Train Kernel Approximation Model Using Regression Learner App
This example shows how to create and compare various kernel approximation regression models using the Regression Learner app, and export trained models to the workspace to make predictions for new data. Kernel approximation models are typically useful for performing nonlinear regression with many observations. For large in-memory data, kernel approximation models tend to train and predict faster than SVM models with Gaussian kernels.
In the MATLAB® Command Window, load the
carbigdata set, and create a table containing the different variables.load carbig cartable = table(Acceleration,Cylinders,Displacement, ... Horsepower,Model_Year,Weight,Origin,MPG);
Click the Apps tab, and then click the Show more arrow on the right to open the apps gallery. In the Machine Learning and Deep Learning group, click Regression Learner.
On the Learn tab, in the File section, click New Session and select From Workspace.
In the New Session from Workspace dialog box, select the table
cartablefrom the Data Set Variable list.As shown in the dialog box, the app selects
MPGas the response and the other variables as predictors. For this example, do not change the selections.
To accept the default validation scheme and continue, click Start Session. The default validation option is 5-fold cross-validation, to protect against overfitting.
Regression Learner creates a plot of the response with the record number on the x-axis.
Use the response plot to investigate which variables are useful for predicting the response. To visualize the relation between different predictors and the response, select different variables in the X list under X-axis to the right of the plot. Observe which variables are correlated most clearly with the response.
Create a selection of kernel approximation models. On the Learn tab, in the Models section, click the arrow to open the gallery. In the Kernel Approximation Regression Models group, click All Kernels.
In the Train section, click Train All and select Train All.
Note
If you have Parallel Computing Toolbox™, then the Use Parallel button is selected by default. After you click Train All and select Train All or Train Selected, the app opens a parallel pool of workers. During this time, you cannot interact with the software. After the pool opens, you can continue to interact with the app while models train in parallel.
If you do not have Parallel Computing Toolbox, then the Use Background Training check box in the Train All menu is selected by default. After you select an option to train models, the app opens a background pool. After the pool opens, you can continue to interact with the app while models train in the background.
Regression Learner trains one of each kernel approximation option in the gallery, as well as the default fine tree model. In the Models pane, the app outlines the RMSE (Validation) (root mean squared error) of the best model.
Select a model in the Models pane to view the results. On the Learn tab, in the Plots and Results section, click the arrow to open the gallery, and then click Response in the Validation Results group. Examine the response plot for the trained model. True responses are blue, and predicted responses are yellow.
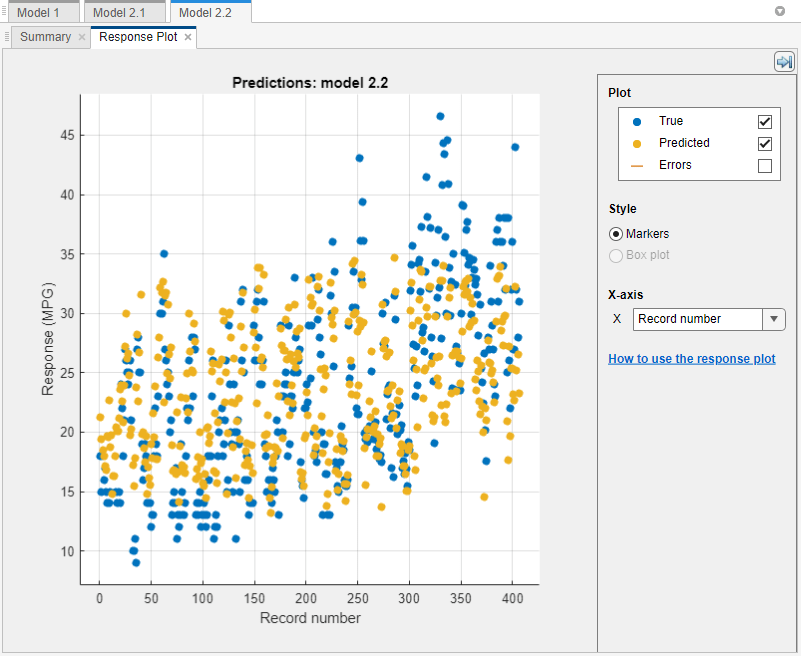
Note
Validation introduces some randomness into the results. Your model validation results can vary from the results shown in this example.
Under X-axis, select
Horsepowerand examine the response plot. Both the true and predicted responses are now plotted. Show the prediction errors, drawn as vertical lines between the predicted and true responses, by selecting the Errors check box under Plot to the right of the plot.For more information on the currently selected model, consult the Summary tab. Check and compare additional model characteristics, such as R2 (coefficient of determination), MAE (mean absolute error), and prediction speed. To learn more, see View Model Metrics in Summary Tab and Models Pane. In the Summary tab, you can also find details on the currently selected model type, such as options used for training the model.
Plot the predicted response versus the true response. On the Learn tab, in the Plots and Results section, click the arrow to open the gallery, and then click Predicted vs. Actual (Validation) in the Validation Results group. Use this plot to determine how well the regression model makes predictions for different response values.
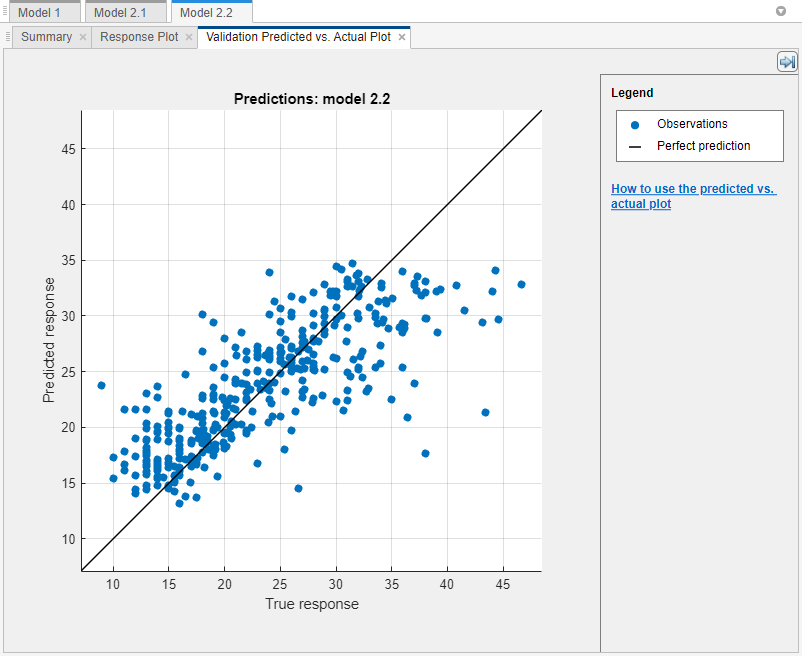
A perfect regression model has predicted responses equal to the true responses, so all the points lie on a diagonal line. The vertical distance from the line to any point is the error of the prediction for that point. A good model has small errors, so the predictions are scattered near the line. Typically, a good model has points scattered roughly symmetrically around the diagonal line. If you can see any clear patterns in the plot, you can most likely improve your model.
For each remaining model, select the model in the Models pane, open the predicted versus actual plot, and then compare the results across the models. For more information, see Compare Model Plots by Changing Layout.
To try to improve the models, include different features. In the Models gallery, select All Kernels again. See if you can improve the models by removing features with low predictive power. In the Summary tab, click Feature Selection to expand the section.
In the Feature Selection section, clear the check boxes for Acceleration and Cylinders to exclude them from the predictors. The response plot shows that these variables are not highly correlated with the response variable.
In the Train section, click Train All and select Train All or Train Selected to train the kernel approximation models using the new set of features.
Observe the new models in the Models pane. These models are the same kernel approximation models as before, but trained using only five of the seven predictors. For each model, the app displays how many predictors are used. To check which predictors are used, click a model in the Models pane and consult the Feature Selection section of the Summary tab.
The models with the two features removed perform comparably to the models with all predictors. The models predict no better using all the predictors compared to using only a subset of them. If data collection is expensive or difficult, you might prefer a model that performs satisfactorily without some predictors.
Select the model in the Models pane with the lowest validation RSME (best model), and view the residuals plot. On the Learn tab, in the Plots and Results section, click the arrow to open the gallery, and then click Residuals (Validation) in the Validation Results group. The residuals plot displays the difference between the predicted and true responses. To display the residuals as a line graph select Lines under Style.
Under X-axis, select the variable to plot on the x-axis. Choose the true response, predicted response, record number, or one of the predictors.
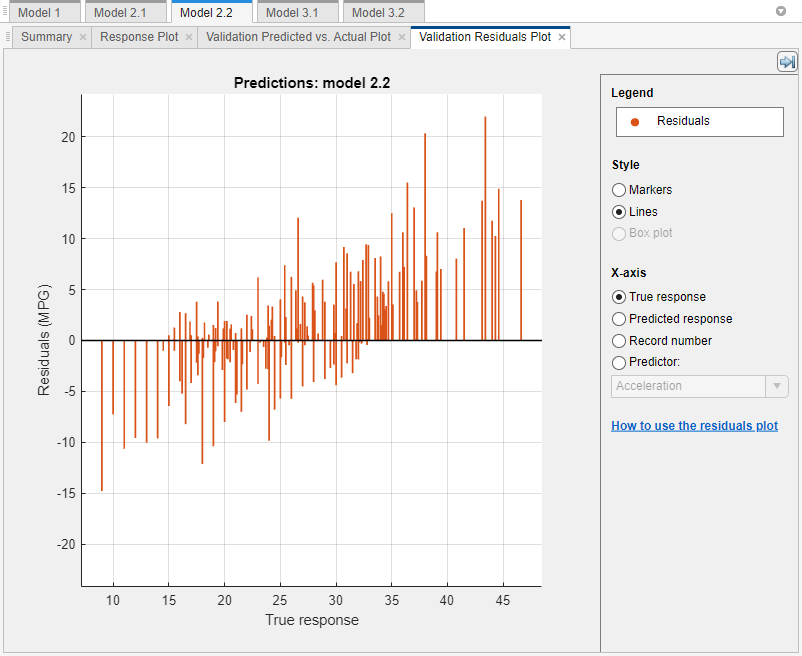
Typically, a good model has residuals scattered roughly symmetrically around 0. If you can see any clear patterns in the residuals, you can most likely improve your model.
You can try to further improve the best model in the Models pane by changing its hyperparameters. First, duplicate the model. Right-click the model and select Duplicate.
Then, in the Summary tab of the duplicated model, try changing some of the hyperparameter settings, like the kernel scale parameter or the regularization strength. Train the new model by clicking Train All and selecting Train Selected.
To learn more about kernel approximation model settings, see Kernel Approximation Models.
You can export a compact version of the trained model to the workspace. In the Export section of the Learn tab, click Export Model and select Export Model. In the Export Regression Model dialog box, the check box to include the training data is disabled because kernel approximation models do not store training data. In the dialog box, click OK to accept the default variable name.
To examine the code for training this model, click Generate Function in the Export section.
Tip
Use the same workflow to evaluate and compare the other regression model types you can train in Regression Learner.
To train all the nonoptimizable regression model presets available for your data set:
On the Learn tab, in the Models section, click the arrow to open the gallery of regression models.
In the Get Started group, click All.

In the Train section, click Train All and select Train All.
To learn about other regression model types, see Train Regression Models in Regression Learner App.
See Also
Related Topics
- Train Regression Models in Regression Learner App
- Select Data for Regression or Open Saved App Session
- Choose Regression Model Options
- Feature Selection and Feature Transformation Using Regression Learner App
- Visualize and Assess Model Performance in Regression Learner
- Export Regression Model to Predict New Data
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)