quantilePredict
Predict response quantile using bag of regression trees
Syntax
Description
YFit = quantilePredict(Mdl,X)X, a table or matrix of predictor data, and using the bag of regression trees Mdl. Mdl must be a TreeBagger model object.
YFit = quantilePredict(Mdl,X,Name,Value)Name,Value pair arguments. For example, specify quantile probabilities or which trees to include for quantile estimation.
[ also returns a sparse matrix of response weights.YFit,YW]
= quantilePredict(___)
Input Arguments
Name-Value Arguments
Output Arguments
Examples
Load the carsmall data set. Consider a model that predicts the fuel economy of a car given its engine displacement.
load carsmallTrain an ensemble of bagged regression trees using the entire data set. Specify 100 weak learners.
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression');
Mdl is a TreeBagger ensemble.
Perform quantile regression to predict the median MPG for all sorted training observations.
medianMPG = quantilePredict(Mdl,sort(Displacement));
medianMPG is an n-by-1 numeric vector of medians corresponding to the conditional distribution of the response given the sorted observations in Displacement. n is the number of observations in Displacement.
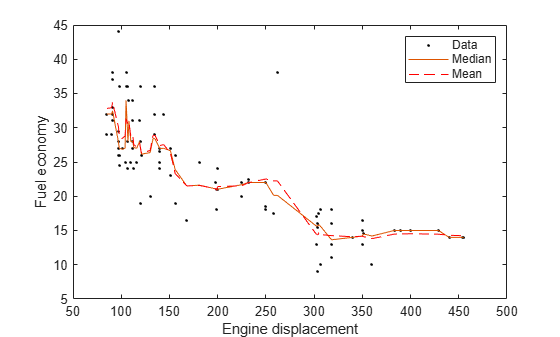
Plot the observations and the estimated medians on the same figure. Compare the median and mean responses.
meanMPG = predict(Mdl,sort(Displacement)); figure; plot(Displacement,MPG,'k.'); hold on plot(sort(Displacement),medianMPG); plot(sort(Displacement),meanMPG,'r--'); ylabel('Fuel economy'); xlabel('Engine displacement'); legend('Data','Median','Mean'); hold off;
Load the carsmall data set. Consider a model that predicts the fuel economy of a car given its engine displacement.
load carsmallTrain an ensemble of bagged regression trees using the entire data set. Specify 100 weak learners.
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression');
Perform quantile regression to predict the 2.5% and 97.5% percentiles for ten equally-spaced engine displacements between the minimum and maximum in-sample displacement.
predX = linspace(min(Displacement),max(Displacement),10)';
quantPredInts = quantilePredict(Mdl,predX,'Quantile',[0.025,0.975]);quantPredInts is a 10-by-2 numeric matrix of prediction intervals corresponding to the observations in predX. The first column contains the 2.5% percentiles and the second column contains the 97.5% percentiles.
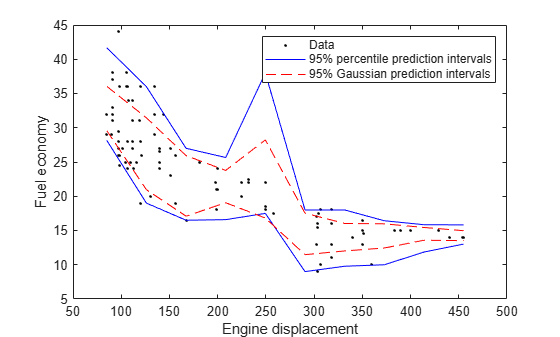
Plot the observations and the estimated medians on the same figure. Compare the percentile prediction intervals and the 95% prediction intervals assuming the conditional distribution of MPG is Gaussian.
[meanMPG,steMeanMPG] = predict(Mdl,predX); stndPredInts = meanMPG + [-1 1]*norminv(0.975).*steMeanMPG; figure; h1 = plot(Displacement,MPG,'k.'); hold on h2 = plot(predX,quantPredInts,'b'); h3 = plot(predX,stndPredInts,'r--'); ylabel('Fuel economy'); xlabel('Engine displacement'); legend([h1,h2(1),h3(1)],{'Data','95% percentile prediction intervals',... '95% Gaussian prediction intervals'}); hold off;
Load the carsmall data set. Consider a model that predicts the fuel economy of a car given its engine displacement.
load carsmallTrain an ensemble of bagged regression trees using the entire data set. Specify 100 weak learners.
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression');
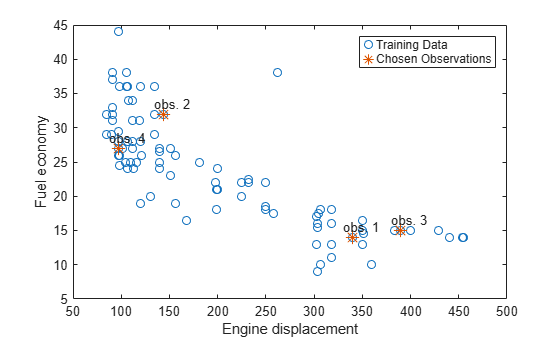
Estimate the response weights for a random sample of four training observations. Plot the training sample and identify the chosen observations.
[predX,idx] = datasample(Mdl.X,4); [~,YW] = quantilePredict(Mdl,predX); n = numel(Mdl.Y); figure; plot(Mdl.X,Mdl.Y,'o'); hold on plot(predX,Mdl.Y(idx),'*','MarkerSize',10); text(predX-10,Mdl.Y(idx)+1.5,{'obs. 1' 'obs. 2' 'obs. 3' 'obs. 4'}); legend('Training Data','Chosen Observations'); xlabel('Engine displacement') ylabel('Fuel economy') hold off
YW is an n-by-4 sparse matrix containing the response weights. Columns correspond to test observations and rows correspond to responses in the training sample. Response weights are independent of the specified quantile probability.
Estimate the conditional cumulative distribution function (C.C.D.F.) of the responses by:
Sorting the responses is ascending order, and then sorting the response weights using the indices induced by sorting the responses.
Computing the cumulative sums over each column of the sorted response weights.
[sortY,sortIdx] = sort(Mdl.Y); cpdf = full(YW(sortIdx,:)); ccdf = cumsum(cpdf);
ccdf(:,j) is the empirical C.C.D.F. of the response given test observation j.
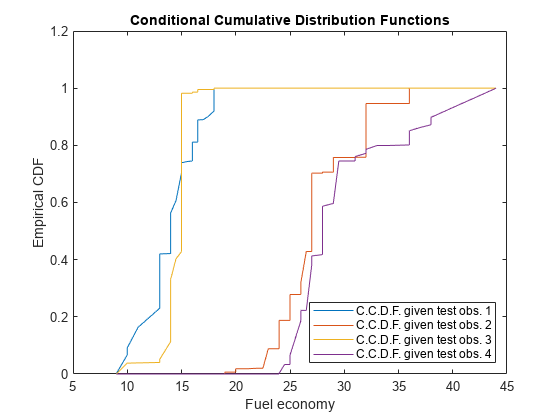
Plot the four empirical C.C.D.F. in the same figure.
figure; plot(sortY,ccdf); legend('C.C.D.F. given test obs. 1','C.C.D.F. given test obs. 2',... 'C.C.D.F. given test obs. 3','C.C.D.F. given test obs. 4',... 'Location','SouthEast') title('Conditional Cumulative Distribution Functions') xlabel('Fuel economy') ylabel('Empirical CDF')
More About
Tips
quantilePredict estimates the conditional distribution of the response using the training data every time you call it. To predict many quantiles efficiently, or quantiles for many observations efficiently, you should pass X as a matrix or table of observations and specify all quantiles in a vector using the Quantile name-value pair argument. That is, avoid calling quantilePredict within a loop.
Algorithms
The
TreeBaggergrows a random forest of regression trees using the training data. Then, to implement quantile random forest,quantilePredictpredicts quantiles using the empirical conditional distribution of the response given an observation from the predictor variables. To obtain the empirical conditional distribution of the response:quantilePredictpasses all the training observations inMdl.Xthrough all the trees in the ensemble, and stores the leaf nodes of which the training observations are members.quantilePredictsimilarly passes each observation inXthrough all the trees in the ensemble.For each observation in
X,quantilePredict:Estimates the conditional distribution of the response by computing response weights for each tree.
For observation k in
X, aggregates the conditional distributions for the entire ensemble:n is the number of training observations (
size(Y,1)) and T is the number of trees in the ensemble (Mdl.NumTrees).
For observation k in
X, the τ quantile or, equivalently, the 100τ% percentile, is
This process describes how
quantilePredictuses all specified weights.For all training observations j = 1,...,n and all chosen trees t = 1,...,T,
quantilePredictattributes the product vtj = btjwj,obs to training observation j (stored inMdl.X(andj,:)Mdl.Y(). btj is the number of times observation j is in the bootstrap sample for tree t. wj,obs is the observation weight inj)Mdl.W(.j)For each chosen tree,
quantilePredictidentifies the leaves in which each training observation falls. Let St(xj) be the set of all observations contained in the leaf of tree t of which observation j is a member.For each chosen tree,
quantilePredictnormalizes all weights within a particular leaf to sum to 1, that is,For each training observation and tree,
quantilePredictincorporates tree weights (wt,tree) specified byTreeWeights, that is, w*tj,tree = wt,treevtj*Trees not chosen for prediction have 0 weight.For all test observations k = 1,...,K in
Xand all chosen trees t = 1,...,TquantilePredictpredicts the unique leaves in which the observations fall, and then identifies all training observations within the predicted leaves.quantilePredictattributes the weight utj such thatquantilePredictsums the weights over all chosen trees, that is,quantilePredictcreates response weights by normalizing the weights so that they sum to 1, that is,
References
[1] Breiman, L. "Random Forests." Machine Learning 45, pp. 5–32, 2001.
[2] Meinshausen, N. “Quantile Regression Forests.” Journal of Machine Learning Research, Vol. 7, 2006, pp. 983–999.
Version History
Introduced in R2016b