Hyperparameter Optimization in Classification Learner App
After you choose a particular type of model to train, for example a decision tree or a support vector machine (SVM), you can tune your model by selecting different advanced options. For example, you can change the maximum number of splits for a decision tree or the box constraint of an SVM. Some of these options are internal parameters of the model, or hyperparameters, that can strongly affect its performance. Instead of manually selecting these options, you can use hyperparameter optimization within the Classification Learner app to automate the selection of hyperparameter values. For a given model type, the app tries different combinations of hyperparameter values by using an optimization scheme that seeks to minimize the model classification error, and returns a model with the optimized hyperparameters. You can use the resulting model as you would any other trained model.
Note
Because hyperparameter optimization can lead to an overfitted model, the recommended approach is to create a separate test data set before importing your data into the Classification Learner app. After you train your optimizable model, you can see how it performs on your test data set. For an example, see Train Classifier Using Hyperparameter Optimization in Classification Learner App.
To perform hyperparameter optimization in Classification Learner, follow these steps:
Choose a model type and decide which hyperparameters to optimize. See Select Hyperparameters to Optimize.
Note
Hyperparameter optimization is not supported for binary GLM logistic regression models.
(Optional) Specify how the optimization is performed. For more information, see Optimization Options.
Train your model. Use the Minimum Classification Error Plot to track the optimization results.
Inspect your trained model. See Optimization Results.
Select Hyperparameters to Optimize
In the Classification Learner app, in the Models section of the Learn tab, click the arrow to open the gallery. The gallery includes optimizable models that you can train using hyperparameter optimization.
After you select an optimizable model, you can choose which of its hyperparameters you want to optimize. In the model Summary tab, in the Model Hyperparameters section, select Optimize check boxes for the hyperparameters that you want to optimize. Under Values, specify the fixed values for the hyperparameters that you do not want to optimize or that are not optimizable.
This table describes the hyperparameters that you can optimize for each type of model and the search range of each hyperparameter. It also includes the additional hyperparameters for which you can specify fixed values.
| Model | Optimizable Hyperparameters | Additional Hyperparameters | Notes |
|---|---|---|---|
| Optimizable Tree |
|
| For more information, see Tree Model Hyperparameter Options. |
| Optimizable Discriminant |
|
For more information, see Discriminant Model Hyperparameter Options. | |
| Optimizable Naive Bayes |
|
|
For more information, see Naive Bayes Model Hyperparameter Options. |
| Optimizable SVM |
|
For more information, see SVM Model Hyperparameter Options. | |
| Optimizable Efficient Linear |
|
| For more information, see Hyperparameter Options for Efficiently Trained Linear Classifiers. |
| Optimizable KNN |
| For more information, see KNN Model Hyperparameter Options. | |
| Optimizable Kernel |
|
| For more information, see Kernel Model Hyperparameter Options. |
| Optimizable Ensemble |
|
|
For more information, see Ensemble Model Hyperparameter Options. |
| Optimizable Neural Network |
|
| For more information, see Neural Network Model Hyperparameter Options. |
Optimization Options
By default, the Classification Learner app performs hyperparameter tuning by using Bayesian optimization. The goal of Bayesian optimization, and optimization in general, is to find a point that minimizes an objective function. In the context of hyperparameter tuning in the app, a point is a set of hyperparameter values, and the objective function is the loss function, or the classification error. For more information on the basics of Bayesian optimization, see Bayesian Optimization Workflow.
You can specify how the hyperparameter tuning is performed. For example, you can change the optimization method to grid search or limit the training time. On the Learn tab, in the Options section, click Optimizer. The app opens a dialog box in which you can select optimization options.
After making your selections, click Save and Apply. Your selections affect all draft optimizable models in the Models pane and will be applied to new optimizable models that you create using the gallery in the Models section of the Learn tab.
To specify optimization options for a single optimizable model, open and edit the model summary before training the model. Click the model in the Models pane. The model Summary tab includes an editable Optimizer section.
This table describes the available optimization options and their default values.
| Option | Description |
|---|---|
| Optimizer | The optimizer values are:
|
| Acquisition function | When the app performs Bayesian optimization for hyperparameter tuning, it uses the acquisition function to determine the next set of hyperparameter values to try. The acquisition function values are:
For details on how these acquisition functions work in the context of Bayesian optimization, see Acquisition Function Types. |
| Iterations | Each iteration corresponds to a combination of
hyperparameter values that the app tries. When you use
Bayesian optimization or random search, specify a positive
integer that sets the number of iterations. The default
value is When you use grid search, the app ignores the Iterations value and evaluates the loss at every point in the entire grid. You can set a training time limit to stop the optimization process prematurely. |
| Training time limit | To set a training time limit, select this option and set the Maximum training time in seconds option. By default, the app does not have a training time limit. |
| Maximum training time in seconds | Set the training time limit in seconds as a positive real
number. The default value is 300. The run
time can exceed the training time limit because this limit does
not interrupt an iteration evaluation. |
| Number of grid divisions | When you use grid search, set a positive integer as the
number of values the app tries for each numeric hyperparameter.
The app ignores this value for categorical hyperparameters. The
default value is 10. |
Minimum Classification Error Plot
After specifying which model hyperparameters to optimize and setting any additional optimization options (optional), train your optimizable model. On the Learn tab, in the Train section, click Train All and select Train Selected. The app creates a Minimum Classification Error Plot that it updates as the optimization runs.
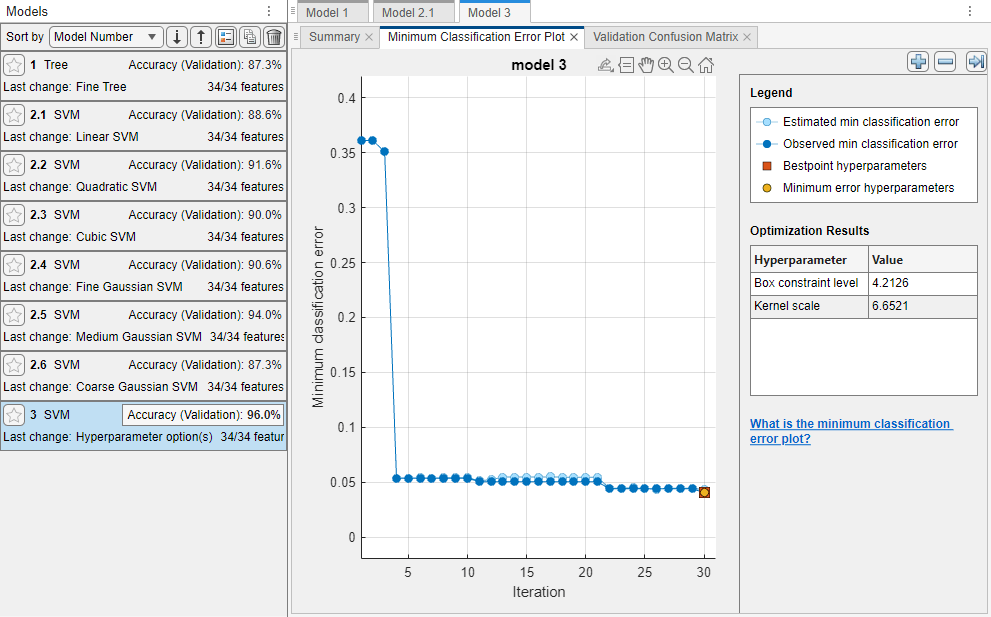
The minimum classification error plot displays the following information:
Estimated minimum classification error – Each light blue point corresponds to an estimate of the minimum classification error computed by the optimization process when considering all the sets of hyperparameter values tried so far, including the current iteration. For more information, see the
EstimatedObjectiveMinimumTraceproperty of theBayesianOptimizationobject.If you use grid search or random search to perform hyperparameter optimization, the app does not display these light blue points.
Observed minimum classification error – Each dark blue point corresponds to the observed minimum classification error computed so far by the optimization process. For example, at the third iteration, the dark blue point corresponds to the minimum of the classification error observed in the first, second, and third iterations.
Bestpoint hyperparameters – The red square indicates the iteration that corresponds to the optimized hyperparameters. You can find the values of the optimized hyperparameters listed in the upper right of the plot under Optimization Results.
The optimized hyperparameters do not always provide the observed minimum classification error. When the app performs hyperparameter tuning by using Bayesian optimization (see Optimization Options for a brief introduction), it chooses the set of hyperparameter values that minimizes an upper confidence interval of the classification error objective model, rather than the set that minimizes the classification error. For more information, see the
"Criterion","min-visited-upper-confidence-interval"name-value argument ofbestPoint.Minimum error hyperparameters – The yellow point indicates the iteration that corresponds to the hyperparameters that yield the observed minimum classification error.
For more information, see the
"Criterion","min-observed"name-value argument ofbestPoint.
Missing points in the plot correspond to NaN minimum
classification error values.
Optimization Results
When the app finishes tuning model hyperparameters, it returns a model trained with the optimized hyperparameter values (Bestpoint hyperparameters). The model metrics, displayed plots, and exported model correspond to this trained model with fixed hyperparameter values.
When you perform hyperparameter tuning using Bayesian optimization and you export
a trained optimizable model to the workspace as a structure, the structure includes
a BayesianOptimization object in the
HyperParameterOptimizationResult field. The object contains
the results at each optimization iteration, and the final best results of the
optimization performed in the app.
To inspect the optimization results of a trained optimizable model, select the model in the Models pane and look at the model Summary tab.

The model Summary tab includes these sections:
Training Results – Shows the performance of the optimizable model. See View Model Metrics in Summary Tab and Models Pane.
Model Hyperparameters – Displays the type of optimizable model and lists any fixed hyperparameter values
Optimized Hyperparameters – Lists the values of the optimized hyperparameters
Hyperparameter Search Range – Displays the search ranges for the optimized hyperparameters
Optimizer – Shows the selected optimizer options
When you generate MATLAB® code from a trained optimizable model, the generated code uses the fixed and optimized hyperparameter values of the model to train on new data. The generated code does not include the optimization process. For information on how to perform Bayesian optimization when you use a fit function, see Bayesian Optimization Using a Fit Function.
See Also
Topics
- Train Classifier Using Hyperparameter Optimization in Classification Learner App
- Bayesian Optimization Workflow
- Train Classification Models in Classification Learner App
- Start a Classification Learner or Regression Learner Session
- Choose Classifier Options in Classification Learner
- Visualize and Assess Classifier Performance in Classification Learner
- Export Classification Model to Predict New Data