Getting Started with YOLO v2
The you-only-look-once (YOLO) v2 object detector uses a single stage object detection network. YOLO v2 is faster than two-stage deep learning object detectors, such as regions with convolutional neural networks (Faster R-CNNs).
The YOLO v2 model runs a deep learning CNN on an input image to produce network predictions. The object detector decodes the predictions and generates bounding boxes.

Predicting Objects in the Image
YOLO v2 uses anchor boxes to detect classes of objects in an image. For more details, see Anchor Boxes for Object Detection.The YOLO v2 predicts these three attributes for each anchor box:
Intersection over union (IoU) — Predicts the objectness score of each anchor box.
Anchor box offsets — Refine the anchor box position
Class probability — Predicts the class label assigned to each anchor box.
The figure shows predefined anchor boxes (the dotted lines) at each location in a feature map and the refined location after offsets are applied. Matched boxes with a class are in color.

Transfer Learning
With transfer learning, you can use a pretrained CNN as the feature extractor in a
YOLO v2 detection network. Use the yolov2Layers function to create a YOLO v2 detection network from any
pretrained CNN, for example MobileNet v2. For a list of pretrained
CNNs, see Pretrained Deep Neural Networks (Deep Learning Toolbox)
You can also design a custom model based on a pretrained image classification CNN. For more details, see Design a YOLO v2 Detection Network.
Design a YOLO v2 Detection Network
You can design a custom YOLO v2 model layer by layer. The model starts with a feature
extractor network, which can be initialized from a pretrained CNN or trained from
scratch. The detection subnetwork contains a series of Conv,
Batch norm, and ReLu layers, followed by the
transform and output layers, yolov2TransformLayer and yolov2OutputLayer objects, respectively. yolov2TransformLayer transforms the raw CNN output into a form required to
produce object detections. yolov2OutputLayer defines the anchor box parameters and implements the
loss function used to train the detector.

You can also use the Deep Network Designer (Deep Learning Toolbox) app to manually create a network. The designer incorporates Computer Vision Toolbox™ YOLO v2 features.
Design a YOLO v2 Detection Network with a Reorg Layer
The reorganization layer (created using the spaceToDepthLayer object) and the depth concatenation layer ( created
using the depthConcatenationLayer (Deep Learning Toolbox) object) are used to combine low-level and
high-level features. These layers improve detection by adding low-level image
information and improving detection accuracy for smaller objects. Typically, the
reorganization layer is attached to a layer within the feature extraction network
whose output feature map is larger than the feature extraction layer output.
Tip
Adjust the
"BlockSize"property of thespaceToDepthLayerobject such that its output size matches the input size of thedepthConcatenationLayer(Deep Learning Toolbox) object.To simplify designing a network, use the interactive Deep Network Designer (Deep Learning Toolbox) app and the
analyzeNetwork(Deep Learning Toolbox) function.
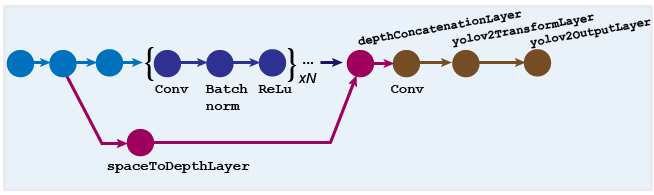
For more details on how to create this kind of network, see Create YOLO v2 Object Detection Network.
Train an Object Detector and Detect Objects with a YOLO v2 Model
To learn how to train an object detector by using the YOLO deep learning technique with a CNN, see the Object Detection Using YOLO v2 Deep Learning example.
Code Generation
To learn how to generate CUDA® code using the YOLO v2 object detector (created using the yolov2ObjectDetector object) see Code Generation for Object Detection by Using YOLO v2.
Label Training Data for Deep Learning
You can use the Image Labeler,
Video Labeler,
or Ground Truth Labeler (Automated Driving Toolbox) apps to interactively
label pixels and export label data for training. The apps can also be used to label
rectangular regions of interest (ROIs) for object detection, scene labels for image
classification, and pixels for semantic segmentation. To create training data from any
of the labelers exported ground truth object, you can use the objectDetectorTrainingData or pixelLabelTrainingData functions. For more details, see Training Data for Object Detection and Semantic Segmentation.
References
[1] Redmon, Joseph, and Ali Farhadi. “YOLO9000: Better, Faster, Stronger.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517–25. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690.
[2] Redmon, Joseph, Santosh Divvala, Ross Girshick, and Ali Farhadi. "You only look once: Unified, real-time object detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779–788. Las Vegas, NV: CVPR, 2016.
See Also
Apps
- Image Labeler | Ground Truth Labeler (Automated Driving Toolbox) | Video Labeler | Deep Network Designer (Deep Learning Toolbox)
Objects
yolov2TransformLayer|yolov2OutputLayer|spaceToDepthLayer|yolov2ObjectDetector|depthConcatenationLayer(Deep Learning Toolbox)
Functions
trainYOLOv2ObjectDetector|analyzeNetwork(Deep Learning Toolbox)
Related Examples
- Train Object Detector Using R-CNN Deep Learning
- Object Detection Using YOLO v2 Deep Learning
- Code Generation for Object Detection by Using YOLO v2
More About
- Anchor Boxes for Object Detection
- Getting Started with R-CNN, Fast R-CNN, and Faster R-CNN
- Deep Learning in MATLAB (Deep Learning Toolbox)
- Pretrained Deep Neural Networks (Deep Learning Toolbox)
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)