lqr
Linear-Quadratic Regulator (LQR) design
Description
[
calculates the optimal gain matrix K,S,P] = lqr(sys,Q,R,N)K, the solution
S of the associated algebraic Riccati equation, and the closed-loop
poles P for the continuous-time or discrete-time state-space model
sys. Q and R are the weight
matrices for states and inputs, respectively. The cross term matrix N
is set to zero when omitted.
Examples
LQR Control for Inverted Pendulum Model
pendulumModelCart.mat contains the state-space model of an inverted pendulum on a cart where the outputs are the cart displacement x and the pendulum angle . The control input u is the horizontal force on the cart.
First, load the state-space model sys to the workspace.
load('pendulumCartModel.mat','sys')
Since the outputs are x and , and there is only one input, use Bryson's rule to determine Q and R.
Q = [1,0,0,0;... 0,0,0,0;... 0,0,1,0;... 0,0,0,0]; R = 1;
Find the gain matrix K using lqr. Since N is not specified, lqr sets N to 0.
[K,S,P] = lqr(sys,Q,R)
K = 1×4
-1.0000 -1.7559 16.9145 3.2274
S = 4×4
1.5346 1.2127 -3.2274 -0.6851
1.2127 1.5321 -4.5626 -0.9640
-3.2274 -4.5626 26.5487 5.2079
-0.6851 -0.9640 5.2079 1.0311
P = 4×1 complex
-0.8684 + 0.8523i
-0.8684 - 0.8523i
-5.4941 + 0.4564i
-5.4941 - 0.4564i
Although Bryson's rule usually provides satisfactory results, it is often just the starting point of a trial-and-error iterative design procedure to tune your closed-loop system response based on the design requirements.
LQR Control Using State-Space Matrices
aircraftPitchModel.mat contains the state-space matrices of an aircraft where the input is the elevator deflection angle and the output is the aircraft pitch angle .
For a step reference of 0.2 radians, consider the following design criteria:
Rise time less than 2 seconds
Settling time less than 10 seconds
Steady-state error less than 2%
Load the model data to the workspace.
load('aircraftPitchModel.mat')Define the state-cost weighted matrix Q and the control weighted matrix R. Generally, you can use Bryson's Rule to define your initial weighted matrices Q and R. For this example, consider the output vector C along with a scaling factor of 2 for matrix Q and choose R as 1. R is a scalar since the system has only one input.
R = 1
R = 1
Q1 = 2*C'*C
Q1 = 3×3
0 0 0
0 0 0
0 0 2
Compute the gain matrix using lqr.
[K1,S1,P1] = lqr(A,B,Q1,R);
Check the closed-loop step response with the generated gain matrix K1.
sys1 = ss(A-B*K1,B,C,D); step(sys1)
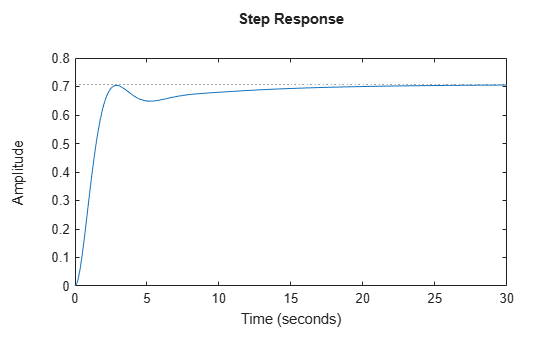
Since this response does not meet the design goals, increase the scaling factor to 25, compute the gain matrix K2, and check the closed-loop step response for gain matrix K2.
Q2 = 25*C'*C
Q2 = 3×3
0 0 0
0 0 0
0 0 25
[K2,S2,P2] = lqr(A,B,Q2,R); sys2 = ss(A-B*K2,B,C,D); step(sys2)
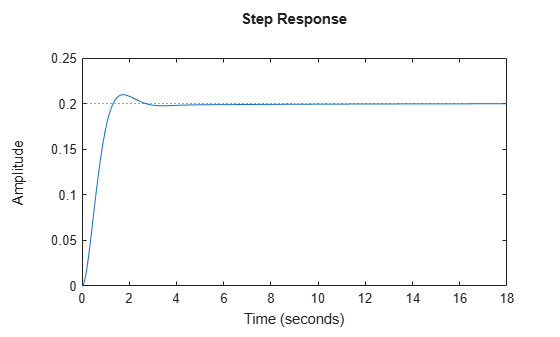
In the closed-loop step response plot, the rise time, settling time, and steady-state error meet the design goals.
Input Arguments
Output Arguments
Limitations
The input data must satisfy the following conditions:
The pair (A,B) must be stabilizable.
R must be positive definite.
must be positive semidefinite (equivalently, ).
must have no unobservable mode on the imaginary axis (or unit circle in discrete time).
Tips
lqrsupports descriptor models with nonsingularE. The outputSoflqris the solution of the algebraic Riccati equation for the equivalent explicit state-space model:
Algorithms
For continuous-time systems, lqr computes the state-feedback control that minimizes the quadratic cost function
subject to the system dynamics .
In addition to the state-feedback gain K, lqr
returns the solution S of the associated algebraic Riccati equation
and the closed-loop poles . The gain matrix K is derived from
S using
For discrete-time systems, lqr computes the state-feedback control that minimizes
subject to the system dynamics .
In all cases, when you omit the cross term matrix N,
lqr sets N to 0.
Version History
Introduced before R2006a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)