Generate Code and Deploy Deep Neural Networks
Generate code for pretrained deep neural networks. You can accelerate the simulation of your algorithms in MATLAB® or Simulink® by using different execution environments. By using support packages, you can also generate and deploy C/C++, CUDA, and HDL code on target hardware.
Use Deep Learning Toolbox™ together with the Deep Learning Toolbox Model Compression Library support package to reduce the memory footprint and computational requirements of a deep neural network by quantizing the weights, biases, and activations of layers to reduced precision scaled integer data types. You can then generate C/C++, CUDA, or HDL code from these quantized networks.
Use MATLAB Coder™ or Simulink Coder together with Deep Learning Toolbox to generate MEX or standalone CPU code that runs on desktop or embedded targets. You can deploy the generated standalone code that uses the Intel® MKL-DNN library or the ARM® Compute library. Alternatively, you can generate generic CPU code that does not call third-party library functions.
Use GPU Coder™ together with Deep Learning Toolbox to generate CUDA MEX or standalone CUDA code that runs on desktop or embedded targets. You can deploy the generated standalone CUDA code that uses the CUDA deep neural network library (cuDNN), the TensorRT™ high performance inference library, or the ARM Compute library for Mali GPU.
Use Deep Learning HDL Toolbox™ together with Deep Learning Toolbox to generate HDL code for pretrained networks. You can deploy the generated HDL code on Intel and Xilinx® FPGA and SoC devices.

Code Generation Basics
- Networks and Layers Supported for Code Generation (MATLAB Coder)
- Supported Networks, Layers, and Classes (GPU Coder)
- Supported Networks, Boards, and Tools (Deep Learning HDL Toolbox)
- Code Generation for Deep Learning Networks
- Generate Generic C/C++ for Sequence-to-Sequence Deep Learning Simulink Models (Simulink Coder)
- Get Started with Deep Learning FPGA Deployment on Intel Arria 10 SoC (Deep Learning HDL Toolbox)
Categories
- Export Deep Neural Networks
Export networks to external deep learning platforms
- Quantization, Projection, and Pruning
Compress a deep neural network by performing quantization, projection, or pruning
- Deep Learning Code Generation from MATLAB Applications
Generate C/C++, GPU, and HDL code for deployment on desktop or embedded targets
- Deep Learning Code Generation from Simulink Applications
Generate C/C++ and GPU code for deployment on desktop or embedded targets
Related Information
- Deep Learning with MATLAB Coder (MATLAB Coder)
- Deep Learning with GPU Coder (GPU Coder)
- Get Started with Deep Learning HDL Toolbox (Deep Learning HDL Toolbox)
Featured Examples

Code Generation for Deep Learning Networks
Generate CUDA code for an image classification application that uses deep learning. It uses the codegen command to generate a MEX function that runs prediction by using image classification network, ResNet.

Code Generation for Detect Defects on Printed Circuit Boards Using YOLOX Network
Generate code for a You Only Look Once X (YOLOX) object detector that can detect, localize, and classify defects in printed circuit boards (PCBs).

Prune Image Classification Network Using Taylor Scores
Reduce the size of a deep neural network using Taylor pruning. By using the taylorPrunableNetwork function to remove convolution layer filters, you can reduce the overall network size and increase the inference speed.

Compress Neural Network Using Projection
Compress a neural network using projection and principal component analysis.
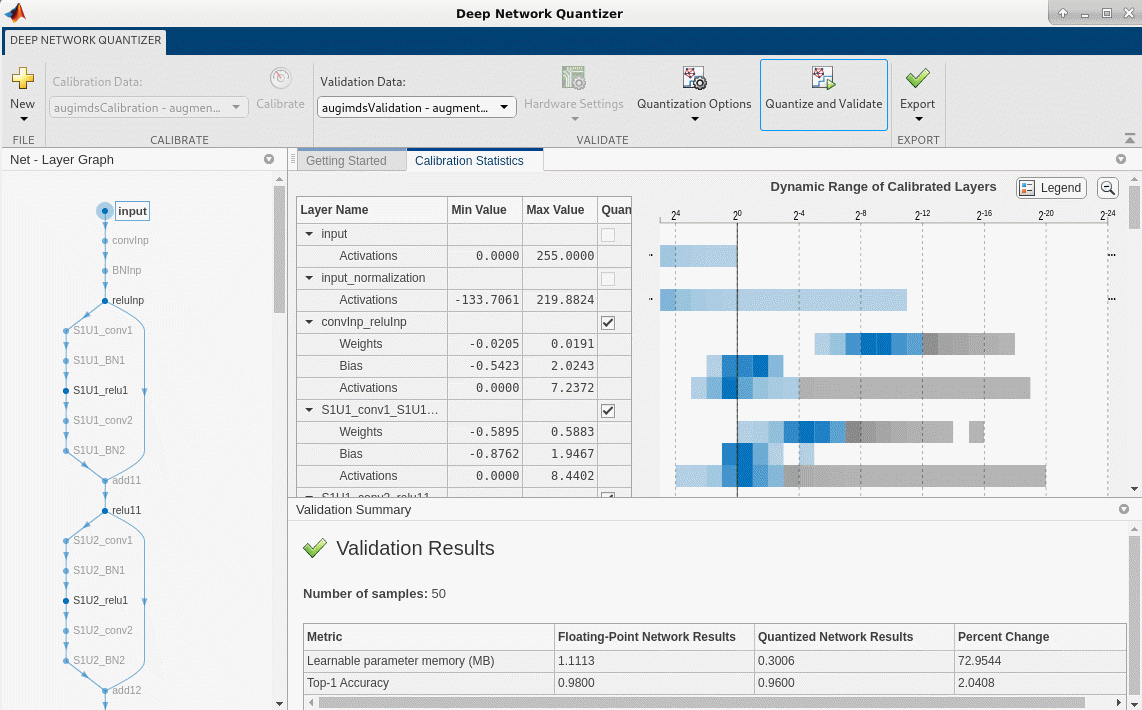
Quantize Residual Network Trained for Image Classification and Generate CUDA Code
Quantize the learnable parameters in the convolution layers of a deep learning neural network that has residual connections and has been trained for image classification with CIFAR-10 data.

Code Generation for Semantic Segmentation Network
Code generation for an image segmentation application that uses deep learning. It uses the codegen command to generate a MEX function that performs prediction on a DAG Network object for SegNet [1], a deep learning network for image segmentation.

Lane Detection Optimized with GPU Coder
Develop a deep learning lane detection application that runs on NVIDIA® GPUs.

Compress Image Classification Network for Deployment to Resource-Constrained Embedded Devices
Reduce the memory footprint and computation requirements of an image classification network for deployment on resource constrained embedded devices such as the Raspberry Pi™.