Shapley Values for Machine Learning Model
This topic defines Shapley values, describes two available algorithms in the Statistics and Machine Learning Toolbox™ feature that computes Shapley values, provides examples for each, and shows how to reduce the computational cost.
What Is a Shapley Value?
In game theory, the Shapley value of a player is the average marginal contribution of the player in a cooperative game. That is, Shapley values are fair allocations, to individual players, of the total gain generated from a cooperative game. In the context of machine learning prediction, the Shapley value of a feature for a query point explains the contribution of the feature to a prediction (the response for regression or the score of each class for classification) at the specified query point. The Shapley value corresponds to the deviation of the prediction for the query point from the average prediction, due to the feature. For each query point, the sum of the Shapley values for all features corresponds to the total deviation of the prediction from the average.
The Shapley value of the ith feature for the query point x is defined by the value function v:
| (1) |
M is the number of all features.
is the set of all features.
|S| is the cardinality of the set S, or the number of elements in the set S.
vx(S) is the value function of the features in a set S for the query point x. The value of the function indicates the expected contribution of the features in S to the prediction for the query point x.
Shapley Value in Statistics and Machine Learning Toolbox
You can compute Shapley values for a machine learning model by using a shapley object. Use
the values to interpret the contributions of individual features in the model to the
prediction for a query point. You can compute Shapley values in two ways:
Create a
shapleyobject for a machine learning model with a specified query point by using theshapleyfunction. The function computes the Shapley values of all features in the model for the query point.Create a
shapleyobject for a machine learning model by using theshapleyfunction, and then compute the Shapley values for a specified query point by using thefitfunction.
Note that you can compute Shapley values for multiple query points. (since R2024a)
Algorithms
shapley offers two
types of algorithms: interventional, which uses interventional distributions for the value
function, and conditional, which uses conditional distributions for the value function. You
can specify the algorithm type to use by setting the Method name-value
argument of the shapley function or
the fit
function.
The difference between the two types of algorithms is the definition of the value function. Both types define the value function so that the sum of the Shapley values of a query point over all features corresponds to the total deviation of the prediction for the query point from the average.
Therefore, the value function vx(S) must correspond to the expected contribution of the features in
S to the prediction (f) for the query point
x. The algorithms compute the expected contribution by using artificial
samples created from the specified data (X). You must provide
X
through the machine learning model input or a separate data input argument when you create a
shapley object. In the artificial samples, the values for the features in
S come from the query point. For the rest of the features (features in
Sc, the complement of
S), an interventional algorithm generates samples using interventional
distributions, whereas a conditional algorithm generates samples using conditional
distributions.
By default, the shapley
function selects a subset of the observations in X to compute Shapley
values. The function creates artificial samples from this subset. For more information, see
NumObservationsToSample. (since R2024b)
Interventional Algorithms
By default, shapley uses one of these interventional algorithms:
Kernel SHAP [1], Linear SHAP [1], or Tree SHAP [2].
Computing exact Shapley values can be computationally expensive if
shapley uses all possible subsets S. Therefore,
shapley estimates the Shapley values by limiting the maximum number of
subsets to use for the Kernel SHAP algorithm. For more details, see Computational Cost.
For linear models and tree-based models, shapley offers the Linear
SHAP and Tree SHAP algorithms, respectively. These algorithms are computationally less
expensive and compute exact Shapley values. The algorithms return the same Shapley values
that the Kernel SHAP algorithm returns when using all possible subsets. The Linear SHAP,
Tree SHAP, and Kernel SHAP algorithms differ in these ways:
The Linear SHAP and Tree SHAP algorithms ignore the
ResponseTransformproperty (for regression) and theScoreTransformproperty (for classification) of the machine learning model. That is, the algorithms compute Shapley values based on raw responses or raw scores without applying response transformation or score transformation, respectively. The Kernel SHAP algorithm uses transformed values if the model specifies transformation in theResponseTransformorScoreTransformproperty.The Kernel SHAP and Tree SHAP algorithms can use observations with missing values. The Linear SHAP algorithm cannot handle observations with missing values for any model.
shapley selects an algorithm based on the machine learning model type
and other specified options:
Linear SHAP algorithm for these linear models:
RegressionSVM,CompactRegressionSVM,ClassificationSVM, andCompactClassificationSVMmodels that use a linear kernel function
Tree SHAP algorithm for these tree models and ensemble models with tree learners:
Tree models —
RegressionTree,CompactRegressionTree,ClassificationTree, andCompactClassificationTreeEnsemble models with tree learners —
RegressionEnsemble,RegressionBaggedEnsemble,CompactRegressionEnsemble,ClassificationEnsemble,CompactClassificationEnsemble, andClassificationBaggedEnsemblemodels that use tree learnersTo use the Tree SHAP algorithm, you must specify the
Methodname-value argument (ensemble aggregation method) as'Bag','AdaBoostM2','GentleBoost','LogitBoost', or'RUSBoost'when you train a classification ensemble model.
Kernel SHAP algorithm for all other model types and for these cases:
For the tree models and ensembles of trees previously listed, the software might use Kernel SHAP instead of Tree SHAP if the models use surrogate splits (
Surrogate) for prediction, and observations in the input predictor data or values in the query point contain missing values.Before R2023b: For tree models and ensemble models with tree learners, the software always used Kernel SHAP instead of Tree SHAP when observations in the input predictor data or values in the query point contained missing values.
If you specify the
MaxNumSubsetsname-value argument (maximum number of predictor subsets to use for Shapley value computation) ofshapleyorfit, the software uses Kernel SHAP.In some cases, Kernel SHAP can be computationally less expensive than Tree SHAP. For example, Kernel SHAP can be more efficient if a model contains a deep tree for low-dimensional data. The software heuristically selects an efficient algorithm.
An interventional algorithm defines the value function of the features in S at the query point x as the expected prediction with respect to the interventional distribution D, which is the joint distribution of the features in Sc:
xS is the query point value for the features in S, and XSc are the features in Sc.
To evaluate the value function vx(S) at the query point x, with the assumption that the
features are not highly correlated, shapley uses the values in the data
X as samples of the interventional distribution D
for the features in Sc:
N is the number of observations, and (XSc)j contains the values of the features in Sc for the jth observation.
For example, suppose you have three features in X and four observations: (x11,x12,x13), (x21,x22,x23), (x31,x32,x33), and (x41,x42,x43). Assume that S includes the first feature, and Sc includes the rest. In this case, the value function of the first feature evaluated at the query point (x41,x42,x43) is
An interventional algorithm is computationally less expensive than a conditional algorithm and supports ordered categorical predictors. However, an interventional algorithm requires the feature independence assumption and uses out-of-distribution samples [4]. The artificial samples created with a mix of the query point and the data X can contain unrealistic observations. For example, (x41,x12,x13) might be a sample that does not occur in the full joint distribution of the three features.
Conditional Algorithm
Specify the Method name-value argument as
"conditional" to use the extension to the Kernel SHAP algorithm [3], which is a conditional algorithm.
A conditional algorithm defines the value function of the features in S at the query point x using the conditional distribution of XSc, given that XS has the query point values:
To evaluate the value function vx(S) at the query point x, shapley uses
nearest neighbors of the query point, which correspond to 10% of the observations in the
data X. This approach uses more realistic samples than an
interventional algorithm and does not require the feature independence assumption.
However, a conditional algorithm is computationally more expensive, does not support
ordered categorical predictors, and cannot handle NaNs in continuous
features. Also, the algorithm might assign a nonzero Shapley value to a dummy feature,
which does not contribute to the prediction, if the dummy feature is correlated with an
important feature [4].
Specify Computation Algorithm
This example trains a linear classification model and computes Shapley values using an interventional algorithm (Method="interventional") and then a conditional algorithm (Method="conditional").
Train Linear Classification Model
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphereTrain a linear classification model. For better accuracy of linear coefficients, specify the objective function minimization technique (Solver name-value argument) as the limited-memory Broyden-Fletcher-Goldfarb-Shanno quasi-Newton algorithm ("lbfgs").
Mdl = fitclinear(X,Y,Solver="lbfgs")Mdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
Beta: [34×1 double]
Bias: -3.7100
Lambda: 0.0028
Learner: 'svm'
Properties, Methods
Compute Shapley Values Using Interventional Algorithm
Compute the Shapley values for the first observation using the Linear SHAP algorithm, which is an interventional algorithm. You do not have to specify the Method name-value argument because "interventional" is the default.
queryPoint = X(1,:); explainer1 = shapley(Mdl,X,QueryPoints=queryPoint);
For a classification model, shapley computes Shapley values using the predicted class score for each class. Plot the Shapley values for the predicted class by using the plot function.
plot(explainer1)
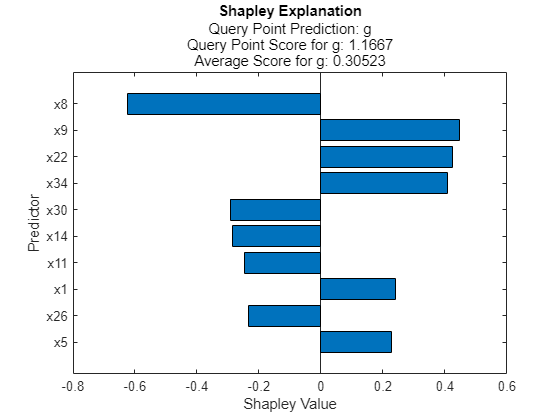
The horizontal bar graph shows the Shapley values for the 10 most important variables, sorted by their absolute values. Each value explains the deviation of the score for the query point from the average score of the predicted class, due to the corresponding variable.
For a linear model, shapley assumes features are independent from one another and computes the Shapley values from the estimated coefficients (Mdl.Beta) [1]. Compute the Shapley values for the positive class (the second class in Mdl.ClassNames, 'g') directly from the estimated coefficients.
linearSHAPValues = (Mdl.Beta'.*(queryPoint-mean(X)))';
Create a table containing the Shapley values computed from shapley and the values from the coefficients.
t = table(explainer1.Shapley.Predictor, ... explainer1.Shapley.g,linearSHAPValues, ... VariableNames=["Predictor","Values from shapley", ... "Values from Coefficients"])
t=34×3 table
Predictor Values from shapley Values from Coefficients
_________ ___________________ ________________________
"x1" 0.23933 0.28789
"x2" 0 0
"x3" 0.19003 0.20822
"x4" -0.018184 -0.01998
"x5" 0.22598 0.20872
"x6" -0.090779 -0.076991
"x7" 0.19581 0.19188
"x8" -0.62335 -0.64386
"x9" 0.44525 0.42348
"x10" -0.034559 -0.030049
"x11" -0.24766 -0.23132
"x12" 0.14257 0.1422
"x13" -0.054611 -0.045973
"x14" -0.28432 -0.29022
"x15" 0.21024 0.21051
"x16" 0.13884 0.13382
⋮
Compute Shapley Values Using Conditional Algorithm
Compute the Shapley values for the first observation using the extension to the Kernel SHAP algorithm, which is a conditional algorithm.
explainer2 = shapley(Mdl,X,QueryPoints=queryPoint, ... Method="conditional");
Plot the Shapley values.
plot(explainer2)
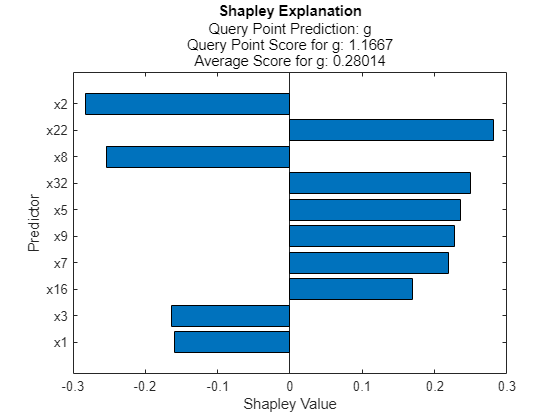
The two algorithms identify different sets for the 10 most important variables. Some variables, such as x8 and x22, are included in both sets.
Computational Cost
The cost of computing the Shapley values for a query point increases if the number of observations or features is large.
Large Number of Observations
Computing the value function (v) can be computationally expensive
if you have a large number of observations, for example, more than 1000. For faster
computation, use a smaller sample of the observations when you create a shapley object,
or run in parallel by specifying UseParallel as
true when you compute the values using the shapley or
fit function.
The UseParallel option is available when the function computes
Shapley values for one query point by using the Tree SHAP algorithm for an ensemble of
trees, the Kernel SHAP algorithm, or the extension to the Kernel SHAP algorithm. (The
UseParallel option is also available when the function computes
Shapley values for multiple query points.) Computing in parallel requires Parallel Computing Toolbox™.
Large Number of Features
Computing the summand in Equation 1 for all possible subsets
S can be computationally expensive when M (the
number of features) is large for the Kernel SHAP algorithm or the extension to the Kernel
SHAP algorithm. The total number of subsets to consider is 2M. Instead of computing the summand for all subsets, you can specify the
maximum number of subsets by using the MaxNumSubsets
name-value argument. shapley chooses subsets to use based on their weight
values. The weight of a subset is proportional to 1/(denominator of the summand), which
corresponds to 1 over the binomial coefficient: . Therefore, a subset with a high or low value of cardinality has a large
weight value. shapley includes the subsets with the highest weight first,
and then includes the other subsets in descending order based on their weight
values.
Reduce Computational Cost
This example shows how to reduce the computational cost of Shapley values when you have a large number of both observations and features.
Load the sample data set NYCHousing2015.
load NYCHousing2015The data set includes 91,446 observations of 10 variables with information on the sales of properties in New York City in 2015. This example uses these variables to analyze the sale prices (SALEPRICE).
Preprocess the data set. Convert the datetime array (SALEDATE) to the month numbers.
NYCHousing2015.SALEDATE = month(NYCHousing2015.SALEDATE);
Train a neural network regression model.
Mdl = fitrnet(NYCHousing2015,"SALEPRICE",Standardize=true);Compute the Shapley values of all predictor variables for the first observation. Include all the predictor data in the computation of the Shapley values. Measure the time required for the computation by using tic and toc.
tic explainer1 = shapley(Mdl,QueryPoints=NYCHousing2015(1,:), ... NumObservationsToSample="all");
Warning: Computation can be slow because the predictor data has over 1000 observations. Use a smaller sample of the training set or specify 'UseParallel' as true for faster computation.
toc
Elapsed time is 194.917123 seconds.
As the warning message indicates, the computation can be slow because the predictor data has over 1000 observations.
shapley provides several options to reduce the computational cost when you have a large number of observations or features:
Large number of observations — Use a smaller sample of the training data by specifying the
NumObservationsToSamplename-value argument, and run in parallel by specifyingUseParallelastrue.Large number of features — Specify the
MaxNumSubsetsname-value argument to limit the number of subsets included in the computation.
Start a parallel pool.
parpool;
Starting parallel pool (parpool) using the 'Processes' profile ... 21-Aug-2024 10:56:54: Job Queued. Waiting for parallel pool job with ID 2 to start ... Connected to parallel pool with 6 workers.
Compute the Shapley values again using a smaller sample of the training data and the parallel computing option. Also, specify the maximum number of subsets as 2^5.
NumSamples = 5e2; tic explainer2 = shapley(Mdl,QueryPoints=NYCHousing2015(1,:), ... NumObservationsToSample=500,UseParallel=true, ... MaxNumSubsets=2^5); toc
Elapsed time is 1.336726 seconds.
Specifying the additional options reduces the computation time.
References
[4] Kumar, I. Elizabeth, Suresh Venkatasubramanian, Carlos Scheidegger, and Sorelle Friedler. "Problems with Shapley-Value-Based Explanations as Feature Importance Measures." Proceedings of the 37th International Conference on Machine Learning 119 (July 2020): 5491–500.