predict
Predict next observation, next reward, or episode termination given observation and action input data
Since R2022a
Syntax
Description
predNextObs = predict(tsnFcnAppx,obs,act)tsnFcnAppx and returns the predicted next observation
nextObs, given the current observation obs and
the action act.
predReward = predict(rwdFcnAppx,obs,act,nextObs)rwdFcnAppx and returns the predicted reward
predReward, given the current observation obs,
the action act, and the next observation
nextObs.
predIsDone = predict(idnFcnAppx,obs,act)idnFcnAppx and returns the predicted is-done status
predIsDone, given the current observation obs,
the action act, and the next observation
nextObs.
___ = predict(___,UseForward=
allows you to explicitly call a forward pass when computing gradients.useForward)
Examples
Create observation and action specification objects (or alternatively use getObservationInfo and getActionInfo to extract the specification objects from an environment). For this example, two observation channels carry vectors in a four- and two-dimensional space, respectively. The action is a continuous three-dimensional vector.
obsInfo = [
rlNumericSpec([4 1],UpperLimit=10*ones(4,1));
rlNumericSpec([1 2],UpperLimit=20*ones(1,2))
];
actInfo = rlNumericSpec([3 1]);Create a deep neural network to use as approximation model for the transition function approximator. For a continuous Gaussian transition function approximator, the network must have two output layers for each observation (one for the mean values the other for the standard deviation values).
Define each network path as an array of layer objects. Get the dimensions of the observation and action spaces from the environment specification objects, and specify a name for the input layers, so you can later explicitly associate them with the appropriate environment channel.
% Input path layers from first observation channel obs1Path = [ featureInputLayer( ... prod(obsInfo(1).Dimension), ... Name="obs1InLyr") fullyConnectedLayer(5,Name="obs1PathOutLyr") ]; % Input path layers from second observation channel obs2Path = [ featureInputLayer( ... prod(obsInfo(2).Dimension), ... Name="obs2InLyr") fullyConnectedLayer(5,Name="obs2PathOutLyr") ]; % Input path layers from action channel actPath = [ featureInputLayer( ... prod(actInfo(1).Dimension), ... Name="actInLyr") fullyConnectedLayer(5,Name="actPathOutLyr") ]; % Joint path layers, concatenate 3 inputs along first dimension jointPath = [ concatenationLayer(1,3,Name="concat") tanhLayer(Name="jntPathTahnLyr"); fullyConnectedLayer(10,Name="jntfc") ]; % Path layers for mean values of first predicted obs % Using tanh and scaling layers to scale range from (-1,1) to (-10,10) % Note that scale vector must be a column vector mean1Path = [ fullyConnectedLayer(prod(obsInfo(1).Dimension), ... Name="mean1PathInLyr"); tanhLayer(Name="mean1PathTahnLyr"); scalingLayer(Name="mean1OutLyr", ... Scale=obsInfo(1).UpperLimit) ]; % Path layers for standard deviations first predicted obs % Using softplus layer to make them non negative std1Path = [ fullyConnectedLayer(prod(obsInfo(1).Dimension), ... Name="std1PathInLyr"); softplusLayer(Name="std1OutLyr") ]; % Path layers for mean values of second predicted obs % Using tanh and scaling layers to scale range from (-1,1) to (-20,20) % Note that scale vector must be a column vector mean2Path = [ fullyConnectedLayer(prod(obsInfo(2).Dimension), ... Name="mean2PathInLyr"); tanhLayer(Name="mean2PathTahnLyr"); scalingLayer(Name="mean2OutLyr", ... Scale=obsInfo(2).UpperLimit(:)) ]; % Path layers for standard deviations second predicted obs % Using softplus layer to make them non negative std2Path = [ fullyConnectedLayer(prod(obsInfo(2).Dimension), ... Name="std2PathInLyr"); softplusLayer(Name="std2OutLyr") ]; % Assemble dlnetwork object. net = dlnetwork; net = addLayers(net,obs1Path); net = addLayers(net,obs2Path); net = addLayers(net,actPath); net = addLayers(net,jointPath); net = addLayers(net,mean1Path); net = addLayers(net,std1Path); net = addLayers(net,mean2Path); net = addLayers(net,std2Path); % Connect layers. net = connectLayers(net,"obs1PathOutLyr","concat/in1"); net = connectLayers(net,"obs2PathOutLyr","concat/in2"); net = connectLayers(net,"actPathOutLyr","concat/in3"); net = connectLayers(net,"jntfc","mean1PathInLyr/in"); net = connectLayers(net,"jntfc","std1PathInLyr/in"); net = connectLayers(net,"jntfc","mean2PathInLyr/in"); net = connectLayers(net,"jntfc","std2PathInLyr/in"); % Plot network. plot(net)
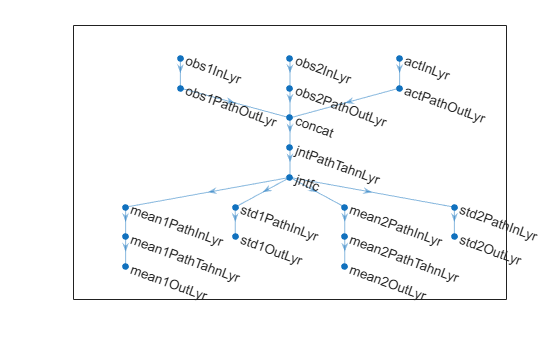
% Initialize network. net = initialize(net); % Display the number of weights. summary(net)
Initialized: true
Number of learnables: 352
Inputs:
1 'obs1InLyr' 4 features
2 'obs2InLyr' 2 features
3 'actInLyr' 3 features
Create a continuous Gaussian transition function approximator object, specifying the names of all the input and output layers.
tsnFcnAppx = rlContinuousGaussianTransitionFunction(... net,obsInfo,actInfo,... ObservationInputNames=["obs1InLyr","obs2InLyr"], ... ActionInputNames="actInLyr", ... NextObservationMeanOutputNames= ... ["mean1OutLyr","mean2OutLyr"], ... NextObservationStandardDeviationOutputNames= ... ["std1OutLyr","std2OutLyr"] );
Predict the next observation for a random observation and action.
predObs = predict(tsnFcnAppx, ... {rand(obsInfo(1).Dimension),rand(obsInfo(2).Dimension)}, ... {rand(actInfo(1).Dimension)})
predObs=1×2 cell array
{4×1 single} {[-19.2685 -1.1779]}
Each element of the resulting cell array represents the prediction for the corresponding observation channel.
To display the mean values and standard deviations of the Gaussian probability distribution for the predicted observations, use evaluate.
predDst = evaluate(tsnFcnAppx, ... {rand(obsInfo(1).Dimension), ... rand(obsInfo(2).Dimension), ... rand(actInfo(1).Dimension)})
predDst=1×4 cell array
{4×1 single} {[-16.6873 4.4006]} {4×1 single} {[0.7455 1.4318]}
The result is a cell array in which the first and second element represent the mean values for the predicted observations in the first and second channel, respectively. The third and fourth element represent the standard deviations for the predicted observations in the first and second channel, respectively.
Create an environment object and extract observation and action specifications. Alternatively, you can create specifications using rlNumericSpec and rlFiniteSetSpec.
env = rlPredefinedEnv("CartPole-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);To approximate the reward function, create a deep neural network. For this example, the network has two input layers, one for the current action and one for the next observations. The single output layer contains a scalar, which represents the value of the predicted reward.
Define each network path as an array of layer objects. Get the dimensions of the observation and action spaces from the environment specifications, and specify a name for the input layers, so you can later explicitly associate them with the appropriate environment channel.
actionPath = featureInputLayer( ... actInfo.Dimension(1), ... Name="action"); nextStatePath = featureInputLayer( ... obsInfo.Dimension(1), ... Name="nextState"); commonPath = [concatenationLayer(1,2,Name="concat") fullyConnectedLayer(64) reluLayer fullyConnectedLayer(64) reluLayer fullyConnectedLayer(64) reluLayer fullyConnectedLayer(1)];
Assemble dlnetwork object.
net = dlnetwork(); net = addLayers(net,nextStatePath); net = addLayers(net,actionPath); net = addLayers(net,commonPath);
Connect layers.
net = connectLayers(net,"nextState","concat/in1"); net = connectLayers(net,"action","concat/in2");
Plot network.
plot(net)
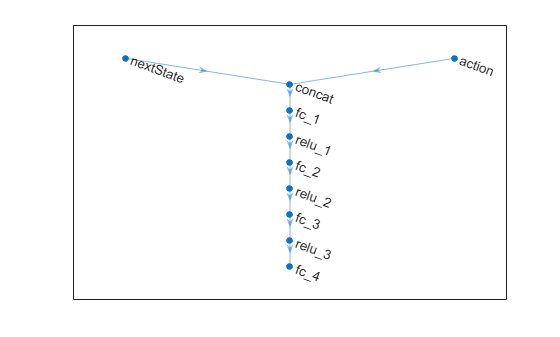
Initialize network and display the number of weights.
net = initialize(net); summary(net)
Initialized: true
Number of learnables: 8.7k
Inputs:
1 'nextState' 4 features
2 'action' 1 features
Create a deterministic transition function object.
rwdFcnAppx = rlContinuousDeterministicRewardFunction(... net,obsInfo,actInfo,... ActionInputNames="action", ... NextObservationInputNames="nextState");
Using this reward function object, you can predict the next reward value based on the current action and next observation. For example, predict the reward for a random action and next observation. Since, for this example, only the action and the next observation influence the reward, use an empty cell array for the current observation.
act = rand(actInfo.Dimension);
nxtobs = rand(obsInfo.Dimension);
reward = predict(rwdFcnAppx, {}, {act}, {nxtobs})reward = single
0.1034
To predict the reward, you can also use evaluate.
reward_ev = evaluate(rwdFcnAppx, {act,nxtobs} )reward_ev = 1×1 cell array
{[0.1034]}
Create an environment object and extract observation and action specifications. Alternatively, you can create specifications using rlNumericSpec and rlFiniteSetSpec.
env = rlPredefinedEnv("CartPole-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);To approximate the is-done function, use a deep neural network. The network has one input channel for the next observations. The single output channel is for the predicted termination signal.
Create the neural network as a vector of layer objects.
net = [
featureInputLayer( ...
obsInfo.Dimension(1), ...
Name="nextState")
fullyConnectedLayer(64)
reluLayer
fullyConnectedLayer(64)
reluLayer
fullyConnectedLayer(2)
softmaxLayer(Name="isdone")
];Convert to dlnetwork object.
net = dlnetwork(net);
Plot network.
plot(net)
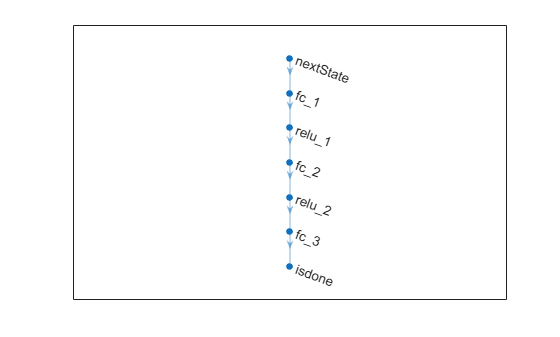
Initialize network and display the number of weights.
net = initialize(net); summary(net);
Initialized: true
Number of learnables: 4.6k
Inputs:
1 'nextState' 4 features
Create an is-done function approximator object.
isDoneFcnAppx = rlIsDoneFunction(... net,obsInfo,actInfo,... NextObservationInputNames="nextState");
Using this is-done function approximator object, you can predict the termination signal based on the next observation. For example, predict the termination signal for a random next observation. Since for this example the termination signal only depends on the next observation, use empty cell arrays for the current action and observation inputs.
nxtobs = rand(obsInfo.Dimension);
predIsDone = predict(isDoneFcnAppx,{},{},{nxtobs})predIsDone = 0
You can obtain the termination probability using evaluate.
predIsDoneProb = evaluate(isDoneFcnAppx,{nxtobs})predIsDoneProb = 1×1 cell array
{2×1 single}
predIsDoneProb{1}ans = 2×1 single column vector
0.5405
0.4595
The first number is the probability of obtaining a 0 (no termination predicted), the second one is the probability of obtaining a 1 (termination predicted).
Input Arguments
Output Arguments
Tips
When the elements of the cell array in inData are
dlarray objects, the elements of the cell array returned in
outData are also dlarray objects. This allows
predict to be used with automatic differentiation.
Specifically, you can write a custom loss function that directly uses
predict and dlgradient within
it, and then use dlfeval and
dlaccelerate with
your custom loss function. For an example, see Train Reinforcement Learning Policy Using Custom Training Loop and Custom Training Loop with Simulink Action Noise.
Version History
Introduced in R2022a
See Also
Functions
evaluate|runEpisode|update|rlOptimizer|syncParameters|getValue|getAction|getMaxQValue|getLearnableParameters|setLearnableParameters
Objects
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)