Using GPUs to Accelerate Turbo Coding Bit Error Rate Simulations
This example shows how you can use GPUs to dramatically accelerate bit error rate simulations. Turbo codes form the backbone of many modern communication systems. Because of the intense amount of computation involved in a Turbo decoder and the large number of trials required for a valid bit error rate simulation, the Turbo decoder is an ideal candidate for GPU acceleration. See the Parallel Concatenated Convolutional Coding: Turbo Codes example, which explains the data processing chain, for more information on Turbo codes.
You must have a Parallel Computing Toolbox™ license to run this example.
This example illustrates two approaches for GPU acceleration of the Turbo coding bit error rate simulation. The baseline system consists of random message generation, a Turbo encoder (comm.TurboEncoder), BPSK modulation using MATLAB® code, an AWGN channel (comm.AWGNChannel), BPSK demodulation using MATLAB code, a Turbo decoder (comm.TurboDecoder), and finally bit error rate computation (comm.ErrorRate).
Notice: Supply of this software does not convey a license nor imply any right to use any Turbo codes patents owned by France Telecom, Telediffusion de France and/or Groupe des Ecoles des Telecommunications except in connection with use of the software for the purposes of design, simulation and analysis. Code generated from Turbo codes technology in this software is not intended and/or suitable for implementation or incorporation in any commercial products.
Please contact France Telecom for information about Turbo Codes Licensing program at the following address: France Telecom R&D - PIV/TurboCodes 38-40, rue du General Leclerc 92794 Issy-les-Moulineaux Cedex 9, France.
Launch the TurboDecoderBERsim GUI
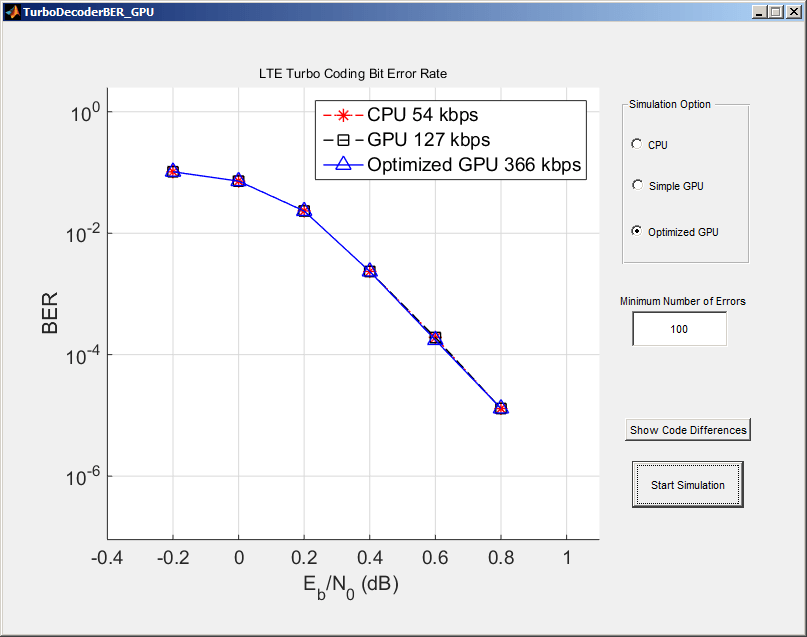
TurboDecoderBER_GPU

Overview of the Simulation
In the Simulation options button group select the CPU option for a CPU only simulation. The Simple GPU option makes very modest changes to the CPU version by replacing the CPU-based Turbo decoder (comm.TurboDecoder) with the GPU implementation (comm.gpu.TurboDecoder).
The Optimized GPU option uses the comm.gpu.TurboDecoder object, and runs the BPSK modulation and demodulation code on the GPU, using gpuArray overloads. This option also uses the GPU-accelerated AWGN channel. As a GPU computing best practice, multiple frames of data are processed in each call to a System object™.
You should process multiple frames of data together (or in parallel) whenever possible on the GPU. In general, the GPU has far more compute power than necessary to process one frame of data. Giving the GPU multiple frames of data to process in one function call more efficiently utilizes the GPU's processing power. To use multiframe processing, a random message is created that is an integer multiple of the frame size in length. The Turbo Encoder encodes this long, multiframe vector one frame at a time. (There is no real advantage to multiframe processing on the CPU, and the CPU Turbo encoder does not have a multiframe mode.) Data is then sent to the GPU using the gpuArray function. The rest of the data processing chain is written as before because there is no notion of framing for the channel, modulator, or demodulator. To have the Turbo Decoder run in multiframe mode, set the NumFrames property equal to the number of frames in the multiframe data vector (the default is one). The Turbo decoder decodes each frame independently and in parallel in a single call to the object (in particular, it does not treat the data as one long frame).
Code Differences
To see the changes in the original CPU source code necessary for the two GPU implementations, click on the appropriate GPU radio button (either Simple GPU or Optimized GPU) and then click the Show Code Differences button. This launches the comparison tool to view the changes necessary for GPU acceleration.
Error Rate Performance
You can plot the bit error rate curve for any of the three versions of the code. The number of errors required to plot a single point can be changed in the Minimum Number of Errors field. Enter the desired number of errors and click the Start Simulation button. Click the same button to stop the simulation early.
The bit error rate curves for the CPU and Simple GPU version match exactly. This indicates that the GPU version of the Turbo Decoder achieves exactly the same bit error rate as the CPU version at a much higher speed. In some cases, the Optimized GPU version may have a slightly different bit error rate because it runs multiple frames in parallel. Therefore, it may run a few frames more than necessary to pass the Minimum Number of Errors.
Results
As the simulation runs it displays number of message bits processed through the main simulation loop per second in the plot legend. This gives some measure of how quickly the simulation is running for each version of the code. Long simulations have been completed on a computer using an Intel® Xeon® X5650 processor and an NVIDIA® K20c GPU. Those simulations have shown that the Simple GPU is more than 2 times faster than the CPU version and that the Optimized GPU version is 6 times faster than the CPU version.
See Also
Topics
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)