speakerEmbeddings
Description
Examples
Try calling speakerEmbeddings in the command line. If the required model files are not installed, then the function throws an error and provides a link to download them. Click the link, and unzip the file to a location on the MATLAB® path.
Alternatively, execute the following commands to download and unzip the speakerEmbeddings model files to your temporary directory.
downloadFolder = fullfile(tempdir,"speakerEmbeddingsDownload"); loc = websave(downloadFolder,"https://ssd.mathworks.com/supportfiles/audio/spkrec-ecapa-voxceleb-weights.zip"); modelsLocation = tempdir; unzip(loc,modelsLocation) addpath(fullfile(modelsLocation,"spkrec-ecapa-voxceleb-weights"))
Read in three different speech signals. The first two signals, x1 and x2, contain speech from the same speaker, but x3 contains speech from another person.
[x1,fs1] = audioread("CleanSpeech-16-mono-3secs.ogg"); [x2,fs2] = audioread("MusicAndSpeech-16-mono-14secs.ogg"); [x3,fs3] = audioread("Rainbow-16-8-mono-114secs.wav");
Use speakerEmbeddings to extract speaker embeddings from each signal.
e1 = speakerEmbeddings(x1,fs1); e2 = speakerEmbeddings(x2,fs2); e3 = speakerEmbeddings(x3,fs3);
Use cosine similarity to compare the speaker embeddings of the x1 and x3 signals, and use the threshold of 0.25 to determine if they belong to the same speaker. This value has been empirically shown to be a good threshold across different data sets for the pretrained model used by speakerEmbeddings.
function out = cosineSimilarity(e1,e2) out = dot(e1,e2)/(norm(e1)*norm(e2)); end threshold = 0.25; cosSim = cosineSimilarity(e1,e3)
cosSim = single
-0.0848
isSameSpeaker = cosSim > threshold
isSameSpeaker = logical
0
Compare the embeddings of the x1 and x2 signals and see how they are correctly identified as belonging to the same speaker.
cosSim = cosineSimilarity(e1,e2)
cosSim = single
0.4939
isSameSpeaker = cosSim > threshold
isSameSpeaker = logical
1
Read in speech signals from four different speakers: Brian, Steven, Maya, and Kumar. Extract an embedding vector for each speaker.
[x1,fs1] = audioread("brian_speech.wav"); e1 = speakerEmbeddings(x1,fs1); [x2,fs2] = audioread("steven_speech.wav"); e2 = speakerEmbeddings(x2,fs2); [x3,fs3] = audioread("maya_speech.wav"); e3 = speakerEmbeddings(x3,fs3); [x4,fs4] = audioread("kumar_speech.wav"); e4 = speakerEmbeddings(x4,fs4); speakers = ["Brian","Steven","Maya","Kumar"]; embeddings = [e1,e2,e3,e4];
Define a vectorized cosine similarity function for efficient comparison of multiple embeddings at once.
function y = cosineSimilarity(x1,x2) y = squeeze(sum(x1.*reshape(x2,size(x2,1),1,[]),1)./ ... (vecnorm(x1).*reshape(vecnorm(x2),1,1,[]))); end
Read in a different audio signal containing Brian's speech and extract the speaker embedding.
[x,fs] = audioread("CleanSpeech-16-mono-3secs.ogg");
brianEmbedding = speakerEmbeddings(x,fs);Compare the new embedding against the existing known speaker embeddings and view the results in a table. See how Brian is correctly identified with the highest score out of the speakers.
scores = cosineSimilarity(brianEmbedding,embeddings);
[scoresSorted,idx] = sort(scores,"descend");
speakersSorted = speakers(idx);
table(speakersSorted(:),scoresSorted)ans=4×2 table
"Brian" 0.2983
"Kumar" 0.0154
"Maya" -0.0064
"Steven" -0.0428
Read in a new signal containing Steven's speech and perform the same speaker identification.
[x,fs] = audioread("Counting-16-44p1-mono-15secs.wav"); stevenEmbedding = speakerEmbeddings(x,fs); scores = cosineSimilarity(stevenEmbedding,embeddings); [scoresSorted,idx] = sort(scores,"descend"); speakersSorted = speakers(idx); table(speakersSorted(:),scoresSorted)
ans=4×2 table
"Steven" 0.3137
"Maya" 0.0959
"Kumar" 0.0395
"Brian" -0.0846
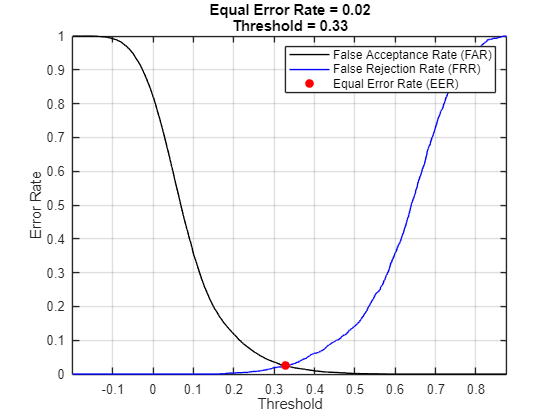
Using speakerEmbeddings for speaker verification requires a threshold for the similarity scores to decide whether a speaker has been verified. You can evaluate different thresholds for a speaker verification system by measuring the false acceptance rate (FAR) and the false rejection rate (FRR) of the system for given thresholds. The equal error rate (EER), which is the point at which the FAR and FRR for a system are equal, is commonly used to evaluate speaker verification systems and can be used to determine a threshold that balances the FAR and FRR.
Use a subset of the Common Voice data set from Mozilla[1] to measure the EER with speakerEmbeddings. Create an audioDatastore object for the data set with the given helper function.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","commonvoice.zip"); dataFolder = tempdir; if ~datasetExists(string(dataFolder) + "commonvoice") unzip(downloadFolder,dataFolder); end ads = commonVoiceHelper; fs = 48e3;
Extract speaker embeddings from all of the signals in the data set.
ads_embeddings = transform(ads,@(x){speakerEmbeddings(x,fs)});
embeddings = readall(ads_embeddings,UseParallel=true);
embeddings = cat(2,embeddings{:});Measure the cosine similarity between all pairs of embedding vectors.
allscores = cosineSimilarity(embeddings,embeddings);
Use the speaker labels to create a matrix indicating which similarity scores correspond to two embeddings from the same speaker.
class_matrix = ads.Labels' == ads.Labels;
Separate the similarity scores into scores for the same speakers (scoreSame) and scores for different speakers (scoreDifferent).
n = size(allscores,1); lower_triangular_logical = tril(ones(n,n),-1) == 1; allscores(~lower_triangular_logical) = nan; scoreSame = allscores(class_matrix); scoreDifferent = allscores(~class_matrix); scoreSame(isnan(scoreSame)) = []; scoreDifferent(isnan(scoreDifferent)) = [];
Choose 1000 thresholds to evaluate, ranging from the minimum of the scores for different speakers to the maximum of the scores for same speakers. For each threshold measure the FAR and FRR.
thresholds = linspace(min(scoreDifferent),max(scoreSame),1000); FAR = mean(scoreDifferent(:)>=thresholds(:)',1); FRR = mean(scoreSame(:)<thresholds(:)',1);
Plot the FAR and FRR and find the EER. You can use the threshold of the EER as the threshold for a speaker verification system, since it ideally balances the FAR and FRR. However, the EER threshold may not always be the best choice. For example, it might be preferable for security-critical systems to have a lower FAR at the expense of a higher FRR.
[~,EERThresholdIdx] = min(abs(FRR-FAR)); EERThreshold = thresholds(EERThresholdIdx); EER = mean([FAR(EERThresholdIdx),FRR(EERThresholdIdx)]); plot(thresholds,FAR,"k", ... thresholds,FRR,"b", ... EERThreshold,EER,"ro",MarkerFaceColor="r") title(["Equal Error Rate = " + round(EER,2), "Threshold = " + round(EERThreshold,2)]) xlabel("Threshold") ylabel("Error Rate") legend("False Acceptance Rate (FAR)","False Rejection Rate (FRR)","Equal Error Rate (EER)") grid on axis tight
function y = cosineSimilarity(x1,x2) y = squeeze(sum(x1.*reshape(x2,size(x2,1),1,[]),1)./ ... (vecnorm(x1).*reshape(vecnorm(x2),1,1,[]))); end
References
Input Arguments
Output Arguments
References
[1] Desplanques, Brecht, Jenthe Thienpondt, and Kris Demuynck. “ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification.” In Interspeech 2020, 3830–34. ISCA, 2020. https://doi.org/10.21437/Interspeech.2020-2650.
[2] Ravanelli, Mirco, et al. SpeechBrain: A General-Purpose Speech Toolkit. arXiv, 8 June 2021. arXiv.org, http://arxiv.org/abs/2106.04624
Extended Capabilities
Version History
Introduced in R2024b