Pruning
Pruning reduces the number of learnable parameters in a neural network by removing the least important filters in convolutional layers.
If you can train your network using the trainnet function, then prune your network by using the
compressNetworkUsingTaylorPruning function. If you cannot
train your network using the trainnet function, then create a custom pruning loop by
using a taylorPrunableNetwork object instead.
For a detailed overview of the compression techniques available in Deep Learning Toolbox™ Model Compression Library, see Reduce Memory Footprint of Deep Neural Networks.
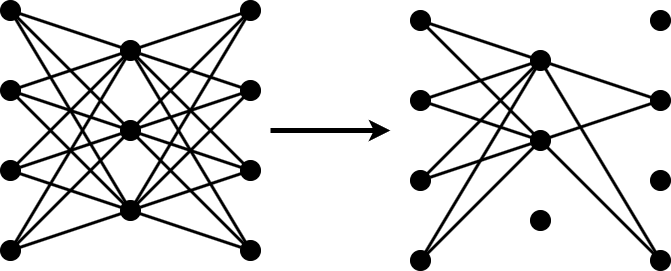
Functions
Topics
- Prune Neural Network with Memory Requirement
This example shows how to compress a neural network to a specific size using Taylor pruning. (Since R2026a)
- Prune Neural Network with Accuracy Requirement
This example shows how to compress a neural network with a minimum accuracy requirement using Taylor pruning. (Since R2026a)
- Prune Image Classification Network Using Taylor Scores
Reduce the size of a deep neural network using Taylor pruning.
- Prune Filters in a Detection Network Using Taylor Scores
Reduce network size and increase inference speed by pruning convolutional filters in a you only look once (YOLO) v3 object detection network.
- Prune and Quantize Convolutional Neural Network for Speech Recognition
Compress a convolutional neural network (CNN) to prepare it for deployment on an embedded system.
- Parameter Pruning and Quantization of Image Classification Network
Use parameter pruning and quantization to reduce network size.
Featured Examples

Prune Neural Network with Memory Requirement
Compress a neural network to a specific size using Taylor pruning.

Prune Neural Network with Accuracy Requirement
Compress a neural network with a minimum accuracy requirement using Taylor pruning.

Analyze and Compress 1-D Convolutional Neural Network
Analyze 1-D convolutional network for compression and compress it using Taylor pruning and projection.