fft2
2-D fast Fourier transform
Description
Y = fft2( returns the two-dimensional Fourier transform of a matrix X)X using
a fast Fourier transform algorithm, which is equivalent to computing
fft(fft(X).').'.
When X is a multidimensional array, fft2
computes the 2-D Fourier transform on the first two dimensions of each subarray of
X that can be treated as a 2-D matrix for dimensions higher
than 2. For example, if X is an
m-by-n-by-1-by-2
array, then Y(:,:,1,1) = fft2(X(:,:,1,1)) and Y(:,:,1,2)
= fft2(X(:,:,1,2)). The output Y is the same size
as X.
Examples
The 2-D Fourier transform is useful for processing 2-D signals and other 2-D data such as images.
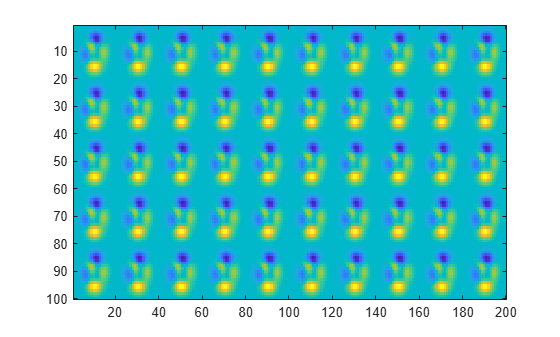
Create and plot 2-D data with repeated blocks.
P = peaks(20); X = repmat(P,[5 10]); imagesc(X)
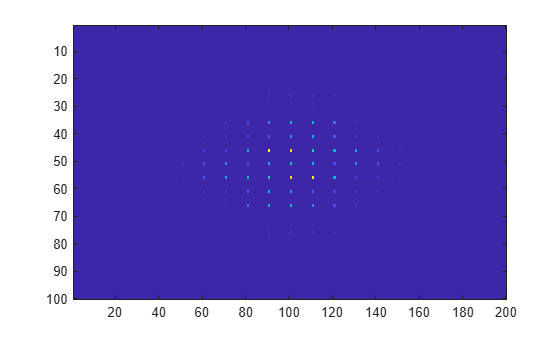
Compute the 2-D Fourier transform of the data. Shift the zero-frequency component to the center of the output, and plot the resulting 100-by-200 matrix, which is the same size as X.
Y = fft2(X); imagesc(abs(fftshift(Y)))
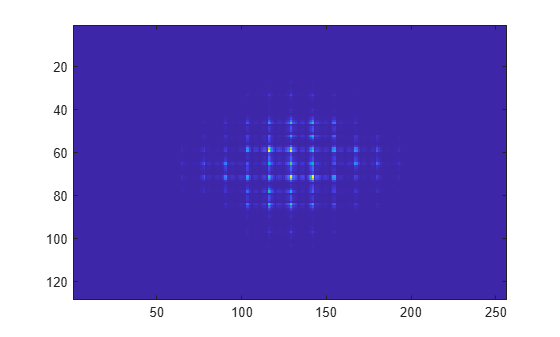
Pad X with zeros to compute a 128-by-256 transform.
Y = fft2(X,2^nextpow2(100),2^nextpow2(200)); imagesc(abs(fftshift(Y)));
Input Arguments
More About
Extended Capabilities
Version History
Introduced before R2006a