bicg
Solve system of linear equations — biconjugate gradients method
Syntax
Description
x = bicg(A,b)A*x = b for
x using the Biconjugate Gradients Method. When the attempt is
successful, bicg displays a message to confirm convergence. If
bicg fails to converge after the maximum number of iterations or
halts for any reason, it displays a diagnostic message that includes the relative residual
norm(b-A*x)/norm(b) and the iteration number at which the method
stopped.
[
returns a flag that specifies whether the algorithm successfully converged. When
x,flag] = bicg(___)flag = 0, convergence was successful. You can use this output syntax
with any of the previous input argument combinations. When you specify the
flag output, bicg does not display any diagnostic
messages.
Examples
Solve a square linear system using bicg with default settings, and then adjust the tolerance and number of iterations used in the solution process.
Create a random sparse matrix A with 50% density. Also create a random vector b for the right-hand side of .
rng default
A = sprand(400,400,.5);
A = A'*A;
b = rand(400,1);Solve using bicg. The output display includes the value of the relative residual error .
x = bicg(A,b);
bicg stopped at iteration 20 without converging to the desired tolerance 1e-06 because the maximum number of iterations was reached. The iterate returned (number 7) has relative residual 0.45.
By default bicg uses 20 iterations and a tolerance of 1e-6, and the algorithm is unable to converge in those 20 iterations for this matrix. Since the residual is still large, it is a good indicator that more iterations (or a preconditioner matrix) are needed. You also can use a larger tolerance to make it easier for the algorithm to converge.
Solve the system again using a tolerance of 1e-4 and 100 iterations.
x = bicg(A,b,1e-4,100);
bicg stopped at iteration 100 without converging to the desired tolerance 0.0001 because the maximum number of iterations was reached. The iterate returned (number 7) has relative residual 0.45.
Even with a looser tolerance and more iterations, the residual error does not improve much. When an iterative algorithm stalls in this manner, it is a good indication that a preconditioner matrix is needed.
Calculate the incomplete Cholesky factorization of A, and use the L' factor as a preconditioner input to bicg.
L = ichol(A); x = bicg(A,b,1e-4,100,L');
bicg converged at iteration 55 to a solution with relative residual 9.9e-05.
Using a preconditioner improves the numerical properties of the problem enough that bicg is able to converge.
Examine the effect of using a preconditioner matrix with bicg to solve a linear system.
Load west0479, a real 479-by-479 nonsymmetric sparse matrix.
load west0479
A = west0479;Define b so that the true solution to is a vector of all ones.
b = sum(A,2);
Set the tolerance and maximum number of iterations.
tol = 1e-12; maxit = 20;
Use bicg to find a solution at the requested tolerance and number of iterations. Specify five outputs to return information about the solution process:
xis the computed solution toA*x = b.fl0is a flag indicating whether the algorithm converged.rr0is the relative residual of the computed answerx.it0is the iteration number whenxwas computed.rv0is a vector of the residual history for .
[x,fl0,rr0,it0,rv0] = bicg(A,b,tol,maxit); fl0
fl0 = 1
rr0
rr0 = 1
it0
it0 = 0
fl0 is 1 because bicg does not converge to the requested tolerance 1e-12 within the requested 20 iterations. In fact, the behavior of bicg is so poor that the initial guess x0 = zeros(size(A,2),1) is the best solution and is returned, as indicated by it0 = 0.
To aid with the slow convergence, you can specify a preconditioner matrix. Since A is nonsymmetric, use ilu to generate the preconditioner . Specify a drop tolerance to ignore nondiagonal entries with values smaller than 1e-6. Solve the preconditioned system by specifying L and U as inputs to bicg.
setup = struct('type','ilutp','droptol',1e-6); [L,U] = ilu(A,setup); [x1,fl1,rr1,it1,rv1] = bicg(A,b,tol,maxit,L,U); fl1
fl1 = 0
rr1
rr1 = 4.1409e-14
it1
it1 = 6
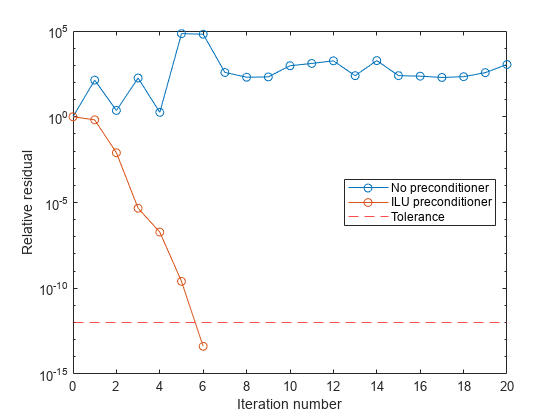
The use of an ilu preconditioner produces a relative residual less than the prescribed tolerance of 1e-12 at the sixth iteration. The output rv1(1) is norm(b), and the output rv1(end) is norm(b-A*x1).
You can follow the progress of bicg by plotting the relative residuals at each iteration. Plot the residual history of each solution with a line for the specified tolerance.
semilogy(0:length(rv0)-1,rv0/norm(b),'-o') hold on semilogy(0:length(rv1)-1,rv1/norm(b),'-o') yline(tol,'r--'); legend('No preconditioner','ILU preconditioner','Tolerance','Location','East') xlabel('Iteration number') ylabel('Relative residual')
Examine the effect of supplying bicg with an initial guess of the solution.
Create a tridiagonal sparse matrix. Use the sum of each row as the vector for the right-hand side of so that the expected solution for is a vector of ones.
n = 900; e = ones(n,1); A = spdiags([e 2*e e],-1:1,n,n); b = sum(A,2);
Use bicg to solve twice: one time with the default initial guess, and one time with a good initial guess of the solution. Use 200 iterations and the default tolerance for both solutions. Specify the initial guess in the second solution as a vector with all elements equal to 0.99.
maxit = 200; x1 = bicg(A,b,[],maxit);
bicg converged at iteration 35 to a solution with relative residual 9.5e-07.
x0 = 0.99*e; x2 = bicg(A,b,[],maxit,[],[],x0);
bicg converged at iteration 7 to a solution with relative residual 8.7e-07.
In this case supplying an initial guess enables bicg to converge more quickly.
Returning Intermediate Results
You also can use the initial guess to get intermediate results by calling bicg in a for-loop. Each call to the solver performs a few iterations and stores the calculated solution. Then you use that solution as the initial vector for the next batch of iterations.
For example, this code performs 100 iterations four times and stores the solution vector after each pass in the for-loop:
x0 = zeros(size(A,2),1); tol = 1e-8; maxit = 100; for k = 1:4 [x,flag,relres] = bicg(A,b,tol,maxit,[],[],x0); X(:,k) = x; R(k) = relres; x0 = x; end
X(:,k) is the solution vector computed at iteration k of the for-loop, and R(k) is the relative residual of that solution.
Solve a linear system by providing bicg with a function handle that computes A*x and A'*x in place of the coefficient matrix A.
Create an nonsymmetric tridiagonal matrix. Preview the matrix.
A = gallery('wilk',21) + diag(ones(20,1),1)A = 21×21
10 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 9 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 8 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 1 7 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 1 6 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 5 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 1 4 2 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 1 3 2 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 2 2 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 1 1 2 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 0 2 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 1 2 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1 2 2 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 3 2 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 4 2 0 0 0 0 0
⋮
Since this tridiagonal matrix has a special structure, you can represent the operation A*x with a function handle. When A multiplies a vector, most of the elements in the resulting vector are zeros. The nonzero elements in the result correspond with the nonzero tridiagonal elements of A.
The expression becomes:
.
The resulting vector can be written as the sum of three vectors:
=.
Likewise, the expression for becomes:
.
.
In MATLAB®, write a function that creates these vectors and adds them together, giving the value of A*x or A'*x, depending on the flag input:
function y = afun(x,flag) if strcmp(flag,'notransp') % Compute A*x y = [0; x(1:20)] ... + [(10:-1:0)'; (1:10)'].*x ... + 2*[x(2:end); 0]; elseif strcmp(flag,'transp') % Compute A'*x y = 2*[0; x(1:20)] ... + [(10:-1:0)'; (1:10)'].*x ... + [x(2:end); 0]; end end
(This function is saved as a local function at the end of the example.)
Now, solve the linear system by providing bicg with the function handle that calculates A*x and A'*x. Use a tolerance of 1e-6 and 25 iterations. Specify as the row sums of so that the true solution for is a vector of ones.
b = full(sum(A,2)); tol = 1e-6; maxit = 25; x1 = bicg(@afun,b,tol,maxit)
bicg converged at iteration 19 to a solution with relative residual 4.8e-07.
x1 = 21×1
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
⋮
Local Functions
function y = afun(x,flag) if strcmp(flag,'notransp') % Compute A*x y = [0; x(1:20)] ... + [(10:-1:0)'; (1:10)'].*x ... + 2*[x(2:end); 0]; elseif strcmp(flag,'transp') % Compute A'*x y = 2*[0; x(1:20)] ... + [(10:-1:0)'; (1:10)'].*x ... + [x(2:end); 0]; end end
Input Arguments
Output Arguments
More About
Tips
Convergence of most iterative methods depends on the condition number of the coefficient matrix,
cond(A). WhenAis square, you can useequilibrateto improve its condition number, and on its own this makes it easier for most iterative solvers to converge. However, usingequilibratealso leads to better quality preconditioner matrices when you subsequently factor the equilibrated matrixB = R*P*A*C.You can use matrix reordering functions such as
dissectandsymrcmto permute the rows and columns of the coefficient matrix and minimize the number of nonzeros when the coefficient matrix is factored to generate a preconditioner. This can reduce the memory and time required to subsequently solve the preconditioned linear system.
References
[1] Barrett, R., M. Berry, T.F. Chan, et al., Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods, SIAM, Philadelphia, 1994.