report
Description
metricsTbl = report(metricsResults)metricsTbl. By default,
metricsTbl contains the bias metrics stored in the BiasMetrics
property of the fairnessMetrics
object metricsResults.
metricsTbl = report(metricsResults,Name=Value)metricsTbl by using the
BiasMetrics and GroupMetrics name-value
arguments, respectively.
Examples
Compute fairness metrics for predicted labels with respect to sensitive attributes by creating a fairnessMetrics object. Then, create a metrics table for specified fairness metrics by using the BiasMetrics and GroupMetrics name-value arguments of the report function.
Load the sample data census1994, which contains the training data adultdata and the test data adulttest. The data sets consist of demographic information from the US Census Bureau that can be used to predict whether an individual makes over $50,000 per year. Preview the first few rows of the training data set.
load census1994
head(adultdata) age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ _____________________ _________________ _____________ _____ ______ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
53 Private 2.3472e+05 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
28 Private 3.3841e+05 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
37 Private 2.8458e+05 Masters 14 Married-civ-spouse Exec-managerial Wife White Female 0 0 40 United-States <=50K
49 Private 1.6019e+05 9th 5 Married-spouse-absent Other-service Not-in-family Black Female 0 0 16 Jamaica <=50K
52 Self-emp-not-inc 2.0964e+05 HS-grad 9 Married-civ-spouse Exec-managerial Husband White Male 0 0 45 United-States >50K
Each row contains the demographic information for one adult. The information includes sensitive attributes, such as age, marital_status, relationship, race, and sex. The third column flnwgt contains observation weights, and the last column salary shows whether a person has a salary less than or equal to $50,000 per year (<=50K) or greater than $50,000 per year (>50K).
Train a classification tree using the training data set adultdata. Specify the response variable, predictor variables, and observation weights by using the variable names in the adultdata table.
predictorNames = ["capital_gain","capital_loss","education", ... "education_num","hours_per_week","occupation","workClass"]; Mdl = fitctree(adultdata,"salary", ... PredictorNames=predictorNames,Weights="fnlwgt");
Predict the test sample labels by using the trained tree Mdl.
adulttest.predictions = predict(Mdl,adulttest);
This example evaluates the fairness of the predicted labels with respect to age and marital status. Group the age variable into four bins.
ageGroups = ["Age<30","30<=Age<45","45<=Age<60","Age>=60"]; adulttest.age_group = discretize(adulttest.age, ... [min(adulttest.age) 30 45 60 max(adulttest.age)], ... categorical=ageGroups);
Compute fairness metrics for the predictions with respect to the age_group and marital_status variables by using fairnessMetrics.
metricsResults = fairnessMetrics(adulttest,"salary", ... SensitiveAttributeNames=["age_group","marital_status"], ... Predictions="predictions",ModelNames="Tree",Weights="fnlwgt");
fairnessMetrics computes metrics for all supported bias and group metrics. Display the names of the metrics stored in the BiasMetrics and GroupMetrics properties.
metricsResults.BiasMetrics.Properties.VariableNames(4:end)'
ans = 4×1 cell
{'StatisticalParityDifference' }
{'DisparateImpact' }
{'EqualOpportunityDifference' }
{'AverageAbsoluteOddsDifference'}
metricsResults.GroupMetrics.Properties.VariableNames(4:end)'
ans = 17×1 cell
{'GroupCount' }
{'GroupSizeRatio' }
{'TruePositives' }
{'TrueNegatives' }
{'FalsePositives' }
{'FalseNegatives' }
{'TruePositiveRate' }
{'TrueNegativeRate' }
{'FalsePositiveRate' }
{'FalseNegativeRate' }
{'FalseDiscoveryRate' }
{'FalseOmissionRate' }
{'PositivePredictiveValue' }
{'NegativePredictiveValue' }
{'RateOfPositivePredictions'}
{'RateOfNegativePredictions'}
{'Accuracy' }
Create a table containing fairness metrics by using the report function. Specify BiasMetrics as ["eod","aaod"] to include the equal opportunity difference (EOD) and average absolute odds difference (AAOD) metrics in the report table. fairnessMetrics computes the two metrics by using the true positive rates (TPR) and false positive rates (FPR). Specify GroupMetrics as ["tpr","fpr"] to include TPR and FPR values in the table.
metricsTbl = report(metricsResults, ... BiasMetrics=["eod","aaod"],GroupMetrics=["tpr","fpr"]);
Display the fairness metrics for the sensitive attribute age_group only.
metricsTbl(metricsTbl.SensitiveAttributeNames=="age_group",3:end)ans=4×5 table
Groups EqualOpportunityDifference AverageAbsoluteOddsDifference TruePositiveRate FalsePositiveRate
__________ __________________________ _____________________________ ________________ _________________
Age<30 -0.041319 0.044114 0.41333 0.041709
30<=Age<45 0 0 0.45465 0.088618
45<=Age<60 0.061495 0.031809 0.51614 0.086495
Age>=60 0.0060387 0.011955 0.46069 0.070746
Compute fairness metrics for true labels with respect to sensitive attributes by creating a fairnessMetrics object. Then, create a table with all supported fairness metrics by using the report function.
Read the sample file CreditRating_Historical.dat into a table. The predictor data consists of financial ratios and industry sector information for a list of corporate customers. The response variable consists of credit ratings assigned by a rating agency.
creditrating = readtable("CreditRating_Historical.dat");Because each value in the ID variable is a unique customer ID—that is, length(unique(creditrating.ID)) is equal to the number of observations in creditrating—the ID variable is a poor predictor. Remove the ID variable from the table, and convert the Industry variable to a categorical variable.
creditrating.ID = []; creditrating.Industry = categorical(creditrating.Industry);
In the Rating response variable, combine the AAA, AA, A, and BBB ratings into a category of "good" ratings, and the BB, B, and CCC ratings into a category of "poor" ratings.
Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A","BBB"],"good"); Rating = mergecats(Rating,["BB","B","CCC"],"poor"); creditrating.Rating = Rating;
Compute fairness metrics with respect to the sensitive attribute Industry for the labels in the Rating variable.
metricsResults = fairnessMetrics(creditrating,"Rating", ... SensitiveAttributeNames="Industry");
Display the bias metrics by using the report function. By default, the report function creates a table with all bias metrics.
report(metricsResults)
ans=12×4 table
SensitiveAttributeNames Groups StatisticalParityDifference DisparateImpact
_______________________ ______ ___________________________ _______________
Industry 1 0.077242 1.2632
Industry 2 0.078577 1.2678
Industry 3 0 1
Industry 4 0.088718 1.3023
Industry 5 0.055526 1.1892
Industry 6 -0.015004 0.94887
Industry 7 0.014489 1.0494
Industry 8 0.063476 1.2163
Industry 9 0.13948 1.4753
Industry 10 0.13865 1.4725
Industry 11 0.009886 1.0337
Industry 12 0.029338 1.1
Create a table with all supported bias and group metrics. Specify GroupMetrics as "all" to include all group metrics.
report(metricsResults,GroupMetrics="all")ans=12×6 table
SensitiveAttributeNames Groups StatisticalParityDifference DisparateImpact GroupCount GroupSizeRatio
_______________________ ______ ___________________________ _______________ __________ ______________
Industry 1 0.077242 1.2632 348 0.088505
Industry 2 0.078577 1.2678 336 0.085453
Industry 3 0 1 351 0.089268
Industry 4 0.088718 1.3023 314 0.079858
Industry 5 0.055526 1.1892 341 0.086724
Industry 6 -0.015004 0.94887 334 0.084944
Industry 7 0.014489 1.0494 315 0.080112
Industry 8 0.063476 1.2163 325 0.082655
Industry 9 0.13948 1.4753 328 0.083418
Industry 10 0.13865 1.4725 324 0.082401
Industry 11 0.009886 1.0337 300 0.076297
Industry 12 0.029338 1.1 316 0.080366
Train two classification models, and compare the model predictions by using fairness metrics.
Read the sample file CreditRating_Historical.dat into a table. The predictor data consists of financial ratios and industry sector information for a list of corporate customers. The response variable consists of credit ratings assigned by a rating agency.
creditrating = readtable("CreditRating_Historical.dat");Because each value in the ID variable is a unique customer ID—that is, length(unique(creditrating.ID)) is equal to the number of observations in creditrating—the ID variable is a poor predictor. Remove the ID variable from the table, and convert the Industry variable to a categorical variable.
creditrating.ID = []; creditrating.Industry = categorical(creditrating.Industry);
In the Rating response variable, combine the AAA, AA, A, and BBB ratings into a category of "good" ratings, and the BB, B, and CCC ratings into a category of "poor" ratings.
Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A","BBB"],"good"); Rating = mergecats(Rating,["BB","B","CCC"],"poor"); creditrating.Rating = Rating;
Train a support vector machine (SVM) model on the creditrating data. For better results, standardize the predictors before fitting the model. Use the trained model to predict labels and compute the misclassification rate for the training data set.
predictorNames = ["WC_TA","RE_TA","EBIT_TA","MVE_BVTD","S_TA"]; SVMMdl = fitcsvm(creditrating,"Rating", ... PredictorNames=predictorNames,Standardize=true); SVMPredictions = resubPredict(SVMMdl); resubLoss(SVMMdl)
ans = 0.0872
Train a generalized additive model (GAM).
GAMMdl = fitcgam(creditrating,"Rating", ... PredictorNames=predictorNames); GAMPredictions = resubPredict(GAMMdl); resubLoss(GAMMdl)
ans = 0.0542
GAMMdl achieves better accuracy on the training data set.
Compute fairness metrics with respect to the sensitive attribute Industry by using the model predictions for both models.
predictions = [SVMPredictions,GAMPredictions]; metricsResults = fairnessMetrics(creditrating,"Rating", ... SensitiveAttributeNames="Industry",Predictions=predictions, ... ModelNames=["SVM","GAM"]);
Display the bias metrics by using the report function.
report(metricsResults)
ans=48×5 table
Metrics SensitiveAttributeNames Groups SVM GAM
___________________________ _______________________ ______ _________ __________
StatisticalParityDifference Industry 1 -0.028441 0.0058208
StatisticalParityDifference Industry 2 -0.04014 0.0063339
StatisticalParityDifference Industry 3 0 0
StatisticalParityDifference Industry 4 -0.04905 -0.0043007
StatisticalParityDifference Industry 5 -0.015615 0.0041607
StatisticalParityDifference Industry 6 -0.03818 -0.024515
StatisticalParityDifference Industry 7 -0.01514 0.007326
StatisticalParityDifference Industry 8 0.0078632 0.036581
StatisticalParityDifference Industry 9 -0.013863 0.042266
StatisticalParityDifference Industry 10 0.0090218 0.050095
StatisticalParityDifference Industry 11 -0.004188 0.001453
StatisticalParityDifference Industry 12 -0.041572 -0.028589
DisparateImpact Industry 1 0.92261 1.017
DisparateImpact Industry 2 0.89078 1.0185
DisparateImpact Industry 3 1 1
DisparateImpact Industry 4 0.86654 0.98742
⋮
Among the bias metrics, compare the equal opportunity difference (EOD) values. Create a bar graph of the EOD values by using the plot function.
b = plot(metricsResults,"eod"); b(1).FaceAlpha = 0.2; b(2).FaceAlpha = 0.2; legend(Location="southwest")
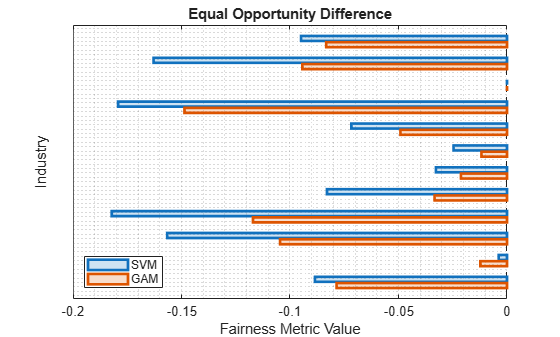
To better understand the distributions of EOD values, plot the values using box plots.
boxchart(metricsResults.BiasMetrics.EqualOpportunityDifference, ... GroupByColor=metricsResults.BiasMetrics.ModelNames) ax = gca; ax.XTick = []; ylabel("Equal Opportunity Difference") legend

The EOD values for GAM are closer to 0 compared to the values for SVM.