nssTrainingSGDM
Description
SGDM options set object to train an idNeuralStateSpace
network using nlssest.
Creation
Create an nssTrainingSGDM object using nssTrainingOptions
and specifying "sgdm" as input argument.
Properties
Solver used to update network parameters, returned as a string. This property is read-only.
Use nssTrainingOptions("adam"),
nssTrainingOptions("rmsprop"), or
nssTrainingOptions("lbfgs") to return an options set object for the
Adam, RMSProp, or L-BFGS solvers respectively. For more information on these algorithms,
see the Algorithms section of trainingOptions (Deep Learning Toolbox).
Contribution of the parameter update step of the previous iteration to the current
iteration of stochastic gradient descent with momentum, specified as a scalar from
0 to 1.
A value of 0 means no contribution from the previous step,
whereas a value of 1 means maximal contribution from the previous
step. The default value works well for most tasks.
For more information, see Stochastic Gradient Descent with Momentum (Deep Learning Toolbox).
Type of function used to calculate loss, specified as one of the following:
"MeanAbsoluteError"— uses the mean value of the absolute error."MeanSquaredError"— uses the mean value of the squared error.
Option to plot the value of the loss function during training, specified as one of the following:
true— plots the value of the loss function during training.false— does not plot the value of the loss function during training.
Constant coefficient applied to the regularization term added to the loss function, specified as a positive scalar.
The loss function with the regularization term is given by:
where t is the time variable, N is the size of the batch, ε is the sum of the reconstruction loss and autoencoder loss, θ is a concatenated vector of weights and biases of the neural network, and λ is the regularization constant that you can tune.
For more information, see Regularized Estimates of Model Parameters.
Learning rate used for training, specified as a positive scalar. If the learning rate is too small, then training can take a long time. If the learning rate is too large, then training might reach a suboptimal result or diverge.
Learning rate schedule, specified as "none" or
"piecewise".
| Learning Rate Schedule | Description | Plot |
|---|---|---|
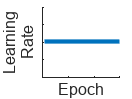
"none" | No learning rate schedule. This schedule keeps the learning rate constant. |
|
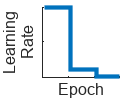
"piecewise" | Piecewise learning rate schedule. Every 10 epochs, this schedule drops the learn rate by a factor of 10. |
|
Number of epochs for dropping the learning rate, specified as a positive integer.
This option is valid only when the LearnRateSchedule training
option is "piecewise".
The software multiplies the global learning rate with the drop factor every time the
specified number of epochs passes. Specify the drop factor using the
LearnRateDropFactor training option.
Factor for dropping the learning rate, specified as a scalar from
0 to 1. This option is valid only when the
LearnRateSchedule training option is
"piecewise".
LearnRateDropFactor is a multiplicative factor to apply to the
learning rate every time a certain number of epochs passes. Specify the number of epochs
using the LearnRateDropPeriod training option.
Maximum number of epochs to use for training, specified as a positive integer. An epoch is the full pass of the training algorithm over the entire training set.
Coefficient applied to tune the reconstruction loss of an autoencoder, specified as a nonnegative scalar.
Reconstruction loss measures the difference between the original input
(x) and its reconstruction
(xr) after encoding and decoding. You
calculate this loss as the L2 norm of (x
-
xr) divided by the batch size
(N).
Number of samples in each frame or batch when segmenting data for model training, specified as a positive integer.
Fraction of the total number of frames or batches used in each iteration within a training epoch, specified as a positive scalar less than or equal to one.
If NumWindowFraction = 1, in each training epoch, you use all the
available data samples for estimation. This approach is called full-batch
learning.
If NumWindowFraction < 1, at the start of each training epoch,
the algorithm randomly shuffles all the batches. Then the algorithm divides these
batches into consecutive groups where each group contains a fraction of the total number
of batches as specified by NumWindowFraction. During the training
epoch, the algorithm iterates over these groups, using a different subset of data
samples in each iteration. This approach is called mini-batch or stochastic learning.
For mini-batch learning, loss in an epoch is approximated by taking the average of
losses in all iterations within the epoch.
For more information on full-batch and mini-batch learning, see Training Neural State-Space Models.
Number of samples in the overlap between successive frames when segmenting data for model training, specified as an integer. A negative integer indicates that certain data samples are skipped when creating the data frames.
The default value, "auto", implies that the size of the overlap
is 0.
ODE solver options to integrate continuous-time neural state-space systems,
specified as an nssDLODE45 object.
Use dot notation to access properties such as the following:
Solver— Solver type, set as"dlode45". This is a read-only property.InitialStepSize— Initial step size, specified as a positive scalar. If you do not specify an initial step size, then the solver bases the initial step size on the slope of the solution at the initial time point.MaxStepSize— Maximum step size, specified as a positive scalar. It is an upper bound on the size of any step taken by the solver. The default is one tenth of the difference between final and initial time.AbsoluteTolerance— Absolute tolerance, specified as a positive scalar. It is the largest allowable absolute error. Intuitively, when the solution approaches 0,AbsoluteToleranceis the threshold below which you do not worry about the accuracy of the solution since it is effectively 0.RelativeTolerance— Relative tolerance, specified as a positive scalar. This tolerance measures the error relative to the magnitude of each solution component. Intuitively, it controls the number of significant digits in a solution, (except when it is smaller than the absolute tolerance).
For more information, see odeset.
Input interpolation method, specified as one of the following:
'zoh'— uses zero-order hold interpolation method.'foh'— uses first-order hold interpolation method.'cubic'— uses cubic interpolation method.'makima'— uses modified Akima interpolation method.'pchip'— uses shape-preserving piecewise cubic interpolation method.'spline'— uses spline interpolation method.
This is the interpolation method used to interpolate the input when integrating
continuous-time neural state-space systems. For more information, see interpolation
methods in interp1.
Examples
Version History
Introduced in R2022bSee Also
Objects
Functions
nssTrainingOptions|nlssest|odeset|generateMATLABFunction|idNeuralStateSpace/evaluate|idNeuralStateSpace/linearize|sim|createMLPNetwork|setNetwork