TrainingOptionsRMSProp
Training options for RMSProp optimizer
Description
Use a TrainingOptionsRMSProp object to set training options
for the RMSProp (root mean square propagation) optimizer, including learning rate
information, L2 regularization factor, and mini-batch
size.
Creation
Create a TrainingOptionsRMSProp object using trainingOptions and specifying "rmsprop" as the first
input argument.
Properties
RMSProp
Maximum number of epochs (full passes of the data) to use for training, specified as a positive integer.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Size of the mini-batch to use for each training iteration, specified as a positive integer. A mini-batch is a subset of the training set that is used to evaluate the gradient of the loss function and update the weights.
If the mini-batch size does not evenly divide the number of training samples, then the software discards the training data that does not fit into the final complete mini-batch of each epoch. If the mini-batch size is smaller than the number of training samples, then the software does not discard any data.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Option for data shuffling, specified as one of these values:
"once"— Shuffle the training and validation data once before training."never"— Do not shuffle the data."every-epoch"— Shuffle the training data before each training epoch, and shuffle the validation data before each neural network validation. If the mini-batch size does not evenly divide the number of training samples, then the software discards the training data that does not fit into the final complete mini-batch of each epoch. To avoid discarding the same data every epoch, set theShuffletraining option to"every-epoch".
Initial learning rate used for training, specified as a positive scalar.
If the learning rate is too low, then training can take a long time. If the learning rate is too high, then training might reach a suboptimal result or diverge.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Learning rate schedule, specified as a character vector or string scalar of a built-in learning rate schedule name, a string array of names, a built-in or custom learning rate schedule object, a function handle, or a cell array of names, metric objects, and function handles.
Built-In Learning Rate Schedule Names
Specify learning rate schedules as a string scalar, character vector, or a string or cell array of one or more of these names:
| Name | Description | Plot |
|---|---|---|
"none" | No learning rate schedule. This schedule keeps the learning rate constant. |
|
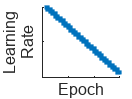
"piecewise" | Piecewise learning rate schedule. Every 10 epochs, this schedule drops the learn rate by a factor of 10. |
|
"warmup" (since R2024b) | Warm-up learning rate schedule. For 5 iterations, this schedule ramps up the learning rate to the base learning rate. |
|
"polynomial" (since R2024b) | Polynomial learning rate schedule. Every epoch, this schedule drops the learning rate using a power law with a unitary exponent. |
|
"exponential" (since R2024b) | Exponential learning rate schedule. Every epoch, this schedule decays
the learning rate by a factor of 10. |
|
"cosine" (since R2024b) | Cosine learning rate schedule. Every epoch, this schedule drops the learn rate using a cosine formula. |
|
"cyclical" (since R2024b) | Cyclical learning rate schedule. For periods of 10 epochs, this schedule increases the learning rate from the base learning rate for 5 epochs and then decreases the learning rate for 5 epochs. |
|






Built-In Learning Rate Schedule Object (since R2024b)
If you need more flexibility than what the string options provide, you can use built-in learning rate schedule objects:
piecewiseLearnRate— A piecewise learning rate schedule object drops the learning rate periodically by multiplying it by a specified factor. Use this object to customize the drop factor and period of the piecewise schedule.Before R2024b: Customize the piecewise drop factor and period using the
LearnRateDropFactorandLearnRateDropPeriodtraining options, respectively.warmupLearnRate— A warm-up learning rate schedule object ramps up the learning for a specified number of iterations. Use this object to customize the initial and final learning rate factors and the number of steps of the warm up schedule.polynomialLearnRate— A polynomial learning rate schedule drops the learning rate using a power law. Use this object to customize the initial and final learning rate factors, the exponent, and the number of steps of the polynomial schedule.exponentialLearnRate— An exponential learning rate schedule decays the learning rate by a specified factor. Use this object to customize the drop factor and period of the exponential schedule.cosineLearnRate— A cosine learning rate schedule object drops the learning rate using a cosine curve and incorporates warm restarts. Use this object to customize the initial and final learning rate factors, the period, and the period growth factor of the cosine schedule.cyclicalLearnRate— A cyclical learning rate schedule periodically increases and decreases the learning rate. Use this option to customize the maximum factor, period, and step ratio of the cyclical schedule.
Custom Learning Rate Schedule (since R2024b)
For additional flexibility, you can define a custom learning rate schedule as a function handle or custom class that inherits from deep.LearnRateSchedule.
Custom learning rate schedule function handle — If the learning rate schedule you need is not a built-in learning rate schedule, then you can specify custom learning rate schedules using a function handle. To specify a custom schedule, use a function handle with the syntax
learningRate = f(baseLearningRate,epoch), wherebaseLearningRateis the base learning rate, andepochis the epoch number.Custom learn rate schedule object — If you need more flexibility that what function handles provide, then you can define a custom learning rate schedule class that inherits from
deep.LearnRateSchedule.
Multiple Learning Rate Schedules (since R2024b)
You can combine multiple learning rate schedules by specifying multiple schedules as a string
or cell array and then the software applies the schedules in order, starting with the first
element. At most one of the schedules can be infinite (schedules than continue indefinitely,
such as "cyclical" and objects with the NumSteps
property set to Inf) and the infinite schedule must be the last element
of the array.
Number of epochs for dropping the learning rate, specified as a positive integer. This
argument is valid only when the LearnRateSchedule value is
"piecewise".
The software multiplies the global learning rate with the drop factor every time the specified
number of epochs passes. Specify the drop factor using the
LearnRateDropFactor argument.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Factor for dropping the learning rate, specified as a scalar from 0 to
1. This argument is valid only when the
LearnRateSchedule argument is
"piecewise".
LearnRateDropFactor is a multiplicative factor to apply to the learning
rate every time a certain number of epochs passes. Specify the number of epochs using the
LearnRateDropPeriod argument.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Decay rate of squared gradient moving average for the RMSProp solver,
specified as a nonnegative scalar less than 1.
Typical values of the decay rate are 0.9, 0.99, and 0.999, corresponding to averaging lengths of 10, 100, and 1000 parameter updates, respectively.
For more information, see Root Mean Square Propagation.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Denominator offset for the RMSProp solver, specified as a positive scalar.
The solver adds the offset to the denominator in the neural network parameter updates to avoid division by zero. The default value works well for most tasks.
For more information about the different solvers, see Root Mean Square Propagation.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Data Layout
Since R2025a
Encoding of categorical inputs, specified as one of these values:
"integer"— Convert categorical inputs to their integer value. In this case, the network must have one input channel for each of the categorical inputs."one-hot"— Convert categorical inputs to one-hot encoded vectors. In this case, the network must havenumCategorieschannels for each of the categorical inputs, wherenumCategoriesis the number of categories of the corresponding categorical input.
Since R2025a
Encoding of categorical targets, specified as one of these values:
"auto"— If you train using the"index-crossentropy"loss function, then convert categorical targets to their integer value. Otherwise, convert categorical targets to one-hot encoded vectors."integer"— Convert categorical targets to their integer value and pass the integer-encoded values to the loss and metric functions."one-hot"— Convert categorical targets to one-hot encoded vectors and pass the one-hot encoded values to the loss and metric functions.
Since R2023b
Description of the input data dimensions, specified as a string array, character vector, or cell array of character vectors.
If InputDataFormats is "auto", then the software uses
the formats expected by the network input. Otherwise, the software uses the specified
formats for the corresponding network input.
A data format is a string of characters, where each character describes the type of the corresponding data dimension.
The characters are:
"S"— Spatial"C"— Channel"B"— Batch"T"— Time"U"— Unspecified
For example, consider an array that represents a batch of sequences where the first,
second, and third dimensions correspond to channels, observations, and time steps,
respectively. You can describe the data as having the format "CBT"
(channel, batch, time).
You can specify multiple dimensions labeled "S" or "U".
You can use the labels "C", "B", and
"T" once each, at most. The software ignores singleton trailing
"U" dimensions after the second dimension.
For a neural network with multiple inputs net, specify an array of
input data formats, where InputDataFormats(i) corresponds to the
input net.InputNames(i).
For more information, see Deep Learning Data Formats.
Data Types: char | string | cell
Since R2023b
Description of the target data dimensions, specified as one of these values:
"auto"— If the target data has the same number of dimensions as the input data, then thetrainnetfunction uses the format specified byInputDataFormats. If the target data has a different number of dimensions from the input data, then thetrainnetfunction uses the format expected by the loss function.String array, character vector, or cell array of character vectors — The
trainnetfunction uses the data formats you specify.
A data format is a string of characters, where each character describes the type of the corresponding data dimension.
The characters are:
"S"— Spatial"C"— Channel"B"— Batch"T"— Time"U"— Unspecified
For example, consider an array that represents a batch of sequences where the first,
second, and third dimensions correspond to channels, observations, and time steps,
respectively. You can describe the data as having the format "CBT"
(channel, batch, time).
You can specify multiple dimensions labeled "S" or "U".
You can use the labels "C", "B", and
"T" once each, at most. The software ignores singleton trailing
"U" dimensions after the second dimension.
For more information, see Deep Learning Data Formats.
Data Types: char | string | cell
Monitoring
Plots to display during neural network training, specified as one of these values:
"none"— Do not display plots during training."training-progress"— Plot training progress.
The plot shows the mini-batch loss, validation loss, training mini-batch and
validation metrics as specified by the Metrics property, and additional information about the training
progress.
To programmatically open and close the training progress plot after training, use the show and close functions with the second output of the trainnet function. You can use the show function to view the training progress even if the Plots training option is specified as "none".
To switch the y-axis scale to logarithmic, use the axes toolbar. 
For more information about the plot, see Monitor Deep Learning Training Progress.
Since R2023b
Metrics to monitor, specified as one of these values:
Built-in metric or loss function name — Specify metrics as a string scalar, character vector, cell array, or string array of one or more of these names:
Metrics:
"accuracy"— Accuracy (also known as top-1 accuracy)"auc"— Area under ROC curve (AUC)"fscore"— F-score (also known as F1-score)"precision"— Precision"recall"— Recall"rmse"— Root mean squared error"mape"— Mean absolute percentage error (MAPE) (since R2024b)"rsquared"— R2 (R-squared or coefficient of determination) (since R2025a)
Loss functions:
"crossentropy"— Cross-entropy loss for classification tasks (since R2024b)"indexcrossentropy"— Index cross-entropy loss for classification tasks (since R2024b)"binary-crossentropy"— Binary cross-entropy loss for binary and multilabel classification tasks (since R2024b)"mae"/"mean-absolute-error"/"l1loss"— Mean absolute error for regression tasks (since R2024b)"mse"/"mean-squared-error"/"l2loss"— Mean squared error for regression tasks (since R2024b)"huber"— Huber loss for regression tasks (since R2024b)
Setting the loss function as
"crossentropy"and specifying"index-crossentropy"as a metric or setting the loss function as"index-crossentropy"and specifying"crossentropy"as a metric is not supported.For more information about deep learning metrics and loss functions, see Deep Learning Metrics.
Built-in metric objects — If you need more flexibility, you can use built-in metric objects. The software supports these built-in metric objects:
MAPEMetric(since R2024b)RSquaredMetric(since R2025a)
When you create a built-in metric object, you can specify additional options such as the averaging type and whether the task is single-label or multilabel.
Custom metric function handle — If the metric you need is not a built-in metric, then you can specify custom metrics using a function handle. The function must have the syntax
metric = metricFunction(Y,T), whereYcorresponds to the network predictions andTcorresponds to the target responses. For networks with multiple outputs, the syntax must bemetric = metricFunction(Y1,...,YN,T1,...,TM), whereNis the number of outputs andMis the number of targets. For more information, see Define Custom Metric Function.Note
When you have data in mini-batches, the software computes the metric for each mini-batch and then returns the average of those values. For some metrics, this behavior can result in a different metric value than if you compute the metric using the whole data set at once. In most cases, the values are similar. To use a custom metric that is not batch-averaged for the data, you must create a custom metric object. For more information, see Define Custom Deep Learning Metric Object.
deep.DifferentiableFunctionobject (since R2024a) — Function object with custom backward function. For categorical targets, the software automatically converts the categorical values to one-hot encoded vectors and passes them to the metric function. For more information, see Define Custom Deep Learning Operations.Custom metric object — If you need greater customization, then you can define your own custom metric object. For an example that shows how to create a custom metric, see Define Custom Metric Object. For general information about creating custom metrics, see Define Custom Deep Learning Metric Object.
If you specify a metric as a function handle, a deep.DifferentiableFunction
object, or a custom metric object and train the neural network using the
trainnet function, then the layout of the targets that the software
passes to the metric depends on the data type of the targets. The loss function that you
specify in the trainnet function and the other metrics that you specify
have these effects on the software:
If the targets are numeric arrays, then the software passes the targets to the metric directly.
If the loss function is
"index-crossentropy"and the targets are categorical arrays, then the software automatically converts the targets to numeric class indices and passes them to the metric.For other loss functions, if the targets are categorical arrays, then the software automatically converts the targets to one-hot encoded vectors and then passes them to the metric.
This option supports the trainnet and
trainBERTDocumentClassifier (Text Analytics Toolbox) functions only.
Example: Metrics=["accuracy","fscore"]
Example: Metrics={"accuracy",@myFunction,precisionObj}
Since R2024a
Name of objective metric to use for early stopping and returning the best network, specified as a string scalar or character vector.
The metric name must be "loss" or match the name of a metric specified by
the Metrics argument. Metrics specified using function handles are not
supported. To specify the ObjectiveMetricName value as the name of a
custom metric, the value of the Maximize property of the custom metric
object must be nonempty. For more information, see Define Custom Deep Learning Metric Object.
For more information about specifying the objective metric for early stopping, see ValidationPatience. For more information about returning the best network using the objective metric, see OutputNetwork.
Data Types: char | string
Flag to display training progress information in the command window, specified as
1 (true) or 0
(false).
When you use the trainnet function, the verbose output displays a
table with these variables:
| Variable | Description |
|---|---|
Iteration | Iteration number. |
Epoch | Epoch number. |
TimeElapsed | Time elapsed in hours, minutes, and seconds. |
LearnRate | Learning rate. |
TrainingLoss | Training loss. |
ValidationLoss | Validation loss. If you do not specify validation data, then the software does not display this information. |
If you specify additional metrics in the training options, then
they also appear in the verbose output. For example, if you set the Metrics
training option to "accuracy", then the information includes the
TrainingAccuracy and ValidationAccuracy
variables.
When training stops, the verbose output displays the reason for stopping.
To specify validation data, use the ValidationData training option.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | logical
Frequency of verbose printing, which is the number of iterations between printing to the Command Window, specified as a positive integer.
If you validate the neural network during training, then the software also prints to the Command Window every time validation occurs.
To enable this property, set the Verbose training option to
1 (true).
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Output functions to call during training, specified as a function handle or cell array of function handles. The software calls the functions once before the start of training, after each iteration, and once when training is complete.
The functions must have the syntax stopFlag = f(info), where info is a structure containing information about the training progress, and stopFlag is a scalar that indicates to stop training early. If stopFlag is 1 (true), then the software stops training. Otherwise, the software continues training.
The trainnet function passes the output function the structure
info that contains these fields:
| Field | Description |
|---|---|
Epoch | Epoch number |
Iteration | Iteration number |
TimeElapsed | Time since start of training |
LearnRate | Iteration learn rate |
TrainingLoss | Iteration training loss |
ValidationLoss | Validation loss, if specified and evaluated at iteration. |
State | Iteration training state, specified as "start", "iteration", or "done". |
If you specify additional metrics in the training options, then
they also appear in the training information. For example, if you set the
Metrics training option to "accuracy", then the
information includes the TrainingAccuracy and
ValidationAccuracy fields.
If a field is not calculated or relevant for a certain call to the output functions, then that field contains an empty array.
For an example showing how to use output functions, see Custom Stopping Criteria for Deep Learning Training.
Data Types: function_handle | cell
Validation
Data to use for validation during training, specified as [],
datastore, table, cell array, or minibatchqueue object that contains
the validation predictors and targets.
During training, the software uses the validation data to calculate the validation loss and
metric values. To specify the validation frequency, use the ValidationFrequency training option. You can also use the validation data to
stop training automatically when the validation objective metric stops improving. By
default, the objective metric is set to the loss. To turn on automatic validation stopping,
use the ValidationPatience training option.
If ValidationData is [], then the software does
not validate the neural network during training.
If your neural network has layers that behave differently during prediction than during training (for example, dropout layers), then the validation loss can be lower than the training loss.
The software shuffles the validation data according to the Shuffle training option. If
Shuffle is "every-epoch", then the software
shuffles the validation data before each neural network validation.
The supported formats depend on the training function that you use.
trainnet Function
Specify the validation data as a datastore, table, minibatchqueue object, or
cell array {predictors,targets}, where predictors
contains the validation predictors and targets contains the validation
targets. Specify the values of the validation predictors and targets using any of the
layouts supported by the trainnet
function.
For more information, see the input arguments of the trainnet function.
trainBERTDocumentClassifier Function (Text Analytics Toolbox)
Specify the validation data as one of these values:
Cell array
{documents,targets}, wheredocumentscontains the input documents, andtargetscontains the document labels.Table, where the first variable contains the input documents and the second variable contains the document labels.
For more information, see the input arguments of the trainBERTDocumentClassifier (Text Analytics Toolbox) function.
Frequency of neural network validation in number of iterations, specified as a positive integer.
The ValidationFrequency value is the number of iterations between
evaluations of validation metrics. To specify validation data, use the ValidationData training option.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Patience of validation stopping of neural network training, specified as a positive integer or Inf.
ValidationPatience specifies the number of times that the objective metric on the validation set can be worse than or equal to the previous best value before neural network training stops. If ValidationPatience is Inf, then the values of the validation metric do not cause training to stop early. The software aims to maximize or minimize the metric, as specified by the Maximize property of the metric. When the objective metric is "loss", the software aims to minimize the loss value.
The returned neural network depends on the OutputNetwork training option. To return the neural network with the best validation metric value, set the OutputNetwork training option to "best-validation".
Before R2024a: The software computes the validation patience using the validation loss value.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Neural network to return when training completes, specified as one of the following:
"auto"– Use"best-validation"ifValidationDatais specified. Otherwise, use"last-iteration"."best-validation"– Return the neural network corresponding to the training iteration with the best validation metric value, where the metric to optimize is specified by theObjectiveMetricNameoption. To use this option, you must specify theValidationDatatraining option."last-iteration"– Return the neural network corresponding to the last training iteration.
Normalization and Regularization
Since R2026a
Flag to normalize targets, specified as one of these values:
1(true) — Normalize the targets.0(false) — Do not normalize the targets.
If NormalizeTargets is 1
(true), then the neural network that you train must have an
inverseNormalizationLayer object. The software uses the normalization
method specified by the Normalization property of the inverse normalization layer.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | logical
Mode to evaluate the statistics in batch normalization layers, specified as one of the following:
"population"— Use the population statistics. After training, the software finalizes the statistics by passing through the training data again and uses the resulting mean and variance."moving"— Approximate the statistics during training using a running estimate given by update stepswhere and denote the updated mean and variance, respectively, and denote the mean and variance decay values, respectively, and denote the mean and variance of the layer input, respectively, and and denote the latest values of the moving mean and variance values, respectively. After training, the software uses the most recent value of the moving mean and variance statistics. This option supports CPU and single GPU training only.
"auto"— Use the"moving"option.
Flag to reset input layer normalization statistics, specified as one of these values:
1(true) — Reset the input layer normalization statistics and recalculate them at training time.0(false) — Use the normalization statistics given by the input layer properties at training time. When the layer properties are[], the software initializes the statistics with the default value for the corresponding statistic.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | logical
Since R2026a
Flag to reset inverse normalization layer statistics, specified as one of these values:
1(true) — Reset the inverse normalization layer statistics and recalculate them at training time.0(false) — Calculate inverse normalization layer statistics at training time when they are empty.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | logical
Factor for L2 regularization (weight decay), specified as a nonnegative scalar. For more information, see L2 Regularization.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Gradient Clipping
Gradient threshold, specified as Inf or a positive scalar. If the gradient
exceeds the value of GradientThreshold, then the gradient is clipped
according to the GradientThresholdMethod argument.
For more information, see Gradient Clipping.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Gradient threshold method used to clip gradient values that exceed the gradient threshold, specified as one of the following:
"l2norm"— If the L2 norm of the gradient of a learnable parameter is larger thanGradientThreshold, then scale the gradient so that the L2 norm equalsGradientThreshold."global-l2norm"— If the global L2 norm, L, is larger thanGradientThreshold, then scale all gradients by a factor ofGradientThreshold/L. The global L2 norm considers all learnable parameters."absolute-value"— If the absolute value of an individual partial derivative in the gradient of a learnable parameter is larger thanGradientThreshold, then scale the partial derivative to have magnitude equal toGradientThresholdand retain the sign of the partial derivative.
For more information, see Gradient Clipping.
Sequence
Option to pad or truncate input sequences, specified as one of these values:
"longest"— Pad sequences in each mini-batch to have the same length as the longest sequence. This option does not discard any data, though padding can introduce noise to the neural network."shortest"— Truncate sequences in each mini-batch to have the same length as the shortest sequence. This option ensures that no padding is added, at the cost of discarding data.
To learn more about the effect of padding and truncating sequences, see Sequence Padding and Truncation.
Direction of padding or truncation, specified as one of these options:
"right"— Pad or truncate sequences on the right. The sequences start at the same time step and the software truncates or adds padding to the end of each sequence."left"— Pad or truncate sequences on the left. The software truncates or adds padding to the start of each sequence so that the sequences end at the same time step.
Recurrent layers process sequence data one time step at a time, so when the recurrent layer
OutputMode property is "last", any padding in the
final time steps can negatively influence the layer output. To pad or truncate sequence data
on the left, set the SequencePaddingDirection name-value argument to
"left".
For sequence-to-sequence neural networks (when the OutputMode property is
"sequence" for each recurrent layer), any padding in the first time
steps can negatively influence the predictions for the earlier time steps. To pad or
truncate sequence data on the right, set the SequencePaddingDirection name-value argument to "right".
To learn more about the effects of padding and truncating sequences, see Sequence Padding and Truncation.
Value for padding the input sequences, specified as a scalar.
Do not pad sequences with NaN, because doing so can
propagate errors through the neural network.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Hardware and Acceleration
Hardware resource for training neural network, specified as one of these values:
"auto"– Use a local GPU if one is available. Otherwise, use the local CPU."cpu"– Use the local CPU."gpu"– Use the local GPU."multi-gpu"– Use multiple GPUs on one machine, using a local parallel pool based on your default cluster profile. If there is no current parallel pool, the software starts a parallel pool with pool size equal to the number of available GPUs."parallel-auto"– Use a local or remote parallel pool. If there is no current parallel pool, the software starts one using the default cluster profile. If the pool has access to GPUs, then only workers with a unique GPU perform training computation and excess workers become idle. If the pool does not have GPUs, then training takes place on all available CPU workers instead. (since R2024a)Before R2024a: Use
"parallel"instead."parallel-cpu"– Use CPU resources in a local or remote parallel pool, ignoring any GPUs. If there is no current parallel pool, the software starts one using the default cluster profile. (since R2023b)"parallel-gpu"– Use GPUs in a local or remote parallel pool. Excess workers become idle. If there is no current parallel pool, the software starts one using the default cluster profile. (since R2023b)
The "gpu", "multi-gpu",
"parallel-auto", "parallel-cpu", and
"parallel-gpu" options require Parallel Computing Toolbox™. To use a GPU for deep learning, you
must also have a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox). If you
choose one of these options and Parallel Computing Toolbox or a suitable GPU is not available, then the software returns an error.
For more information on when to use the different execution environments, see Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud.
To see an improvement in performance when training in parallel, try scaling up the MiniBatchSize and InitialLearnRate training options by the number of GPUs.
Since R2024a
Environment for fetching and preprocessing data from a datastore during training, specified as one of these values:
"serial"– Fetch and preprocess data in serial."background"– Fetch and preprocess data using the background pool."parallel"– Fetch and preprocess data using parallel workers. The software opens a parallel pool using the default profile, if a local pool is not currently open. Non-local parallel pools are not supported. Using this option requires Parallel Computing Toolbox. This option is not supported when training in parallel (when theExecutionEnvironmentoption is"parallel-auto","parallel-cpu","parallel-gpu", or"multi-gpu").
To use the "background" or "parallel" options, the input datastore must be subsettable or partitionable. Custom datastores must implement the matlab.io.datastore.Subsettable class.
The "background" and "parallel" options are not
supported when the Shuffle option is "never".
If you use the "background" and "parallel" options,
then training is non-deterministic even if you use the deep.gpu.deterministicAlgorithms function.
Use the "background" option when your mini-batches require significant
preprocessing. If your preprocessing is not supported on threads, or if you need to control
the number of workers, use the "parallel" option. For more information
about the preprocessing environment, see Preprocess Data in the Background or in Parallel.
Before R2024a: To preprocess data in parallel,
set the DispatchInBackground training option to
1 (true).
Since R2024a
Performance optimization, specified as one of these values:
"auto"– Automatically apply a number of optimizations suitable for the input network and hardware resources."none"– Disable all optimizations.
Using the "auto" acceleration option can offer performance benefits,
but at the expense of an increased initial run time. Subsequent calls with compatible
parameters are faster. Use performance optimization when you plan to call the function
multiple times using different input data with the same size and shape.
Checkpoints
Path for saving the checkpoint neural networks, specified as a string scalar or character vector.
If you do not specify a path (that is, you use the default
""), then the software does not save any checkpoint neural networks.If you specify a path, then the software saves checkpoint neural networks to this path and assigns a unique name to each neural network. You can then load any checkpoint neural network and resume training from that neural network.
If the folder does not exist, then you must first create it before specifying the path for saving the checkpoint neural networks. If the path you specify does not exist, then the software throws an error.
Data Types: char | string
Frequency of saving checkpoint neural networks, specified as a positive integer.
If CheckpointFrequencyUnit is "epoch", then the software
saves checkpoint neural networks every CheckpointFrequency
epochs.
If CheckpointFrequencyUnit is "iteration", then the
software saves checkpoint neural networks every
CheckpointFrequency iterations.
This option only has an effect when CheckpointPath is
nonempty.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Checkpoint frequency unit, specified as "epoch" or "iteration".
If CheckpointFrequencyUnit is "epoch", then the software
saves checkpoint neural networks every CheckpointFrequency
epochs.
If CheckpointFrequencyUnit is "iteration", then the
software saves checkpoint neural networks every
CheckpointFrequency iterations.
This option only has an effect when CheckpointPath is nonempty.
Examples
Algorithms
References
[1] Bishop, C. M. Pattern Recognition and Machine Learning. Springer, New York, NY, 2006.
[2] Murphy, K. P. Machine Learning: A Probabilistic Perspective. The MIT Press, Cambridge, Massachusetts, 2012.
[3] Pascanu, R., T. Mikolov, and Y. Bengio. "On the difficulty of training recurrent neural networks". Proceedings of the 30th International Conference on Machine Learning. Vol. 28(3), 2013, pp. 1310–1318.