Get Started with PointPillars
PointPillars is a method for 3-D object detection using 2-D convolutional layers. PointPillars network has a learnable encoder that uses PointNets to learn a representation of point clouds organized in pillars (vertical columns). The network then runs a 2-D convolutional neural network (CNN) to produce network predictions, decodes the predictions, and generates 3-D bounding boxes for different object classes such as cars, trucks, and pedestrians.
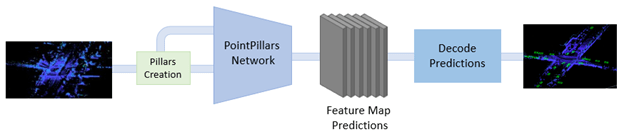
The PointPillars network has these main stages.
Use a feature encoder to convert a point cloud to a sparse pseudoimage.
Process the pseudoimage into a high-level representation using a 2-D convolution backbone.
Detect and regress 3-D bounding boxes using detection heads.
PointPillars Network
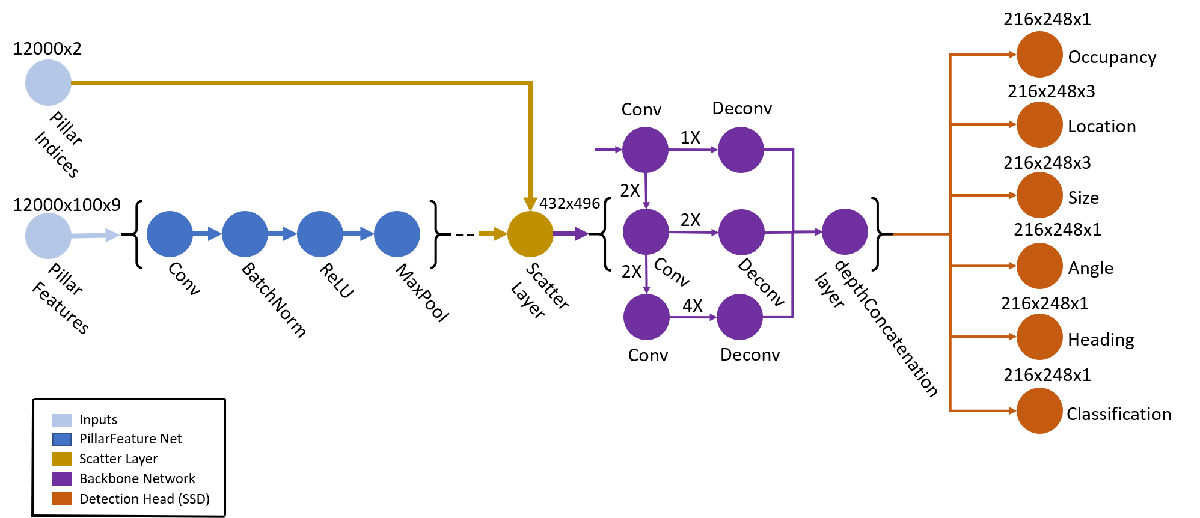
A PointPillars network requires two inputs: pillar indices as a P-by-2 and pillar features as a P-by-N-by-K matrix. P is the number of pillars in the network, N is the number of points per pillar, and K is the feature dimension.
The network begins with a feature encoder, which processes the points inside each pillar using a simplified PointNet. The PointNet applies a series of convolution, batch normalization, and rectified linear unit (ReLU) layers, and then a max pooling layer to extract one feature vector per pillar. A scatter layer at the end maps the extracted features into a 2-D grid using the pillar indices. This grid forms a pseudoimage, which the rest of the network uses.
Next, the network uses a 2‑D CNN backbone with two sub‑networks. The first sub‑network processes the pseudoimage through several convolutional blocks that gradually reduce the spatial resolution, allowing the network to learn high-level features. Each block applies convolution, batch normalization, and ReLU. The second sub‑network takes the outputs from these blocks and upsamples them so they all share the same spatial size. It upsamples each feature map using a transposed convolution, then applies batch normalization and ReLU. After bringing all feature maps to the same resolution, the network concatenates them to form a unified feature map.
Finally, the network passes the unified feature map through six detection heads with convolutional and sigmoid layers to predict occupancy, location, size, angle, heading, and class.
Create PointPillars Network
You can use the Deep Network Designer (Deep Learning Toolbox)
app to interactively create a PointPillars deep learning network. To programmatically create
a PointPillars network, use the pointPillarsObjectDetector object.
Transfer Learning
Transfer learning is a common deep learning technique in which you take a pretrained network as a starting point to train a network for a new task.
To perform transfer learning with a pretrained pointPillarsObjectDetector network, specify new object classes and their
corresponding anchor boxes. Then, train the network on a new data set.
Anchor boxes capture the scale and aspect ratio of specific object classes you want to detect, and are typically chosen based on object sizes in your training data set. For more information on anchor boxes, see Anchor Boxes for Object Detection.
Train PointPillars Object Detector and Perform Object Detection
Use the trainPointPillarsObjectDetector function to train a PointPillars network. To
perform object detection on a trained PointPillars network, use the detect function.
For more information on how to train a PointPillars network, see Lidar 3-D Object Detection Using PointPillars Deep Learning.
Code Generation
To learn how to generate CUDA® code for a PointPillars Network, see Code Generation for Lidar Object Detection Using PointPillars Deep Learning.
References
[1] Lang, Alex H., Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. “PointPillars: Fast Encoders for Object Detection From Point Cloud” In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12689–97. Long Beach, CA, USA: IEEE, 2019. https://doi.org/10.1109/CVPR.2019.01298.
[2] Hesai and Scale. PandaSet. Accessed September 18, 2025. https://pandaset.org/. The PandaSet data set is provided under the CC-BY-4.0 license.
[3] Xiao, Pengchuan, Zhenlei Shao, Steven Hao, et al. “PandaSet: Advanced Sensor Suite Dataset for Autonomous Driving.” 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), IEEE, September 19, 2021, 3095–101. https://doi.org/10.1109/ITSC48978.2021.9565009.
See Also
Apps
- Deep Network Designer (Deep Learning Toolbox) | Point Cloud Analyzer | Lidar Labeler
Objects
Functions
Topics
- Lidar 3-D Object Detection Using PointPillars Deep Learning
- Code Generation for Lidar Object Detection Using PointPillars Deep Learning
- Lane Detection in 3-D Lidar Point Cloud
- Unorganized to Organized Conversion of Point Clouds Using Spherical Projection
- Deep Learning in MATLAB (Deep Learning Toolbox)
- Deep Learning with Point Clouds