Speaker Diarization Using Pretrained AI Models
Speaker diarization is the process of partitioning an audio signal into segments according to speaker identity. It answers the question "who spoke when?" without prior knowledge of the speakers and, depending on the application, without prior knowledge of the number of speakers.
Speaker diarization has many applications, including enhancing speech transcription, video captioning, content retrieval (what did Jane say?), and speaker counting (how many speakers were present in the meeting?).
In this example, you use the speakerEmbeddings function to extract compact speaker representations. The speakerEmbeddings function utilizes a pretrained ECAPA-TDNN model [1] [2]. In this example, you perform two different workflows:
Batch speaker diarization performed on a complete audio sample.
Streaming speaker diarization performed on streaming audio input.
In both cases, you combine speaker diarization with Whisper [3] speech-to-text. The diarization results in the Batch Diarization section are not postprocessed in any way. Usually, after a first pass of diarization, segments are redrawn with speech continuity in mind. These results without postprocessing reflect most directly on the discriminative power of the ECAPA-TDNN model, and so this is a good framework to comparing directly with other models. In the Streaming Diarization section, you perform diarization on streaming audio. The supporting object, SpeechDiarizer, and the code within the script, do some post-processing to improve the diarization. In that section, you additionally have the option to pre-enroll the speakers to improve results further. Because of the post-processing in the streaming section, results are better than the batch diarization section even though the task is more difficult.
For an example of batch speaker diarization using an x-vector system, see Speaker Diarization Using x-vectors.
Batch Diarization
Read in an audio sample and inspect it. You will attempt to diarize the signal in this example. The signal consists of four speakers having a casual conversation about travel plans and lunch.
[x,fs] = audioread("Conversation-16-mono-330secs.ogg");
audioViewer(x,fs)
Buffer the signal into overlapped frames. You make predictions for each frame and then map that prediction back to the corresponding samples in the original audio signal. The frame duration minus the overlap duration is the resolution for speaker decisions. The default frame and overlap values are the ones described in [2].
frameDuration =3; overlapDuration =
1.5; xb = framesig(x, ... round(frameDuration*fs), ... OverlapLength=round(overlapDuration*fs), ... IncompleteFrameRule="zeropad");
To extract speaker embeddings for each frame of data, call speakerEmbeddings. Partition the matrix to avoid out-of-memory issues.
numFramesPerCall =128; embeddingLength = 192; % Known embedding length of ECAPA-TDNN model numCalls = ceil(size(xb,2)/numFramesPerCall); e = zeros(embeddingLength,size(xb,2),"single"); idx = 1:numCalls; for ii = 1:numCalls startIdx = (ii-1)*numFramesPerCall + 1; endIdx = min(ii*numFramesPerCall,size(xb,2)); idx = startIdx:endIdx; xbf = xb(:,idx); if canUseGPU xbf = gpuArray(xbf); end e(:,idx) = gather(speakerEmbeddings(xbf,fs)); end
To assign each embedding vector to a frame, use spectralcluster. Assume a known number of speakers.
numSpeakers = 4;
idxPerFrame = spectralcluster(e',numSpeakers,Distance="cosine");Replicate the decisions so that they are per sample. Use signalMask to plot the original speech signal and diarization results. Isolate and listen to the different speakers.
hopDuration = frameDuration - overlapDuration; idxPerSample = [repelem(idxPerFrame(1),round(fs*(frameDuration + hopDuration/2)),1); ... repelem(idxPerFrame(2:end-1),round(hopDuration*fs)); repelem(idxPerFrame(end),round(fs*(frameDuration + hopDuration/2)),1)]; idxPerSample(numel(x):end) = []; sound(x(idxPerSample==3),fs) m = signalMask(categorical(idxPerSample)); plotsigroi(m,x,true)
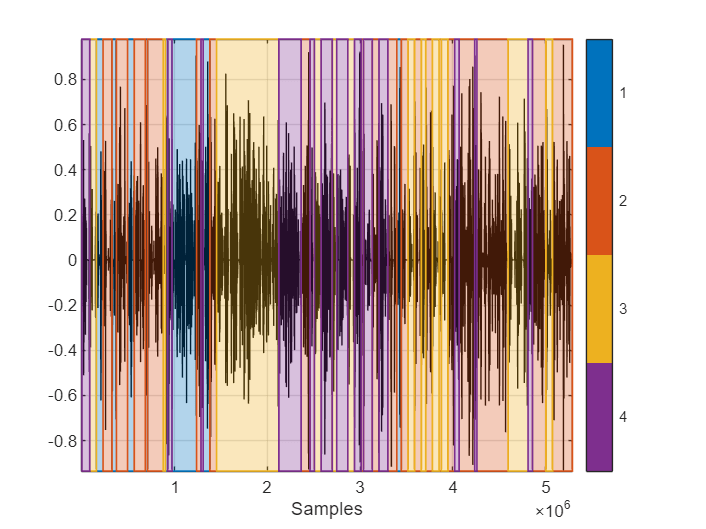
Speaker diarization is often an intermediary step to meeting transcription. Create a transcript of the speech using the Whisper model [3]. The Whisper model requires Audio Toolbox Interface to SpeechBrain and Torchaudio Libraries.
If you have access to a compute GPU, set the execution environment of the speechClient to gpu.
if canUseGPU ee = 'gpu'; else ee = 'cpu'; end sc_large = speechClient('whisper', ... ModelSize='large', ... Language='english', ... ExecutionEnvironment=ee);
Perform speech-to-text on each speaker segment.
changepoints = [1;find(diff(idxPerSample)~=0);size(x,1)]; for ii = 1:(numel(changepoints)-1) txt = speech2text(x(changepoints(ii):changepoints(ii+1)-1),fs,Client=sc_large); speakerid = idxPerSample(changepoints(ii)); display("speaker " + speakerid +": " + txt) end
"speaker 4: Okay. Hi, my name is Maya. Nice to meet you, everyone. Hi."
"speaker 4: My name is Kumar. Nice to meet everyone. And I'm Brian."
"speaker 3: Nice to meet you everyone. And I already introduced myself."
"speaker 1: You have a lovely accent."
"speaker 2: Thanks."
"speaker 1: I'm from the south. Texas, right? That's right. Okay."
"speaker 2: Steven, do you have any vacation plans coming up? Actually,"
"speaker 1: I'm taking some time off next week. Yeah. How about you? What are you going to do? Oh,"
"speaker 2: Just stay home"
"speaker 1: sleep a lot, you know, nothing special. Yeah. I'm not going to France. I heard somebody's going to France soon. Who's going to France? That's me."
"speaker 2: me."
"speaker 3: Oh, tell us about that."
"speaker 1: then we're going for a"
"speaker 4: Three weeks. We're just three different Airbnbs. We're pretty excited. We're going to be working a little bit. Sure. This will be the first time trying that. You don't believe me, Steven? No. I'll believe it."
"speaker 1: when I see it. Not from France."
"speaker 2: I mean, I'll answer emails."
"speaker 4: We'll see about that."
"speaker 1: Kumar, what about you? Kumar, are you going anywhere? I am planning"
"speaker 2: to go to Canada later in the summer, in August, to Banff National Park and some places in Alberta. I've been wanting to go there for a few years now, but because it's got a very short window where you can travel when there are many lakes and they get frozen in the winter, only in a few months in a year they are not frozen which is the peak of summer and I want to go in that duration July, August, September. Finally I'm making a plan to go this year. Yes I'm also"
"speaker 3: traveling next week going to Colorado so we'll spend some time in Denver and then in Boulder and then we'll go to the Rocky Mountains National Park that's the plan nice"
"speaker 4: Wow, I'm jealous. I should go somewhere. I'm just staying home. Probably. Pathetic."
"speaker 2: Is"
"speaker 4: Is Rocky Mountain going to be cold by now?"
"speaker 3: just open so it's yeah it will not be very hot but not frozen I think there's no snow the snow is almost"
"speaker 4: Yeah, yeah. So..."
"speaker 3: Hopefully it should be good. Let's see how much green it has by this time of the year."
"speaker 4: you been in higher altitudes before?"
"speaker 3: Not that much. This one is pretty high. How high is it?"
"speaker 4: I will hide."
"speaker 2: 11,000 feet? Yeah, I think so. 11,000."
"speaker 4: How much is that in meters? Do you know? Not sure, but compared"
"speaker 2: I see."
"speaker 4: Interesting. How high is Nathan? Does anybody know? I guess like 200."
"speaker 2: 200 feet or something. Oh, wow. 200."
"speaker 1: That's not bad. Maybe less."
"speaker 2: Yeah, 11,000 would be 3,300. I didn't see"
"speaker 3: you guys at lunch today where were you outside"
"speaker 2: Yeah, I was sitting outside. Oh, wow. Uh,"
"speaker 3: Wasn't it raining? No. It was actually sunny."
"speaker 2: sunny and then I think it started raining as soon as we left. Oh, wow."
"speaker 3: Lucky."
"speaker 2: Sunny, sunny, but it's bright."
"speaker 3: Did you guys have the entree? I did."
"speaker 2: Wasn't that was it good? Yeah"
"speaker 4: It looked too fried for me, so I got a salad instead. Of course you did. Yeah. I had five salads this week. Already? That's embarrassing."
"speaker 2: I mean, threes."
"speaker 4: three I'm sorry I mean they were exactly the same but I had five last week so I'm on a streak it's eight in a row I just I'm the food is always seems fried so I mean I don't like it you guys like fried food"
"speaker 2: like but not for every day maybe yeah today's food didn't cook that fried to me I don't know maybe there is also how much fried is fried yeah it was"
"speaker 3: It's healthy fried, not deep fried. There's no such thing."
"speaker 4: as healthy fried. What is this? Was it fried in olive oil? Is that what you mean? Maybe. I don't know. Maybe."
"speaker 2: A little bit of pan-fried is fine, I guess. Yeah. Yeah."
"speaker 3: This conversation is amazing. You should do this every day after lunch. What else can we talk about, Brian? We talked food, we talked travels."
Streaming Diarization
In this section, you perform streaming diarization. This section uses two objects that are specific to this example: StreamTextDisplay, which displays the results, and SpeechDiarizer, which performs the diarization. The objects are placed in the current folder when you open the example.
Create a dsp.AudioFileReader object to read in audio signals with a 2 second frame. Create an audioDeviceWriter object to play back the audio signal while performing diarization.
adw = audioDeviceWriter(fs);
afr = dsp.AudioFileReader("Conversation-16-mono-330secs.ogg");
fs = afr.SampleRate;
chunkTimeStep = 2;
afr.SamplesPerFrame = chunkTimeStep*fs;Create a SpeechDiarizer object. Set the resolution in seconds and the frame size in samples. The speech diarizer object uses the speakerEmbeddings function to characterize speakers and compares utterances using cosine similarity scoring. The object additionally uses a lookahead of half the frame size, meaning the total algorithmic delay introduced is 1.5 * frame size.
diarizer = SpeechDiarizer( ... FrameSize=afr.SamplesPerFrame, ... SampleRate=fs, ... Resolution=0.01);
Optionally pre-enroll the speakers by using the introductory statements. Pre-enrollment is a common real-life scenario.
preEnrollSpeakers =true; if preEnrollSpeakers [x,fs] = audioread('Conversation-16-mono-330secs.ogg'); Maya = x(1:4*fs); Kumar = x(4*fs:8*fs); Brian = x(8*fs:12*fs); Steven = x(12*fs:15.5*fs); enroll(diarizer,{Maya,Kumar,Brian,Steven},{'Maya','Kumar','Brian','Steven'}) end
Optionally set the maximum number of speakers the system can enroll.
setMaxNumSpeakers =true; if setMaxNumSpeakers diarizer.MaxNumSpeakers = 4; end
Create two buffers: one to buffer the signal for the lower-latency diarization, and one to buffer the signal for the speech-to-text cleanup.
buffShort = dsp.AsyncBuffer(Capacity=fs*90); buffLong = dsp.AsyncBuffer(Capacity=fs*60*5);
Create a tiny Whisper model to perform streaming transcription. You reuse the large model created earlier for the speech-to-text cleanup.
sc_tiny = speechClient('whisper', ... ModelSize='tiny', ... language='english', ... ExecutionEnvironment=ee);
Create a StreamTextDisplay object to display the diarization and speech-to-text results as they come.
textPlotter = StreamTextDisplay();
Create a dsp.Delay object to align the audio input with the speaker diarization results.
delayline = dsp.Delay(diarizer.Lookahead*afr.SampleRate);
Perform streaming diarization.
% Set parameters maxDelay = 2; % seconds padRead = round(0.1*fs); % Pad the read on both sides for cleanup. % Initialize variable states previousSpeakerCorrection = 0; runCleanup = false; % Run loop while ~isDone(afr) % Read from file. x = afr(); x = single(mean(x,2)); % Write to audio output device adw(x); % Input the new audio signal to the diarizer and return the delayed results. if canUseGPU speaker = diarize(diarizer,gpuArray(x)); else speaker = diarize(diarizer,x); end % Delay the input signal and then write the aligned audio signal and speaker % labels to the buffers. xd = delayline(x); write(buffLong,[xd,speaker]); write(buffShort,[xd,speaker]); % If max delay reached, attempt to read from buffer then update and % display results. if (buffShort.NumUnreadSamples/fs) > maxDelay alldata_peek = peek(buffShort); % Find speaker changes in the buffer changepoints = find(diff([alldata_peek(:,2)])); if isempty(changepoints) % Read everything at once. changepoints = buffShort.NumUnreadSamples; else % Flag to run speech-to-text over completed speaker turn. runCleanup = true; end for ii = 1:numel(changepoints) % Read until the speaker change and then update the relative % position of the changepoints vector. alldata = read(buffShort,changepoints(ii)); changepoints = changepoints - changepoints(ii) + 1; if ~isempty(alldata) % Unpack the audio and speaker ID allaudio = alldata(:,1); speakerID = alldata(1,2); % Double-check that speech is present using classifySound and then perform % speech-to-text. m = classifySound(allaudio,fs); if speakerID~=0 && any(contains(m,"Speech")) txt = speech2text(allaudio,fs,Client=sc_tiny); if ~isequal(txt,"") appendText(textPlotter,diarizer.EnrolledLabels.SpeakerName(speakerID),txt) drawnow end end end end end % Clean up speech-to-text results by performing over larger chunks. if runCleanup cellToCorrect = textPlotter.CurrentCell; if cellToCorrect~=0 % Peek the long term buffer and find any speaker change points buffpeeked = peek(buffLong); changepoints = find(diff([buffpeeked(:,2)])); % Loop over changepoints for ii = 1:numel(changepoints) speechChunkToCorrect = peek(buffLong,changepoints(ii) + 2*padRead,padRead); speakerID = speechChunkToCorrect(padRead+1,2); if speakerID~=0 speechChunkToCorrect = speechChunkToCorrect(:,1); if previousSpeakerCorrection==speakerID % There was a false speaker change (a speaker change % detected but it turned out to not contain any % speech). speechChunkToCorrect(1:padRead) = []; % Remove back padding speechChunkToCorrect = cat(1,holdover(:,1),speechChunkToCorrect); end alltxt = speech2text(speechChunkToCorrect,fs,Client=sc_large); cellToCorrect = textPlotter.CurrentCell; correctText(textPlotter,diarizer.EnrolledLabels.SpeakerName(speakerID),alltxt,cellToCorrect) drawnow end % Move the read pointer forward but without the backwards % pad. Save the state in case we need to append it to the % segment if there was a false discontinuity in the speaker % ID. if strcmp(previousSpeakerCorrection,speakerID) || speakerID==0 newholdover = read(buffLong,changepoints(ii) + padRead,padRead); holdover = cat(1,holdover,newholdover); else holdover = read(buffLong,changepoints(ii) + padRead,padRead); end % Update the relative positions of the changepoints changepoints = changepoints - changepoints(ii) + 1; % Update the log of the previous speaker ID if speakerID~=0 previousSpeakerCorrection = speakerID; end end end runCleanup = false; end end

References
[1] Desplanques, Brecht, Jenthe Thienpondt, and Kris Demuynck. "ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification." In Interspeech 2020, 3830–34. ISCA, 2020. https://doi.org/10.21437/Interspeech.2020-2650.
[2] Dawalatabad, Nauman, Mirco Ravanelli, François Grondin, Jenthe Thienpondt, Brecht Desplanques, and Hwidong Na. "ECAPA-TDNN Embeddings for Speaker Diarization." In Interspeech 2021, 3560–64. ISCA, 2021. https://doi.org/10.21437/Interspeech.2021-941.
[3] Radford, Alec, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. "Robust speech recognition via large-scale weak supervision." In International Conference on Machine Learning, pp. 28492-28518. PMLR, 2023.