatures = extract(afe,adsTrain); allLabels = adsTrain.Labels; for ii = 1:numel(allFeatures) thisFeature = allFeatures{ii}; isSpeech = thisFeature(:,featureMap.shortTimeEnergy) > energyThreshold; isVoiced = thisFeature(:,featureMap.zerocrossrate) < zcrThreshold; voicedSpeech = isSpeech & isVoiced; thisFeature(~voicedSpeech,:) = []; thisFeature(:,[featureMap.zerocrossrate,featureMap.shortTimeEnergy]) = []; label = repelem(allLabels(ii),size(thisFeature,1)); features = [features;thisFeature]; labels = [labels,label]; end
Pitch and MFCC are not on the same scale, which will bias the classifier. Normalize the features by subtracting the mean and by dividing the standard deviation.
M = mean(features,1); S = std(features,[],1); features = (features-M)./S;
Train Classifier
Now that you have features for all 10 speakers, you can train a classifier based on them. In this example, you use a K-nearest neighbor (KNN) classifier. For more information about the classifier, refer to fitcknn (Statistics and Machine Learning Toolbox).
Train the classifier and compute the cross-validation accuracy. Use the crossval (Statistics and Machine Learning Toolbox) and kfoldLoss (Statistics and Machine Learning Toolbox) functions to compute the cross-validation accuracy for the KNN classifier.
Specify all the classifier options and train the classifier. As the training data features is a gpuArray, the classifier is trained on the GPU.
trainedClassifier = fitcknn(features,labels, ... Distance="euclidean", ... NumNeighbors=5, ... DistanceWeight="squaredinverse", ... Standardize=false, ... ClassNames=unique(labels));
Perform cross-validation.
k = 5; group = labels; c = cvpartition(group,KFold=k); partitionedModel = crossval(trainedClassifier,CVPartition=c);
Compute the validation accuracy on the GPU.
validationAccuracy = 1 - kfoldLoss(partitionedModel,LossFun="ClassifError"); fprintf('\nValidation accuracy = %.2f%%n', validationAccuracy*100);
Validation accuracy = 97.10%
Visualize the confusion chart.
validationPredictions = kfoldPredict(partitionedModel); figure(Units="normalized",Position=[0.4 0.4 0.4 0.4]) confusionchart(labels,validationPredictions,title="Validation Accuracy", ... ColumnSummary="column-normalized",RowSummary="row-normalized");

You can also use the Classification Learner (Statistics and Machine Learning Toolbox) app to compare various classifiers using your table of features.
Test Classifier
In this section, you test the trained KNN classifier with speech signals from each of the 10 speakers to see how well it behaves with signals not included in the training dataset.
Read files and extract features from the test set, and normalize them. Similarly to the training datastore, the testing datastore outputs gpuArray data, so the extract function runs on the GPU.
features = []; labels = []; numVectorsPerFile = []; allFeatures = extract(afe,adsTest); allLabels = adsTest.Labels; for ii = 1:numel(allFeatures) thisFeature = allFeatures{ii}; isSpeech = thisFeature(:,featureMap.shortTimeEnergy) > energyThreshold; isVoiced = thisFeature(:,featureMap.zerocrossrate) < zcrThreshold; voicedSpeech = isSpeech & isVoiced; thisFeature(~voicedSpeech,:) = []; numVec = size(thisFeature,1); thisFeature(:,[featureMap.zerocrossrate,featureMap.shortTimeEnergy]) = []; label = repelem(allLabels(ii),numVec); numVectorsPerFile = [numVectorsPerFile,numVec]; features = [features;thisFeature]; labels = [labels,label]; end features = (features-M)./S;
Predict the label (speaker) for each frame by calling predict on trainedClassifier.
prediction = predict(trainedClassifier,features); prediction = categorical(string(prediction));
Visualize the confusion chart.
figure(Units="normalized",Position=[0.4 0.4 0.4 0.4]) confusionchart(labels(:),prediction,title="Test Accuracy (Per Frame)", ... ColumnSummary="column-normalized",RowSummary="row-normalized");

For a given file, predictions are made for every frame. Determine the mode of predictions for each file and then plot the confusion chart.
r2 = prediction(1:numel(adsTest.Files)); idx = 1; for ii = 1:numel(adsTest.Files) r2(ii) = mode(prediction(idx:idx+numVectorsPerFile(ii)-1)); idx = idx + numVectorsPerFile(ii); end figure(Units="normalized",Position=[0.4 0.4 0.4 0.4]) confusionchart(adsTest.Labels,r2,title="Test Accuracy (Per File)", ... ColumnSummary="column-normalized",RowSummary="row-normalized");
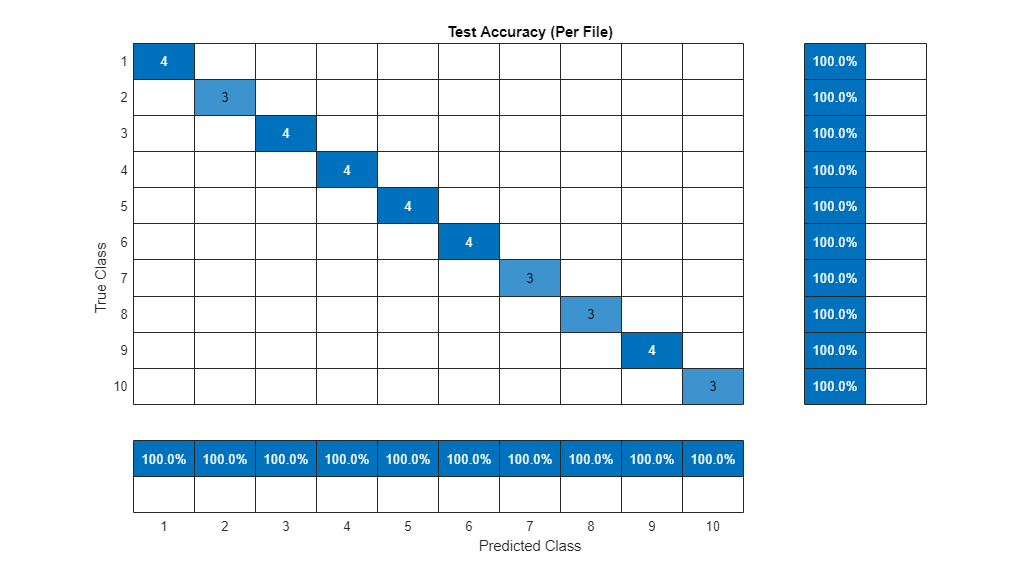
The predicted speakers match the expected speakers for all of the test files.
Note that the resulting model is the same as the model from the Speaker Identification Using Pitch and MFCC example, as you can see by comparing the confusion charts in that example and this one.
Time Execution of Long-Running Functions
The longest running steps in this example are extracting using the audioFeatureExtractor, making predictions using kfoldPredict, and calculating loss using kfoldLoss.
Time the execution of these functions on the GPU. To accurately time function execution on the GPU, use the gputimeit (Parallel Computing Toolbox) function, which runs a function multiple times to average out variation and compensate for overhead. The gputimeit function also ensures that all operations on the GPU are complete before recording the time.
reset(adsTrain) timeExtractGPU = gputimeit(@() extract(afe,adsTrain))
timeExtractGPU = 4.3300
timePredictGPU = gputimeit(@() kfoldPredict(partitionedModel))
timePredictGPU = 3.2398
timeLossGPU = gputimeit(@() 1 - kfoldLoss(partitionedModel,LossFun="ClassifError"))timeLossGPU = 3.2719
For comparison, time the same functions running on the CPU using the timeit function.
adsTrain.OutputEnvironment = "cpu";
reset(adsTrain)
timeExtractCPU = timeit(@() extract(afe,adsTrain))timeExtractCPU = 23.4533
partitionedModel = gather(partitionedModel); timePredictCPU = timeit(@() kfoldPredict(partitionedModel))
timePredictCPU = 20.1054
timeLossCPU = timeit(@() 1 - kfoldLoss(partitionedModel,LossFun="ClassifError"))timeLossCPU = 19.9273
Compare the execution times.
figure bar([timeExtractCPU timeExtractGPU; timePredictCPU timePredictGPU; timeLossCPU timeLossGPU],"grouped") xticklabels(["Feature Extraction" "Prediction" "Loss Calculation"]) ylabel("Execution Time (s)") legend(["CPU execution" "GPU execution"])
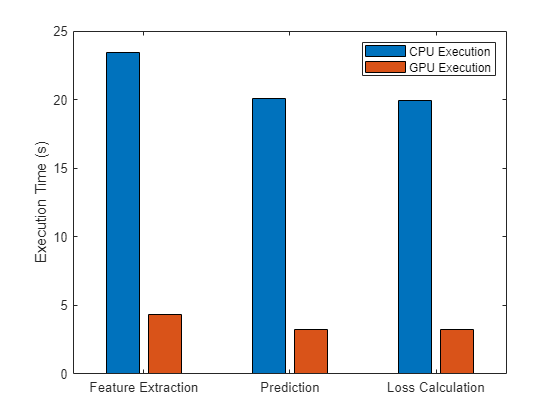
fprintf("Feature extraction speedup: %3.1fx\nPrediction speedup: %3.1fx\nLoss calculation speedup: %3.1fx", ... timeExtractCPU/timeExtractGPU,timePredictCPU/timePredictGPU,timeLossCPU/timeLossGPU);
Feature extraction speedup: 5.4x Prediction speedup: 6.2x Loss calculation speedup: 6.1x
These functions execute significantly faster on the GPU.
Running your code on a GPU is straightforward and can provide a significant speedup for many workflows. Generally, using a GPU is more beneficial when you are performing computations on larger amounts of data, though the speedup you can achieve depends on your specific hardware and code.
References
See Also
gpuArray (Parallel Computing Toolbox) | gputimeit (Parallel Computing Toolbox) | audioDatastore | audioFeatureExtractor | pitch | mfcc