RegressionPartitionedLinear
Namespace: classreg.learning.partition
Superclasses: RegressionPartitionedModel
Cross-validated linear regression model for high-dimensional data
Description
RegressionPartitionedLinear is a set of linear
regression models trained on cross-validated folds. To obtain a cross-validated, linear
regression model, use fitrlinear and specify one of the
cross-validation options. You can estimate the predictive quality of the model, or how
well the linear regression model generalizes, using one or more of these
“kfold” methods: kfoldPredict and kfoldLoss.
Every “kfold” method uses models trained on in-fold observations to predict the response for out-of-fold observations. For example, suppose that you cross-validate using five folds. In this case, the software randomly assigns each observation into five roughly equally sized groups. The training fold contains four of the groups (that is, roughly 4/5 of the data) and the test fold contains the other group (that is, roughly 1/5 of the data). In this case, cross-validation proceeds as follows:
The software trains the first model (stored in
CVMdl.Trained{1}) using the observations in the last four groups and reserves the observations in the first group for validation.The software trains the second model (stored in
CVMdl.Trained{2}) using the observations in the first group and last three groups. The software reserves the observations in the second group for validation.The software proceeds in a similar fashion for the third through fifth models.
If you validate by calling kfoldPredict, it computes predictions for
the observations in group 1 using the first model, group 2 for the second model, and so
on. In short, the software estimates a response for every observation using the model
trained without that observation.
Note
Unlike other cross-validated, regression models, RegressionPartitionedLinear model objects do not store the predictor
data set.
Construction
CVMdl = fitrlinear(X,Y,Name,Value) creates a cross-validated,
linear regression model when Name is either
'CrossVal', 'CVPartition',
'Holdout', or 'KFold'. For more details, see
fitrlinear.
Properties
Methods
| kfoldLoss | Regression loss for observations not used in training |
| kfoldPredict | Predict responses for observations not used for training |
Copy Semantics
Value. To learn how value classes affect copy operations, see Copying Objects.
Examples
Create Cross-Validated Linear Regression Model
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Cross-validate a linear regression model. To increase execution speed, transpose the predictor data and specify that the observations are in columns.
X = X'; CVMdl = fitrlinear(X,Y,'CrossVal','on','ObservationsIn','columns');
CVMdl is a RegressionPartitionedLinear cross-validated model. Because fitrlinear implements 10-fold cross-validation by default, CVMdl.Trained contains a cell vector of ten RegressionLinear models. Each cell contains a linear regression model trained on nine folds, and then tested on the remaining fold.
Predict responses for out-of-fold observations and estimate the generalization error by passing CVMdl to kfoldPredict and kfoldLoss, respectively.
oofYHat = kfoldPredict(CVMdl); ge = kfoldLoss(CVMdl)
ge = 0.1748
The estimated, generalization, mean squared error is 0.1748.
Find Good Lasso Penalty Using Cross-Validation
To determine a good lasso-penalty strength for a linear regression model that uses least squares, implement 5-fold cross-validation.
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Create a set of 15 logarithmically-spaced regularization strengths from through .
Lambda = logspace(-5,-1,15);
Cross-validate the models. To increase execution speed, transpose the predictor data and specify that the observations are in columns. Optimize the objective function using SpaRSA.
X = X'; CVMdl = fitrlinear(X,Y,'ObservationsIn','columns','KFold',5,'Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numCLModels = numel(CVMdl.Trained)
numCLModels = 5
CVMdl is a RegressionPartitionedLinear model. Because fitrlinear implements 5-fold cross-validation, CVMdl contains 5 RegressionLinear models that the software trains on each fold.
Display the first trained linear regression model.
Mdl1 = CVMdl.Trained{1}Mdl1 =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000x15 double]
Bias: [-0.0049 -0.0049 -0.0049 -0.0049 -0.0049 -0.0048 -0.0044 -0.0037 -0.0030 -0.0031 -0.0033 -0.0036 -0.0041 -0.0051 -0.0071]
Lambda: [1.0000e-05 1.9307e-05 3.7276e-05 7.1969e-05 1.3895e-04 2.6827e-04 5.1795e-04 1.0000e-03 0.0019 0.0037 0.0072 0.0139 0.0268 0.0518 0.1000]
Learner: 'leastsquares'
Mdl1 is a RegressionLinear model object. fitrlinear constructed Mdl1 by training on the first four folds. Because Lambda is a sequence of regularization strengths, you can think of Mdl1 as 15 models, one for each regularization strength in Lambda.
Estimate the cross-validated MSE.
mse = kfoldLoss(CVMdl);
Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a regression model. For each regularization strength, train a linear regression model using the entire data set and the same options as when you cross-validated the models. Determine the number of nonzero coefficients per model.
Mdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Learner','leastsquares','Solver','sparsa','Regularization','lasso'); numNZCoeff = sum(Mdl.Beta~=0);
In the same figure, plot the cross-validated MSE and frequency of nonzero coefficients for each regularization strength. Plot all variables on the log scale.
figure [h,hL1,hL2] = plotyy(log10(Lambda),log10(mse),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} MSE') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') hold off
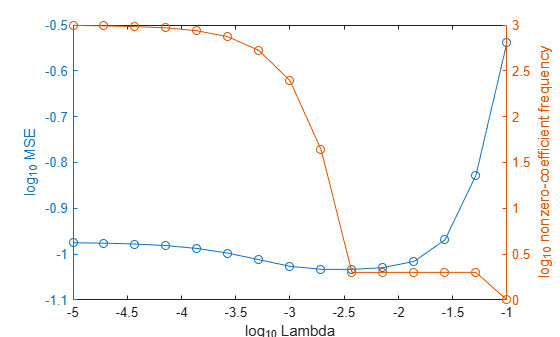
Choose the index of the regularization strength that balances predictor variable sparsity and low MSE (for example, Lambda(10)).
idxFinal = 10;
Extract the model with corresponding to the minimal MSE.
MdlFinal = selectModels(Mdl,idxFinal)
MdlFinal =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000x1 double]
Bias: -0.0050
Lambda: 0.0037
Learner: 'leastsquares'
idxNZCoeff = find(MdlFinal.Beta~=0)
idxNZCoeff = 2×1
100
200
EstCoeff = Mdl.Beta(idxNZCoeff)
EstCoeff = 2×1
1.0051
1.9965
MdlFinal is a RegressionLinear model with one regularization strength. The nonzero coefficients EstCoeff are close to the coefficients that simulated the data.
Extended Capabilities
Version History
Introduced in R2016aSee Also
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)